PaddleX Serving Guide¶
Serving is a common deployment strategy in real-world production environments. By encapsulating inference functions into services, clients can access these services via network requests to obtain inference results. PaddleX supports various solutions for serving pipelines.
Demonstration of PaddleX pipeline serving:
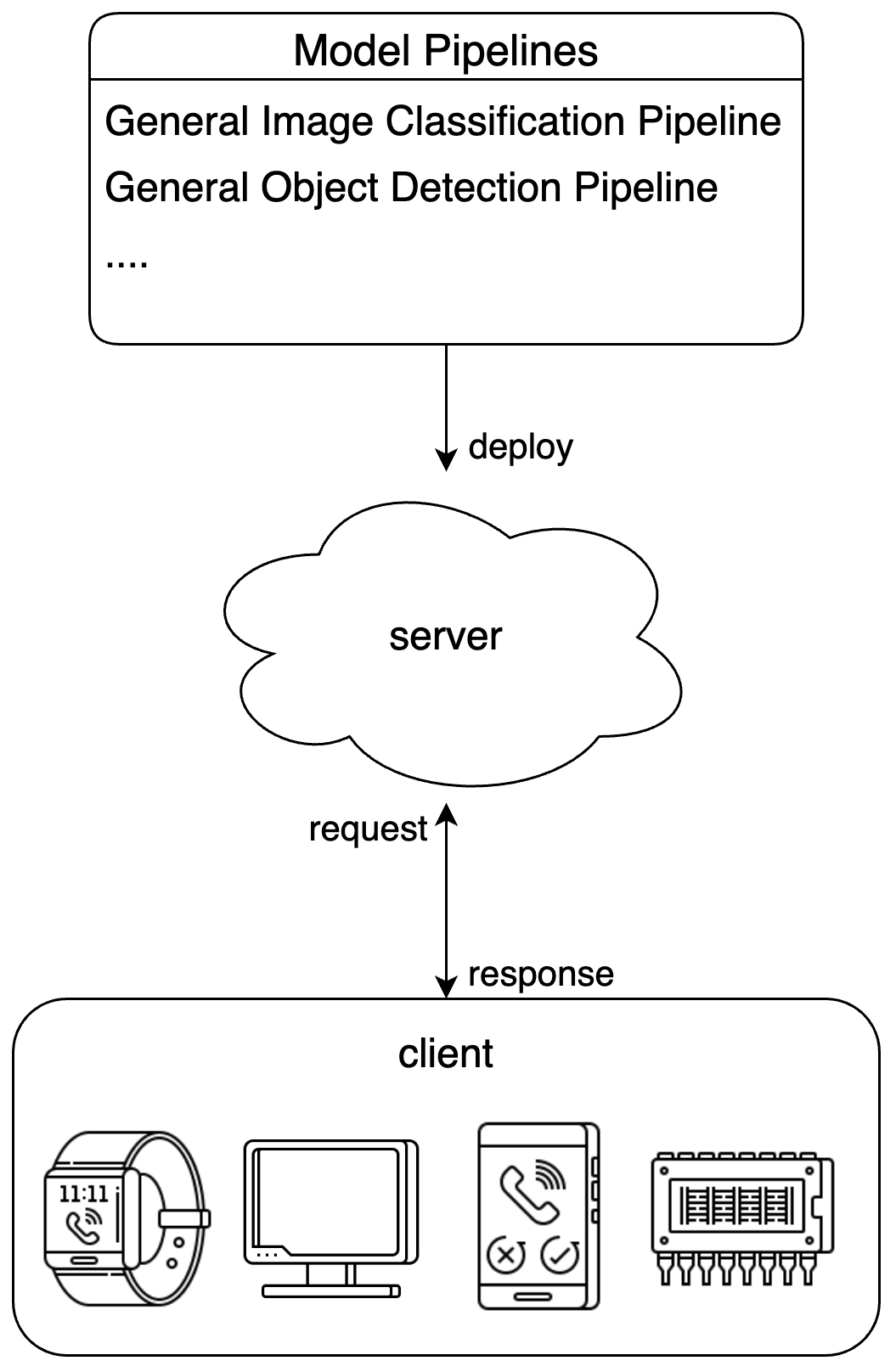
To address different user needs, PaddleX offers multiple pipeline serving solutions:
- Basic serving: A simple and easy-to-use serving solution with low development costs.
- High-stability serving: Built on NVIDIA Triton Inference Server. Compared to basic serving, this solution offers higher stability and allows users to adjust configurations to optimize performance.
It is recommended to first use the basic serving solution for quick verification, and then evaluate whether to try more complex solutions based on actual needs.
Note
- PaddleX serves pipelines rather than modules.
1. Basic Serving¶
1.1 Install the Serving Plugin¶
Execute the following command to install the serving plugin:
1.2 Run the Server¶
Run the server via PaddleX CLI:
paddlex --serve --pipeline {pipeline name or path to pipeline config file} [{other commandline options}]
Take the general image classification pipeline as an example:
You can see the following information:
INFO: Started server process [63108]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
--pipeline can be specified as the official pipeline name or the path to a local pipeline configuration file. PaddleX builds the pipeline and deploys it as a service. If you need to adjust configurations (such as model paths, batch size, device for deployment, etc.), please refer to the "Model Application" section in General Image Classification Pipeline Tutorial.
The command-line options related to serving are as follows:
| Name | Description |
|---|---|
--pipeline |
Pipeline name or path to the pipeline configuration file. |
--device |
Device for pipeline deployment. By default the GPU will be used when it is available; otherwise, the CPU will be used. |
--host |
Hostname or IP address the server binds to. Defaults to 0.0.0.0. |
--port |
Port number the server listens on. Defaults to 8080. |
--use_hpip |
If specified, enables the high-performance inference plugin. |
--hpi_config |
High-performance inference configuration |
In application scenarios where strict requirements are placed on service response time, the PaddleX high-performance inference plugin can be used to accelerate model inference and pre/post-processing, thereby reducing response time and increasing throughput.
To use the PaddleX high-performance inference plugin, please refer to the PaddleX High-Performance Inference Guide.
You can use the --use_hpip flag to enable the high-performance inference plugin. An example is as follows:
1.3 Invoke the Service¶
The "Development Integration/Deployment" section in each pipeline’s tutorial provides API references and multi-language invocation examples for the service. You can find the tutorials for each pipeline here.
2. High-Stability Serving¶
Please note that the current high-stability serving solution only supports Linux systems.
2.1 Download the High-Stability Serving SDK¶
Find the high-stability serving SDK corresponding to the pipeline in the table below and download it:
👉 Click to view
For manual packaging, please refer to the hps project documentation.
2.2 Adjust Configurations¶
The server/pipeline_config.yaml file of the the high-stability serving SDK is the pipeline configuration file. Users can modify this file to set the model directory to use, etc.
In addition, the PaddleX high-stability serving solution is built on NVIDIA Triton Inference Server, allowing users to modify the configuration files of Triton Inference Server.
In the server/model_repo/{endpoint name} directory of the high-stability serving SDK, you can find one or more config*.pbtxt files. If a config_{device type}.pbtxt file exists in the directory, please modify the configuration file corresponding to the desired device type. Otherwise, please modify config.pbtxt.
A common requirement is to adjust the number of execution instances. To achieve this, you need to modify the instance_group setting in the configuration file, using count to specify the number of instances placed on each device, kind to specify the device type, and gpus to specify the GPU IDs. An example is as follows:
-
Place 4 instances on GPU 0:
-
Place 2 instances on GPU 1, and 1 instance each on GPUs 2 and 3:
For more configuration details, please refer to the Triton Inference Server documentation.
2.3 Run the Server¶
The machine used for deployment needs to have Docker Engine version 19.03 or higher installed.
First, pull the Docker image as needed:
-
Image supporting deployment with NVIDIA GPU (the machine must have NVIDIA drivers that support CUDA 11.8 installed):
-
CPU-only Image:
If you need to build the image on your own, please refer to the hps project documentation
With the image prepared, navigate to the server directory and execute the following command to run the server:
docker run \
-it \
-e PADDLEX_HPS_DEVICE_TYPE={deployment device type} \
-v "$(pwd)":/app \
-w /app \
--rm \
--gpus all \
--init \
--network host \
--shm-size 8g \
{image name} \
/bin/bash server.sh
- The deployment device type can be
cpuorgpu, and the CPU-only image supports onlycpu. - If CPU deployment is required, there is no need to specify
--gpus. - If you need to enter the container for debugging, you can replace
/bin/bash server.shin the command with/bin/bash. Then execute/bin/bash server.shinside the container. - If you want the server to run in the background, you can replace
-itin the command with-d. After the container starts, you can view the container logs withdocker logs -f {container ID}. - Add
-e PADDLEX_HPS_USE_HPIP=1to use the PaddleX high-performance inference plugin to accelerate the pipeline inference process. Please refer to the PaddleX High-Performance Inference Guide for more information.
You may observe output similar to the following:
I1216 11:37:21.601943 35 grpc_server.cc:4117] Started GRPCInferenceService at 0.0.0.0:8001
I1216 11:37:21.602333 35 http_server.cc:2815] Started HTTPService at 0.0.0.0:8000
I1216 11:37:21.643494 35 http_server.cc:167] Started Metrics Service at 0.0.0.0:8002
2.4 Invoke the Service¶
Users can call the pipeline service through the Python client provided by the SDK or by manually constructing HTTP requests (with no restriction on client programming languages).
The services deployed using the high-stability serving solution offer the primary operations that match those of the basic serving solution. For each primary operation, the endpoint names and the request and response data fields are consistent with the basic serving solution. Please refer to the "Development Integration/Deployment" section in the tutorials for each pipeline. The tutorials for each pipeline can be found here.
2.4.1 Use Python Client¶
Navigate to the client directory of the high-stability serving SDK, and run the following command to install dependencies:
# It is recommended to install in a virtual environment
python -m pip install -r requirements.txt
python -m pip install paddlex_hps_client-*.whl
The Python client currently supports Python versions 3.8 to 3.12.
The client.py script in the client directory contains examples of how to call the service and provides a command-line interface.
2.4.2 Manually Construct HTTP Requests¶
The following method demonstrates how to call the service using the HTTP interface in scenarios where the Python client is not applicable.
First, you need to manually construct the HTTP request body. The request body must be in JSON format and contains the following fields:
inputs: Input tensor information. The input tensor namenameis uniformly set toinput, the shape is[1, 1], and the data typedatatypeisBYTES. The tensor datadatacontains a single JSON string, and the content of this JSON should follow the pipeline-specific format (consistent with the basic serving solution).outputs: Output tensor information. The output tensor namenameis uniformly set tooutput.
Taking the general OCR pipeline as an example, the constructed request body is as follows:
{
"inputs": [
{
"name": "input",
"shape": [1, 1],
"datatype": "BYTES",
"data": [
"{\"file\":\"https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_001.png\",\"visualize\":false}"
]
}
],
"outputs": [
{
"name": "output"
}
]
}
Send the constructed request body to the corresponding HTTP inference endpoint of the service. By default, the service listens on HTTP port 8000, and the inference request URL follows the format http://{hostname}:8000/v2/models/{endpoint name}/infer.
Using the general OCR pipeline as an example, the following is a curl command to send the request:
# Assuming `REQUEST_JSON` is the request body constructed in the previous step
curl -s -X POST http://localhost:8000/v2/models/ocr/infer \
-H 'Content-Type: application/json' \
-d "${REQUEST_JSON}"
Finally, the response from the service needs to be parsed. The raw response body has the following structure:
{
"outputs": [
{
"name": "output",
"data": [
"{\"errorCode\": 0, \"result\": {\"ocrResults\": [...]}}"
]
}
]
}
outputs[0].data[0] is a JSON string. The internal fields follow the same format as the response body in the basic serving solution. For detailed parsing rules, please refer to the usage guide for each specific pipeline.
3. Returning Binary Content as URLs¶
By default, both basic serving and high-stability serving return images and other binary content in the response inline as Base64-encoded strings. When the response contains large images or a multi-page PDF, Base64 encoding can significantly inflate the payload; you can configure the service to return URLs instead.
Both deployment modes share the same configuration. Add the following to the Serving section of the pipeline configuration file (return_urls is a top-level field, while file_storage and url_expires_in live under Serving.extra):
Serving:
return_urls: true
extra:
file_storage:
type: bos
endpoint: <BOS endpoint, e.g. https://bj.bcebos.com>
ak: xxx
sk: xxx
bucket_name: <bucket name>
key_prefix: <optional, object key prefix>
url_expires_in: 3600 # Pre-signed URL lifetime in seconds; -1 means no expiry
Field reference:
endpoint: BOS endpoint, required.ak: Baidu Intelligent Cloud Access Key (required).sk: Baidu Intelligent Cloud Secret Key (required).bucket_name: BOS bucket name, required.key_prefix: optional object key prefix.
Where to put the configuration:
- Basic serving: write it to the pipeline config file passed to
paddlex --serve --pipeline. - High-stability serving: write it to
server/pipeline_config.yamlinside the SDK and restart the container.
Notes:
file_storage.typesupportsbos,file_system, andmemory; onlybosprovides pre-signed URLs. Whenreturn_urls: trueis enabled,file_storagemust bebos, otherwise the server fails to start.- Field types are unchanged; only the value changes from a Base64 string to a pre-signed URL that can be fetched within
url_expires_inseconds. - For more information on obtaining AK/SK and other details, refer to the Baidu Intelligent Cloud Official Documentation.