General Object Detection Pipeline Tutorial¶
1. Introduction to General Object Detection Pipeline¶
Object detection aims to identify the categories and locations of multiple objects in images or videos by generating bounding boxes to mark these objects. Unlike simple image classification, object detection not only requires recognizing what objects are present in an image, such as people, cars, and animals, but also accurately determining the specific position of each object within the image, typically represented by rectangular boxes. This technology is widely used in autonomous driving, surveillance systems, smart photo albums, and other fields, relying on deep learning models (e.g., YOLO, Faster R-CNN) that can efficiently extract features and perform real-time detection, significantly enhancing the computer's ability to understand image content.
The inference time only includes the model inference time and does not include the time for pre- or post-processing.
| Model | Model Download Link | mAP(%) | GPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
Model Storage Size (MB) | Description |
|---|---|---|---|---|---|---|
| PicoDet-L | Inference Model/Training Model | 42.6 | 14.31 / 11.06 | 45.95 / 25.06 | 20.9 | PP-PicoDet is a lightweight object detection algorithm for full-size, wide-angle targets, considering the computational capacity of mobile devices. Compared to traditional object detection algorithms, PP-PicoDet has a smaller model size and lower computational complexity, achieving higher speed and lower latency while maintaining detection accuracy. |
| PicoDet-S | Inference Model/Training Model | 29.1 | 9.15 / 3.26 | 16.06 / 4.04 | 4.4 | |
| PP-YOLOE_plus-L | Inference Model/Training Model | 52.9 | 32.06 / 28.00 | 185.32 / 116.21 | 185.3 | PP-YOLOE_plus is an upgraded version of the high-precision cloud-edge integrated model PP-YOLOE, developed by Baidu's PaddlePaddle vision team. By using the large-scale Objects365 dataset and optimizing preprocessing, it significantly enhances the model's end-to-end inference speed. |
| PP-YOLOE_plus-S | Inference Model/Training Model | 43.7 | 11.43 / 7.52 | 60.16 / 26.94 | 28.3 | |
| RT-DETR-H | Inference Model/Training Model | 56.3 | 114.57 / 101.56 | 938.20 / 938.20 | 435.8 | RT-DETR is the first real-time end-to-end object detector. The model features an efficient hybrid encoder to meet both model performance and throughput requirements, efficiently handling multi-scale features, and proposes an accelerated and optimized query selection mechanism to optimize the dynamics of decoder queries. RT-DETR supports flexible end-to-end inference speeds by using different decoders. |
| RT-DETR-L | Inference Model/Training Model | 53.0 | 34.76 / 27.60 | 495.39 / 247.68 | 113.7 |
❗ The above list features the 6 core models that the image classification module primarily supports. In total, this module supports 37 models. The complete list of models is as follows:
👉Details of Model List
| Model | Model Download Link | mAP(%) | GPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
Model Storage Size (MB) | Description |
|---|---|---|---|---|---|---|
| Cascade-FasterRCNN-ResNet50-FPN | Inference Model/Training Model | 41.1 | 120.28 / 120.28 | - / 6514.61 | 245.4 | Cascade-FasterRCNN is an improved version of the Faster R-CNN object detection model. By coupling multiple detectors and optimizing detection results using different IoU thresholds, it addresses the mismatch problem between training and prediction stages, enhancing the accuracy of object detection. |
| Cascade-FasterRCNN-ResNet50-vd-SSLDv2-FPN | Inference Model/Training Model | 45.0 | 124.10 / 124.10 | - / 6709.52 | 246.2 | |
| CenterNet-DLA-34 | Inference Model/Training Model | 37.6 | 75.4 | CenterNet is an anchor-free object detection model that treats the keypoints of the object to be detected as a single point—the center point of its bounding box, and performs regression through these keypoints. | ||
| CenterNet-ResNet50 | Inference Model/Training Model | 38.9 | 319.7 | |||
| DETR-R50 | Inference Model/Training Model | 42.3 | 58.80 / 26.90 | 370.96 / 208.77 | 159.3 | DETR is a transformer-based object detection model proposed by Facebook. It achieves end-to-end object detection without the need for predefined anchor boxes or NMS post-processing strategies. |
| FasterRCNN-ResNet34-FPN | Inference Model/Training Model | 37.8 | 76.90 / 76.90 | - / 4136.79 | 137.5 | Faster R-CNN is a typical two-stage object detection model that first generates region proposals and then performs classification and regression on these proposals. Compared to its predecessors R-CNN and Fast R-CNN, Faster R-CNN's main improvement lies in the region proposal aspect, using a Region Proposal Network (RPN) to provide region proposals instead of traditional selective search. RPN is a Convolutional Neural Network (CNN) that shares convolutional features with the detection network, reducing the computational overhead of region proposals. |
| FasterRCNN-ResNet50-FPN | Inference Model/Training Model | 38.4 | 95.48 / 95.48 | - / 3693.90 | 148.1 | |
| FasterRCNN-ResNet50-vd-FPN | Inference Model/Training Model | 39.5 | 98.03 / 98.03 | - / 4278.36 | 148.1 | |
| FasterRCNN-ResNet50-vd-SSLDv2-FPN | Inference Model/Training Model | 41.4 | 99.23 / 99.23 | - / 4415.68 | 148.1 | |
| FasterRCNN-ResNet50 | Inference Model/Training Model | 36.7 | 129.10 / 129.10 | - / 3868.44 | 120.2 | |
| FasterRCNN-ResNet101-FPN | Inference Model/Training Model | 41.4 | 131.48 / 131.48 | - / 4380.00 | 216.3 | |
| FasterRCNN-ResNet101 | Inference Model/Training Model | 39.0 | 216.71 / 216.71 | - / 5376.45 | 188.1 | |
| FasterRCNN-ResNeXt101-vd-FPN | Inference Model/Training Model | 43.4 | 234.38 / 234.38 | - / 6154.61 | 360.6 | |
| FasterRCNN-Swin-Tiny-FPN | Inference Model/Training Model | 42.6 | 159.8 | |||
| FCOS-ResNet50 | Inference Model/Training Model | 39.6 | 101.02 / 34.42 | 752.15 / 752.15 | 124.2 | FCOS is an anchor-free object detection model that performs dense predictions. It uses the backbone of RetinaNet and directly regresses the width and height of the target object on the feature map, predicting the object's category and centerness (the degree of offset of pixels on the feature map from the object's center), which is eventually used as a weight to adjust the object score. |
| PicoDet-L | Inference Model/Training Model | 42.6 | 14.31 / 11.06 | 45.95 / 25.06 | 20.9 | PP-PicoDet is a lightweight object detection algorithm designed for full-size and wide-aspect-ratio targets, with a focus on mobile device computation. Compared to traditional object detection algorithms, PP-PicoDet boasts smaller model sizes and lower computational complexity, achieving higher speeds and lower latency while maintaining detection accuracy. |
| PicoDet-M | Inference Model/Training Model | 37.5 | 10.48 / 5.00 | 22.88 / 9.03 | 16.8 | |
| PicoDet-S | Inference Model/Training Model | 29.1 | 9.15 / 3.26 | 16.06 / 4.04 | 4.4 | |
| PicoDet-XS | Inference Model/Training Model | 26.2 | 9.54 / 3.52 | 17.96 / 5.38 | 5.7 | |
| PP-YOLOE_plus-L | Inference Model/Training Model | 52.9 | 32.06 / 28.00 | 185.32 / 116.21 | 185.3 | PP-YOLOE_plus is an iteratively optimized and upgraded version of PP-YOLOE, a high-precision cloud-edge integrated model developed by Baidu PaddlePaddle's Vision Team. By leveraging the large-scale Objects365 dataset and optimizing preprocessing, it significantly enhances the end-to-end inference speed of the model. |
| PP-YOLOE_plus-M | Inference Model/Training Model | 49.8 | 18.37 / 15.04 | 108.77 / 63.48 | 82.3 | |
| PP-YOLOE_plus-S | Inference Model/Training Model | 43.7 | 11.43 / 7.52 | 60.16 / 26.94 | 28.3 | |
| PP-YOLOE_plus-X | Inference Model/Training Model | 54.7 | 56.28 / 50.60 | 292.08 / 212.24 | 349.4 | |
| RT-DETR-H | Inference Model/Training Model | 56.3 | 114.57 / 101.56 | 938.20 / 938.20 | 435.8 | RT-DETR is the first real-time end-to-end object detector. It features an efficient hybrid encoder that balances model performance and throughput, efficiently processes multi-scale features, and introduces an accelerated and optimized query selection mechanism to dynamize decoder queries. RT-DETR supports flexible end-to-end inference speeds through the use of different decoders. |
| RT-DETR-L | Inference Model/Training Model | 53.0 | 34.76 / 27.60 | 495.39 / 247.68 | 113.7 | |
| RT-DETR-R18 | Inference Model/Training Model | 46.5 | 19.11 / 14.82 | 263.13 / 143.05 | 70.7 | |
| RT-DETR-R50 | Inference Model/Training Model | 53.1 | 41.11 / 10.12 | 536.20 / 482.86 | 149.1 | |
| RT-DETR-X | Inference Model/Training Model | 54.8 | 61.91 / 51.41 | 639.79 / 639.79 | 232.9 | |
| YOLOv3-DarkNet53 | Inference Model/Training Model | 39.1 | 39.62 / 35.54 | 166.57 / 136.34 | 219.7 | YOLOv3 is a real-time end-to-end object detector that utilizes a unique single Convolutional Neural Network (CNN) to frame the object detection problem as a regression task, enabling real-time detection. The model employs multi-scale detection to enhance performance across different object sizes. |
| YOLOv3-MobileNetV3 | Inference Model/Training Model | 31.4 | 16.54 / 6.21 | 64.37 / 45.55 | 83.8 | |
| YOLOv3-ResNet50_vd_DCN | Inference Model/Training Model | 40.6 | 31.64 / 26.72 | 226.75 / 226.75 | 163.0 | |
| YOLOX-L | Inference Model/Training Model | 50.1 | 49.68 / 45.03 | 232.52 / 156.24 | 192.5 | Building upon YOLOv3's framework, YOLOX significantly boosts detection performance in complex scenarios by incorporating Decoupled Head, Data Augmentation, Anchor Free, and SimOTA components. |
| YOLOX-M | Inference Model/Training Model | 46.9 | 43.46 / 29.52 | 147.64 / 80.06 | 90.0 | |
| YOLOX-N | Inference Model/Training Model | 26.1 | 42.94 / 17.79 | 64.15 / 7.19 | 3.4 | |
| YOLOX-S | Inference Model/Training Model | 40.4 | 46.53 / 29.34 | 98.37 / 35.02 | 32.0 | |
| YOLOX-T | Inference Model/Training Model | 32.9 | 31.81 / 18.91 | 55.34 / 11.63 | 18.1 | |
| YOLOX-X | Inference Model/Training Model | 51.8 | 84.06 / 77.28 | 390.38 / 272.88 | 351.5 | |
| Co-Deformable-DETR-R50 | Inference Model/Training Model | 49.7 | 259.62 / 259.62 | 32413.76 / 32413.76 | 184 | Co-DETR is an advanced end-to-end object detector. It is based on the DETR architecture and significantly enhances detection performance and training efficiency by introducing a collaborative hybrid assignment training strategy that combines traditional one-to-many label assignments with one-to-one matching in object detection tasks. |
| Co-Deformable-DETR-Swin-T | Inference Model/Training Model | 48.0(@640x640 input shape) | 120.17 / 120.17 | - / 15620.29 | 187 | |
| Co-DINO-R50 | Inference Model/Training Model | 52.0 | 1123.23 / 1123.23 | - / - | 186 | |
| Co-DINO-Swin-L | Inference Model/Training Model | 55.9 (@640x640 input shape) | - / - | - / - | 840 |
- Performance Test Environment
- Test Dataset:COCO2017 validation set.
- Hardware Configuration:
- GPU: NVIDIA Tesla T4
- CPU: Intel Xeon Gold 6271C @ 2.60GHz
- Software Environment:
- Ubuntu 20.04 / CUDA 11.8 / cuDNN 8.9 / TensorRT 8.6.1.6
- paddlepaddle 3.0.0 / paddlex 3.0.3
| Mode | GPU Configuration | CPU Configuration | Acceleration Technology Combination |
|---|---|---|---|
| Normal Mode | FP32 Precision / No TRT Acceleration | FP32 Precision / 8 Threads | PaddleInference |
| High-Performance Mode | Optimal combination of pre-selected precision types and acceleration strategies | FP32 Precision / 8 Threads | Pre-selected optimal backend (Paddle/OpenVINO/TRT, etc.) |
2. Quick Start¶
PaddleX's pre-trained model pipelines allow for quick experience of their effects. You can experience the effects of the General Object Detection Pipeline online or locally using command line or Python.
2.1 Online Experience¶
You can experience the General Object Detection Pipeline online using the demo images provided by the official source, for example:

If you are satisfied with the pipeline's performance, you can directly integrate and deploy it. If not, you can also use your private data to fine-tune the model within the pipeline.
2.2 Local Experience¶
Before using the general object detection pipeline locally, please ensure that you have completed the installation of the PaddleX wheel package according to the PaddleX Local Installation Guide. If you wish to selectively install dependencies, please refer to the relevant instructions in the installation guide. The dependency group corresponding to this pipeline is cv.
2.2.1 Command Line Experience¶
You can quickly experience the effect of the object detection pipeline with a single command. Use the test file, and replace --input with the local path for prediction.
{kind=link}
paddlex --pipeline object_detection \
--input general_object_detection_002.png \
--threshold 0.5 \
--save_path ./output/ \
--device gpu:0
For the description of parameters and interpretation of results, please refer to the parameter explanation and result interpretation in 2.2.2 Integration via Python Script. Supports specifying multiple devices simultaneously for parallel inference. For details, please refer to the documentation on pipeline parallel inference.
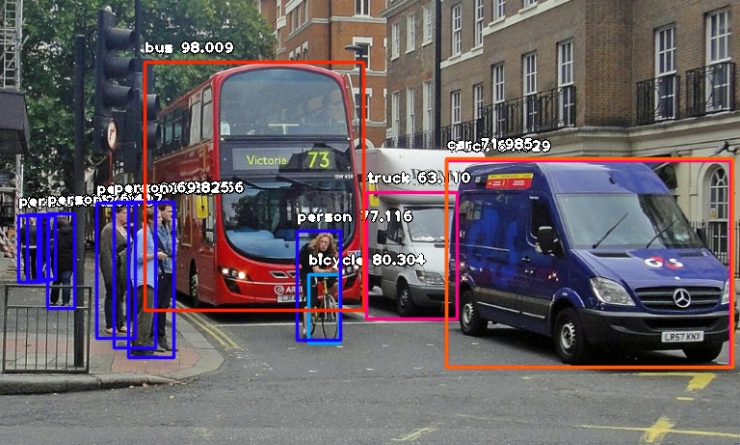
The visualization results are saved to save_path, as shown below:

2.2.2 Integration via Python Script¶
The command-line method described above allows you to quickly experience and view the results. However, in a project, code integration is often required. You can complete the fast inference of the pipeline with just a few lines of code as follows:
from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="object_detection")
output = pipeline.predict("general_object_detection_002.png", threshold=0.5)
for res in output:
res.print()
res.save_to_img("./output/")
res.save_to_json("./output/")
In the above Python script, the following steps are executed:
(1) Call the create_pipeline to instantiate the pipeline object. The specific parameter descriptions are as follows:
| Parameter | Parameter Description | Parameter Type | Default Value | |
|---|---|---|---|---|
pipeline |
The name of the pipeline or the path to the pipeline configuration file. If it is a pipeline name, it must be a pipeline supported by PaddleX. | str |
None |
|
config |
Specific configuration information for the pipeline (if set simultaneously with the pipeline, it takes precedence over the pipeline, and the pipeline name must match the pipeline).
|
dict[str, Any] |
None |
|
device |
The device for pipeline inference. It supports specifying the specific card number of GPU, such as "gpu:0", other hardware card numbers, such as "npu:0", or CPU as "cpu". Supports specifying multiple devices simultaneously for parallel inference. For details, please refer to Pipeline Parallel Inference. | str |
gpu:0 |
|
use_hpip |
Whether to enable the high-performance inference plugin. If set to None, the setting from the configuration file or config will be used. |
bool |
None | None |
hpi_config |
High-performance inference configuration | dict | None |
None | None |
(2) Call the predict() method of the general object detection pipeline object for inference prediction. This method returns a generator. Below are the parameters and their descriptions for the predict() method:
| Parameter | Parameter Description | Parameter Type | Options | Default Value |
|---|---|---|---|---|
input |
The data to be predicted. It supports multiple input types and is required. | Python Var|str|list |
|
None |
threshold |
The threshold used to filter out low-confidence prediction results; if not specified, the default configuration of the official PaddleX model will be used. | float/dict/None |
|
None |
{kind=link}
(3) Process the prediction results. Each prediction result is of dict type and supports operations such as printing, saving as an image, and saving as a json file:
| Method | Description | Parameter | Type | Explanation | Default Value |
|---|---|---|---|---|---|
print() |
Print the result to the terminal | format_json |
bool |
Whether to format the output content using JSON indentation |
True |
indent |
int |
Specify the indentation level to beautify the JSON data for better readability. This is only effective when format_json is True |
4 | ||
ensure_ascii |
bool |
Control whether non-ASCII characters are escaped to Unicode. If set to True, all non-ASCII characters will be escaped; False retains the original characters. This is only effective when format_json is True |
False |
||
save_to_json() |
Save the result as a JSON file | save_path |
str |
The file path for saving. If it is a directory, the saved file will have the same name as the input file type | None |
indent |
int |
Specify the indentation level to beautify the JSON data for better readability. This is only effective when format_json is True |
4 | ||
ensure_ascii |
bool |
Control whether non-ASCII characters are escaped to Unicode. If set to True, all non-ASCII characters will be escaped; False retains the original characters. This is only effective when format_json is True |
False |
||
save_to_img() |
Save the result as an image file | save_path |
str |
The file path for saving, supporting both directory and file paths | None |
- Calling the
print()method will print the following result to the terminal:
{'res': {'input_path': 'general_object_detection_002.png', 'page_index': None, 'boxes': [{'cls_id': 49, 'label': 'orange', 'score': 0.8188614249229431, 'coordinate': [661.3518, 93.05823, 870.75903, 305.93713]}, {'cls_id': 47, 'label': 'apple', 'score': 0.7745078206062317, 'coordinate': [76.80911, 274.74905, 330.5422, 520.0428]}, {'cls_id': 47, 'label': 'apple', 'score': 0.7271787524223328, 'coordinate': [285.32645, 94.3175, 469.73645, 297.40344]}, {'cls_id': 46, 'label': 'banana', 'score': 0.5576589703559875, 'coordinate': [310.8041, 361.43625, 685.1869, 712.59155]}, {'cls_id': 47, 'label': 'apple', 'score': 0.5490103363990784, 'coordinate': [764.6252, 285.76096, 924.8153, 440.92892]}, {'cls_id': 47, 'label': 'apple', 'score': 0.515821635723114, 'coordinate': [853.9831, 169.41423, 987.803, 303.58615]}, {'cls_id': 60, 'label': 'dining table', 'score': 0.514293372631073, 'coordinate': [0.53089714, 0.32445717, 1072.9534, 720]}, {'cls_id': 47, 'label': 'apple', 'score': 0.510750949382782, 'coordinate': [57.368027, 23.455347, 213.39601, 176.45612]}]}}
-
The meanings of the output result parameters are as follows:
input_path: Indicates the path of the input image.page_index: If the input is a PDF file, it indicates which page of the PDF it is; otherwise, it isNone.boxes: Information about the predicted bounding boxes, a list of dictionaries. Each dictionary represents a detected object and includes the following information:cls_id: The class ID, an integer.label: The class label, a string.score: The confidence score of the bounding box, a floating-point number.coordinate: The coordinates of the bounding box, a list of floating-point numbers in the format[xmin, ymin, xmax, ymax].
-
Calling the
save_to_json()method will save the above content to the specifiedsave_path. If specified as a directory, the saved path will besave_path/{your_img_basename}_res.json. If specified as a file, it will be saved directly to that file. Since JSON files do not support saving NumPy arrays, anynumpy.arraytype will be converted to a list format. -
Calling the
save_to_img()method will save the visualization results to the specifiedsave_path. If specified as a directory, the saved path will besave_path/{your_img_basename}_res.{your_img_extension}. If specified as a file, it will be saved directly to that file. (The pipeline usually contains many result images, so it is not recommended to specify a specific file path directly, otherwise multiple images will be overwritten and only the last image will be retained.) -
Additionally, it also supports obtaining the visualization image with results and prediction results through attributes, as follows:
| Attribute | Attribute Description |
|---|---|
json |
Get the prediction results in json format. |
img |
Get the visualization image in dict format. |
- The
jsonattribute retrieves the prediction result as a dictionary type of data, which is consistent with the content saved by calling thesave_to_json()method. - The
imgattribute returns the prediction result as a dictionary type of data. The key isres, and the corresponding value is anImage.Imageobject used for visualizing the object detection results.
The above Python script integration method uses the parameter settings in the PaddleX official configuration file by default. If you need to customize the configuration file, you can first execute the following command to get the official configuration file and save it in my_path:
If you have obtained the configuration file, you can customize the settings for the object detection pipeline. Simply modify the value of the pipeline parameter in the create_pipeline method to the path of your custom configuration file.
For example, if your custom configuration file is saved at ./my_path/object_detection.yaml, you just need to execute:
from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="./my_path/object_detection.yaml")
output = pipeline.predict("general_object_detection_002.png")
for res in output:
res.print()
res.save_to_img("./output/")
res.save_to_json("./output/")
Note: The parameters in the configuration file are initialization parameters for the pipeline. If you wish to change the initialization parameters for the general object detection pipeline, you can directly modify the parameters in the configuration file and load the configuration file for prediction.
3. Development Integration/Deployment¶
If the pipeline meets your requirements for inference speed and accuracy, you can proceed directly with development integration/deployment.
If you need to apply the pipeline directly in your Python project, you can refer to the example code in 2.2.2 Python Script Integration.
Additionally, PaddleX provides three other deployment methods, detailed as follows:
🚀 High-Performance Inference: In actual production environments, many applications have stringent standards for the performance metrics of deployment strategies (especially response speed) to ensure efficient system operation and smooth user experience. To this end, PaddleX offers a high-performance inference plugin aimed at deeply optimizing the performance of model inference and pre/post-processing, significantly speeding up the end-to-end process. For detailed high-performance inference processes, please refer to PaddleX High-Performance Inference Guide.
☁️ Service Deployment: Service deployment is a common form of deployment in actual production environments. By encapsulating the inference function as a service, clients can access these services via network requests to obtain inference results. PaddleX supports multiple pipeline service deployment schemes. For detailed pipeline service deployment processes, please refer to PaddleX Service Deployment Guide.
Below is the API reference for basic service deployment and multi-language service call examples:
API Reference
For the main operations provided by the service:
- The HTTP request method is POST.
- Both the request body and response body are JSON data (JSON objects).
- When the request is processed successfully, the response status code is
200, and the attributes of the response body are as follows:
| Name | Type | Meaning |
|---|---|---|
logId |
string |
The UUID of the request. |
errorCode |
integer |
Error code. Fixed as 0. |
errorMsg |
string |
Error message. Fixed as "Success". |
result |
object |
The result of the operation. |
- When the request is not processed successfully, the attributes of the response body are as follows:
| Name | Type | Meaning |
|---|---|---|
logId |
string |
The UUID of the request. |
errorCode |
integer |
Error code. Same as the response status code. |
errorMsg |
string |
Error message. |
The main operations provided by the service are as follows:
infer
Perform object detection on an image.
POST /object-detection
- The attributes of the request body are as follows:
| Name | Type | Meaning | Required |
|---|---|---|---|
image |
string |
The URL of an image file accessible by the server or the Base64-encoded content of the image file. | Yes |
threshold |
number | object | null |
Please refer to the description of the threshold parameter of the pipeline object's predict method. |
No |
visualize |
boolean | null |
Whether to return the final visualization image and intermediate images during the processing.
For example, adding the following setting to the pipeline config file: visualize parameter in the request.If neither the request body nor the configuration file is set (If visualize is set to null in the request and not defined in the configuration file), the image is returned by default.
|
No |
- When the request is processed successfully, the
resultof the response body has the following attributes:
| Name | Type | Meaning |
|---|---|---|
detectedObjects |
array |
Information about the detected objects, including their positions and categories. |
image |
string| null |
The result image of object detection. The image is in JPEG format and encoded in Base64. |
Each element in detectedObjects is an object with the following attributes:
| Name | Type | Meaning |
|---|---|---|
bbox |
array |
The position of the detected object. The elements in the array are the x-coordinate of the top-left corner, the y-coordinate of the top-left corner, the x-coordinate of the bottom-right corner, and the y-coordinate of the bottom-right corner. |
categoryName |
string |
The name of the target category. |
categoryId |
integer |
The category ID of the detected object. |
score |
number |
The confidence score of the detected object. |
An example of result is as follows:
{
"detectedObjects": [
{
"bbox": [
404.4967956542969,
90.15770721435547,
506.2465515136719,
285.4187316894531
],
"categoryId": 0,
"categoryName": "oranage",
"score": 0.7418514490127563
},
{
"bbox": [
155.33145141601562,
81.10954284667969,
199.71136474609375,
167.4235382080078
],
"categoryId": 1,
"categoryName": "banana",
"score": 0.7328268885612488
}
],
"image": "xxxxxx"
}
Multilingual API Call Examples
Python
import base64
import requests
API_URL = "http://localhost:8080/object-detection" # Service URL
image_path = "./demo.jpg"
output_image_path = "./out.jpg"
# Base64 encode the local image
with open(image_path, "rb") as file:
image_bytes = file.read()
image_data = base64.b64encode(image_bytes).decode("ascii")
payload = {"image": image_data} # Base64 encoded file content or image URL
# Call the API
response = requests.post(API_URL, json=payload)
# Process the API response
assert response.status_code == 200
result = response.json()["result"]
with open(output_image_path, "wb") as file:
file.write(base64.b64decode(result["image"]))
print(f"Output image saved at {output_image_path}")
print("\nDetected objects:")
print(result["detectedObjects"])
C++
#include <iostream>
#include "cpp-httplib/httplib.h" // https://github.com/Huiyicc/cpp-httplib
#include "nlohmann/json.hpp" // https://github.com/nlohmann/json
#include "base64.hpp" // https://github.com/tobiaslocker/base64
int main() {
httplib::Client client("localhost:8080");
const std::string imagePath = "./demo.jpg";
const std::string outputImagePath = "./out.jpg";
httplib::Headers headers = {
{"Content-Type", "application/json"}
};
// Base64 encode the local image
std::ifstream file(imagePath, std::ios::binary | std::ios::ate);
std::streamsize size = file.tellg();
file.seekg(0, std::ios::beg);
std::vector<char> buffer(size);
if (!file.read(buffer.data(), size)) {
std::cerr << "Error reading file." << std::endl;
return 1;
}
std::string bufferStr(reinterpret_cast<const char*>(buffer.data()), buffer.size());
std::string encodedImage = base64::to_base64(bufferStr);
nlohmann::json jsonObj;
jsonObj["image"] = encodedImage;
std::string body = jsonObj.dump();
// Call the API
auto response = client.Post("/object-detection", headers, body, "application/json");
// Process the API response
if (response && response->status == 200) {
nlohmann::json jsonResponse = nlohmann::json::parse(response->body);
auto result = jsonResponse["result"];
encodedImage = result["image"];
std::string decodedString = base64::from_base64(encodedImage);
std::vector<unsigned char> decodedImage(decodedString.begin(), decodedString.end());
std::ofstream outputImage(outPutImagePath, std::ios::binary | std::ios::out);
if (outputImage.is_open()) {
outputImage.write(reinterpret_cast<char*>(decodedImage.data()), decodedImage.size());
outputImage.close();
std::cout << "Output image saved at " << outPutImagePath << std::endl;
} else {
std::cerr << "Unable to open file for writing: " << outPutImagePath << std::endl;
}
auto detectedObjects = result["detectedObjects"];
std::cout << "\nDetected objects:" << std::endl;
for (const auto& obj : detectedObjects) {
std::cout << obj << std::endl;
}
} else {
std::cout << "Failed to send HTTP request." << std::endl;
return 1;
}
return 0;
}
C++
#include <iostream>
#include "cpp-httplib/httplib.h" // https://github.com/Huiyicc/cpp-httplib
#include "nlohmann/json.hpp" // https://github.com/nlohmann/json
#include "base64.hpp" // https://github.com/tobiaslocker/base64
int main() {
httplib::Client client("localhost:8080");
const std::string imagePath = "./demo.jpg";
const std::string outputImagePath = "./out.jpg";
httplib::Headers headers = {
{"Content-Type", "application/json"}
};
// Base64 encode the local image
std::ifstream file(imagePath, std::ios::binary | std::ios::ate);
std::streamsize size = file.tellg();
file.seekg(0, std::ios::beg);
std::vector<char> buffer(size);
if (!file.read(buffer.data(), size)) {
std::cerr << "Error reading file." << std::endl;
return 1;
}
std::string bufferStr(reinterpret_cast<const char*>(buffer.data()), buffer.size());
std::string encodedImage = base64::to_base64(bufferStr);
nlohmann::json jsonObj;
jsonObj["image"] = encodedImage;
std::string body = jsonObj.dump();
// Call the API
auto response = client.Post("/object-detection", headers, body, "application/json");
// Process the API response
if (response && response->status == 200) {
nlohmann::json jsonResponse = nlohmann::json::parse(response->body);
auto result = jsonResponse["result"];
encodedImage = result["image"];
std::string decodedString = base64::from_base64(encodedImage);
std::vector<unsigned char> decodedImage(decodedString.begin(), decodedString.end());
std::ofstream outputImage(outPutImagePath, std::ios::binary | std::ios::out);
if (outputImage.is_open()) {
outputImage.write(reinterpret_cast<char*>(decodedImage.data()), decodedImage.size());
outputImage.close();
std::cout << "Output image saved at " << outPutImagePath << std::endl;
} else {
std::cerr << "Unable to open file for writing: " << outPutImagePath << std::endl;
}
auto detectedObjects = result["detectedObjects"];
std::cout << "\nDetected objects:" << std::endl;
for (const auto& obj : detectedObjects) {
std::cout << obj << std::endl;
}
} else {
std::cout << "Failed to send HTTP request." << std::endl;
return 1;
}
return 0;
}
Java
import okhttp3.*;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.node.ObjectNode;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Base64;
public class Main {
public static void main(String[] args) throws IOException {
String API_URL = "http://localhost:8080/object-detection"; // Service URL
String imagePath = "./demo.jpg"; // Local image
String outputImagePath = "./out.jpg"; // Output image
// Encode the local image in Base64
File file = new File(imagePath);
byte[] fileContent = java.nio.file.Files.readAllBytes(file.toPath());
String imageData = Base64.getEncoder().encodeToString(fileContent);
ObjectMapper objectMapper = new ObjectMapper();
ObjectNode params = objectMapper.createObjectNode();
params.put("image", imageData); // Base64 encoded file content or image URL
// Create an OkHttpClient instance
OkHttpClient client = new OkHttpClient();
MediaType JSON = MediaType.Companion.get("application/json; charset=utf-8");
RequestBody body = RequestBody.Companion.create(params.toString(), JSON);
Request request = new Request.Builder()
.url(API_URL)
.post(body)
.build();
// Call the API and process the returned data
try (Response response = client.newCall(request).execute()) {
if (response.isSuccessful()) {
String responseBody = response.body().string();
JsonNode resultNode = objectMapper.readTree(responseBody);
JsonNode result = resultNode.get("result");
String base64Image = result.get("image").asText();
JsonNode detectedObjects = result.get("detectedObjects");
byte[] imageBytes = Base64.getDecoder().decode(base64Image);
try (FileOutputStream fos = new FileOutputStream(outputImagePath)) {
fos.write(imageBytes);
}
System.out.println("Output image saved at " + outputImagePath);
System.out.println("\nDetected objects: " + detectedObjects.toString());
} else {
System.err.println("Request failed with code: " + response.code());
}
}
}
}
Go
package main
import (
"bytes"
"encoding/base64"
"encoding/json"
"fmt"
"io/ioutil"
"net/http"
)
func main() {
API_URL := "http://localhost:8080/object-detection"
imagePath := "./demo.jpg"
outputImagePath := "./out.jpg"
// Encode the local image to Base64
imageBytes, err := ioutil.ReadFile(imagePath)
if err != nil {
fmt.Println("Error reading image file:", err)
return
}
imageData := base64.StdEncoding.EncodeToString(imageBytes)
payload := map[string]string{"image": imageData} // Base64-encoded file content or image URL
payloadBytes, err := json.Marshal(payload)
if err != nil {
fmt.Println("Error marshaling payload:", err)
return
}
// Call the API
client := &http.Client{}
req, err := http.NewRequest("POST", API_URL, bytes.NewBuffer(payloadBytes))
if err != nil {
fmt.Println("Error creating request:", err)
return
}
res, err := client.Do(req)
if err != nil {
fmt.Println("Error sending request:", err)
return
}
defer res.Body.Close()
// Process the API response data
body, err := ioutil.ReadAll(res.Body)
if err != nil {
fmt.Println("Error reading response body:", err)
return
}
type Response struct {
Result struct {
Image string `json:"image"`
DetectedObjects []map[string]interface{} `json:"detectedObjects"`
} `json:"result"`
}
var respData Response
err = json.Unmarshal([]byte(string(body)), &respData)
if err != nil {
fmt.Println("Error unmarshaling response body:", err)
return
}
outputImageData, err := base64.StdEncoding.DecodeString(respData.Result.Image)
if err != nil {
fmt.Println("Error decoding base64 image data:", err)
return
}
err = ioutil.WriteFile(outputImagePath, outputImageData, 0644)
if err != nil {
fmt.Println("Error writing image to file:", err)
return
}
fmt.Printf("Image saved at %s.jpg\n", outputImagePath)
fmt.Println("\nDetected objects:")
for _, obj := range respData.Result.DetectedObjects {
fmt.Println(obj)
}
}
C#
using System;
using System.IO;
using System.Net.Http;
using System.Net.Http.Headers;
using System.Text;
using System.Threading.Tasks;
using Newtonsoft.Json.Linq;
class Program
{
static readonly string API_URL = "http://localhost:8080/object-detection";
static readonly string imagePath = "./demo.jpg";
static readonly string outputImagePath = "./out.jpg";
static async Task Main(string[] args)
{
var httpClient = new HttpClient();
// Base64 encode the local image
byte[] imageBytes = File.ReadAllBytes(imagePath);
string image_data = Convert.ToBase64String(imageBytes);
var payload = new JObject{ { "image", image_data } }; // Base64 encoded file content or image URL
var content = new StringContent(payload.ToString(), Encoding.UTF8, "application/json");
// Call the API
HttpResponseMessage response = await httpClient.PostAsync(API_URL, content);
response.EnsureSuccessStatusCode();
// Process the API response
string responseBody = await response.Content.ReadAsStringAsync();
JObject jsonResponse = JObject.Parse(responseBody);
string base64Image = jsonResponse["result"]["image"].ToString();
byte[] outputImageBytes = Convert.FromBase64String(base64Image);
File.WriteAllBytes(outputImagePath, outputImageBytes);
Console.WriteLine($"Output image saved at {outputImagePath}");
Console.WriteLine("\nDetected objects:");
Console.WriteLine(jsonResponse["result"]["detectedObjects"].ToString());
}
}
Node.js
const axios = require('axios');
const fs = require('fs');
const API_URL = 'http://localhost:8080/object-detection';
const imagePath = './demo.jpg';
const outputImagePath = "./out.jpg";
let config = {
method: 'POST',
maxBodyLength: Infinity,
url: API_URL,
data: JSON.stringify({
'image': encodeImageToBase64(imagePath) // Base64 encoded file content or image URL
})
};
// Encode a local image to Base64
function encodeImageToBase64(filePath) {
const bitmap = fs.readFileSync(filePath);
return Buffer.from(bitmap).toString('base64');
}
// Call the API
axios.request(config)
.then((response) => {
// Process the data returned by the API
const result = response.data["result"];
const imageBuffer = Buffer.from(result["image"], 'base64');
fs.writeFile(outputImagePath, imageBuffer, (err) => {
if (err) throw err;
console.log(`Output image saved at ${outputImagePath}`);
});
console.log("\nDetected objects:");
console.log(result["detectedObjects"]);
})
.catch((error) => {
console.log(error);
});
PHP
<?php
$API_URL = "http://localhost:8080/object-detection"; // Service URL
$image_path = "./demo.jpg";
$output_image_path = "./out.jpg";
// Encode the local image in Base64
$image_data = base64_encode(file_get_contents($image_path));
$payload = array("image" => $image_data); // Base64 encoded file content or image URL
// Call the API
$ch = curl_init($API_URL);
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_POSTFIELDS, json_encode($payload));
curl_setopt($ch, CURLOPT_HTTPHEADER, array('Content-Type: application/json'));
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$response = curl_exec($ch);
curl_close($ch);
// Process the returned data
$result = json_decode($response, true)["result"];
file_put_contents($output_image_path, base64_decode($result["image"]));
echo "Output image saved at " . $output_image_path . "\n";
echo "\nDetected objects:\n";
print_r($result["detectedObjects"]);
?>
📱 On-Device Deployment: Edge deployment is a method where computation and data processing functions are placed on the user's device itself, allowing the device to process data directly without relying on remote servers. PaddleX supports deploying models on edge devices such as Android. For detailed edge deployment processes, please refer to the PaddleX On-Device Deployment Guide. You can choose the appropriate method to deploy the model pipeline based on your needs for subsequent AI application integration.
4. Custom Development¶
If the default model weights provided by the general object detection pipeline do not meet your accuracy or speed requirements in your scenario, you can try further fine-tuning the existing model using your own specific domain or application scenario data to improve the recognition performance of the general object detection pipeline in your scenario.
4.1 Model Fine-Tuning¶
Since the general object detection pipeline includes an object detection module, if the performance of the model pipeline is not as expected, you need to refer to the Custom Development section in the Object Detection Module Development Tutorial to fine-tune the object detection model using your private dataset.
4.2 Model Application¶
After completing the fine-tuning training with your private dataset, you will obtain a local model weight file.
If you need to use the fine-tuned model weights, simply modify the pipeline configuration file by replacing the local path of the fine-tuned model weights in the corresponding position in the configuration file:
pipeline_name: object_detection
SubModules:
ObjectDetection:
module_name: object_detection
model_name: PicoDet-S
model_dir: null # Can be modified to the local path of the fine-tuned model
batch_size: 1
img_size: null
threshold: null
Subsequently, you can load the modified pipeline configuration file by referring to the command-line method or the Python script method in the local experience.
5. Multi-Hardware Support¶
PaddleX supports a variety of mainstream hardware devices, including NVIDIA GPU, Kunlunxin XPU, Ascend NPU, and Cambricon MLU. Simply modify the --device parameter to seamlessly switch between different hardware devices.
For example, to perform fast inference on the object detection pipeline using Ascend NPU:
paddlex --pipeline object_detection \
--input general_object_detection_002.png \
--threshold 0.5 \
--save_path ./output/ \
--device npu:0
If you want to use the general object detection pipeline on a wider range of hardware, please refer to the PaddleX Multi-Device Usage Guide.