PaddleX Time Series Classification Task Data Annotation Tutorial¶
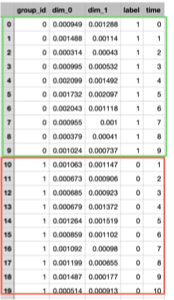
When annotating time series classification data, based on the collected real-world data, clearly define the classification objectives of the time series data and establish corresponding classification labels. In the csv file, set a group_id column to represent samples, where the same group_id indicates that the data points belong to the same sample. For example, in stock price prediction, labels might be "Rise" (0), "Flat" (1), or "Fall" (2). For a time series that exhibits an "upward" trend over a period, it can be considered as one sample (group), where each time point in this series shares the same group_id, and the label column is set to 0. Similarly, for a time series that exhibits a "downward" trend, it forms another sample (group), where each time point shares the same group_id, and the label column is set to 2. As shown in the figure below, the green box represents one sample (group_id=0) with a label of 1, while the red box represents another time series classification sample (group_id=1) with a label of 0. If there are n samples, you can set group_id=0,...,n-1; each sample has a length (time=0,...,9) of 10, and the feature dimensions (dim_0, dim_1) are 2.