PaddleX Semantic Segmentation Task Module Data Annotation Tutorial¶
This document will introduce how to use the Labelme annotation tool to complete data annotation for a single model related to semantic segmentation. Click on the link above to install the data annotation tool and view detailed usage instructions by referring to the homepage documentation.
1. Annotation Data Examples¶
This dataset is a manually collected street scene dataset, covering two categories of vehicles and roads, including photos taken from different angles of the targets. Image examples:






2. Labelme Annotation¶
2.1 Introduction to Labelme Annotation Tool¶
Labelme is an image annotation software written in python with a graphical interface. It can be used for tasks such as image classification, object detection, and semantic segmentation. In semantic segmentation annotation tasks, labels are stored as JSON files.
2.2 Labelme Installation¶
To avoid environment conflicts, it is recommended to install in a conda environment.
2.3 Labelme Annotation Process¶
2.3.1 Prepare Data for Annotation¶
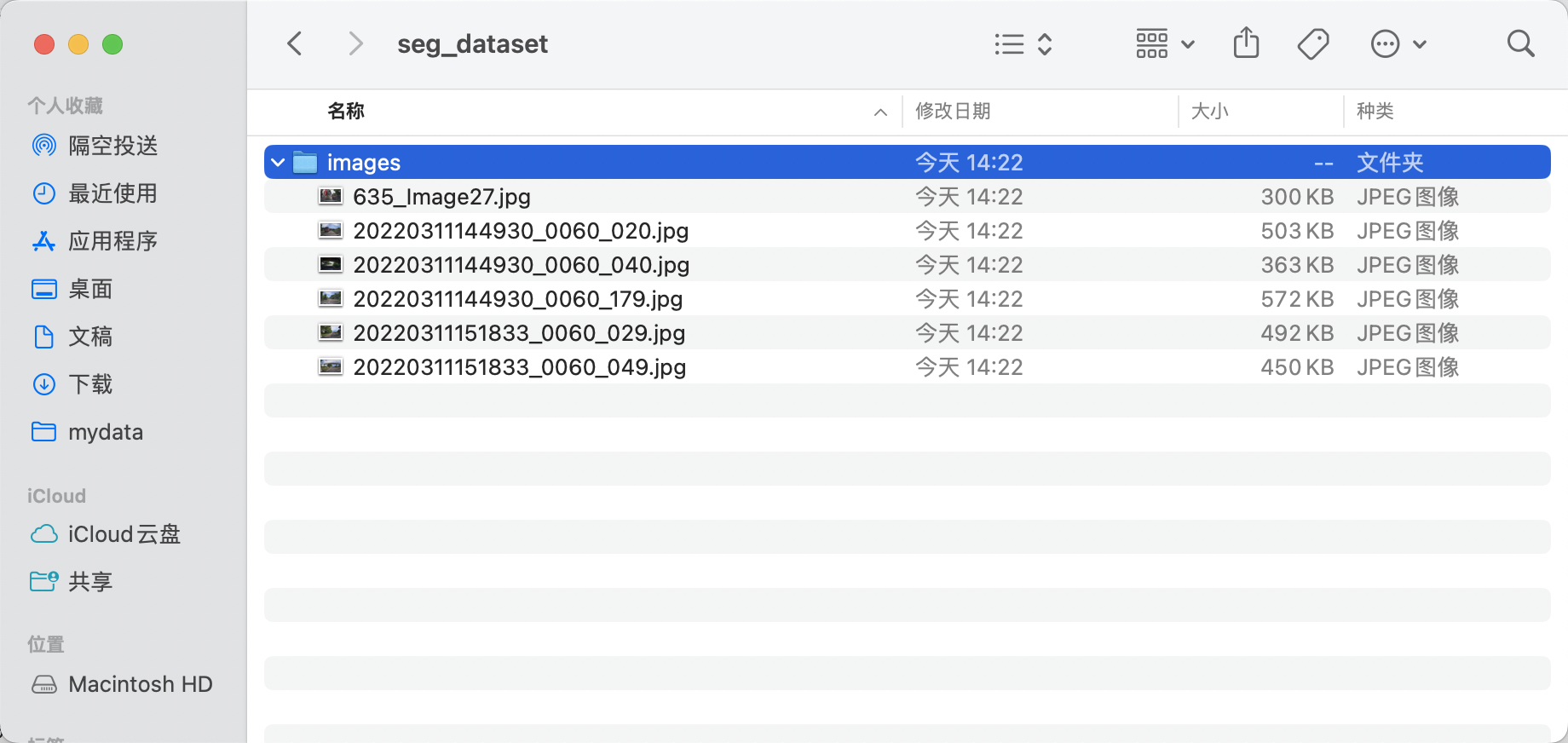
- Create a root directory for the dataset, such as
seg_dataset - Create an
imagesdirectory withinseg_dataset(the directory name can be modified, but ensure the subsequent command's image directory name is correct), and store the images to be annotated in theimagesdirectory, as shown below:
2.3.2 Launch Labelme¶
Navigate to the root directory of the dataset to be annotated in the terminal and launch the labelme annotation tool.
nodata stops storing image data in the JSON file
* autosave enables automatic saving
* output specifies the path for storing label files
2.3.3 Start Image Annotation¶
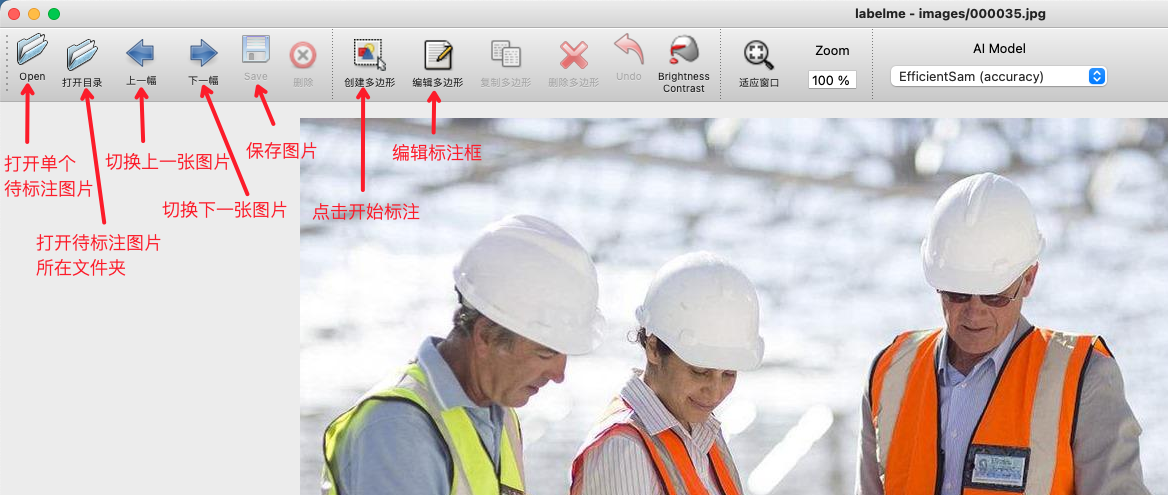
- After launching
labelme, it will look like this:
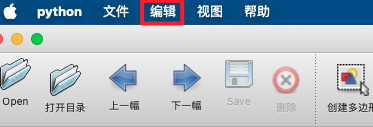
 * Click "Edit" to select the annotation type
* Click "Edit" to select the annotation type
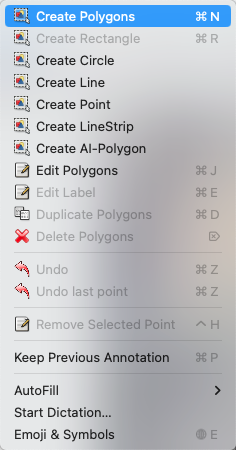
 * Choose to create polygons
* Choose to create polygons
 * Draw the target contour on the image
* Draw the target contour on the image

- When the contour line is closed as shown in the left image below, a category selection box will pop up, allowing you to input or select the target category
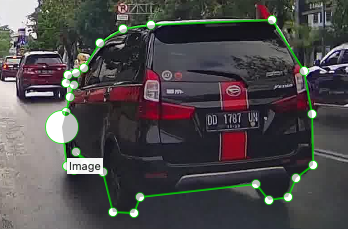
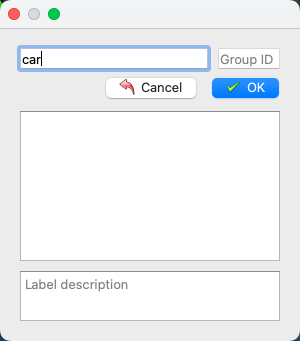
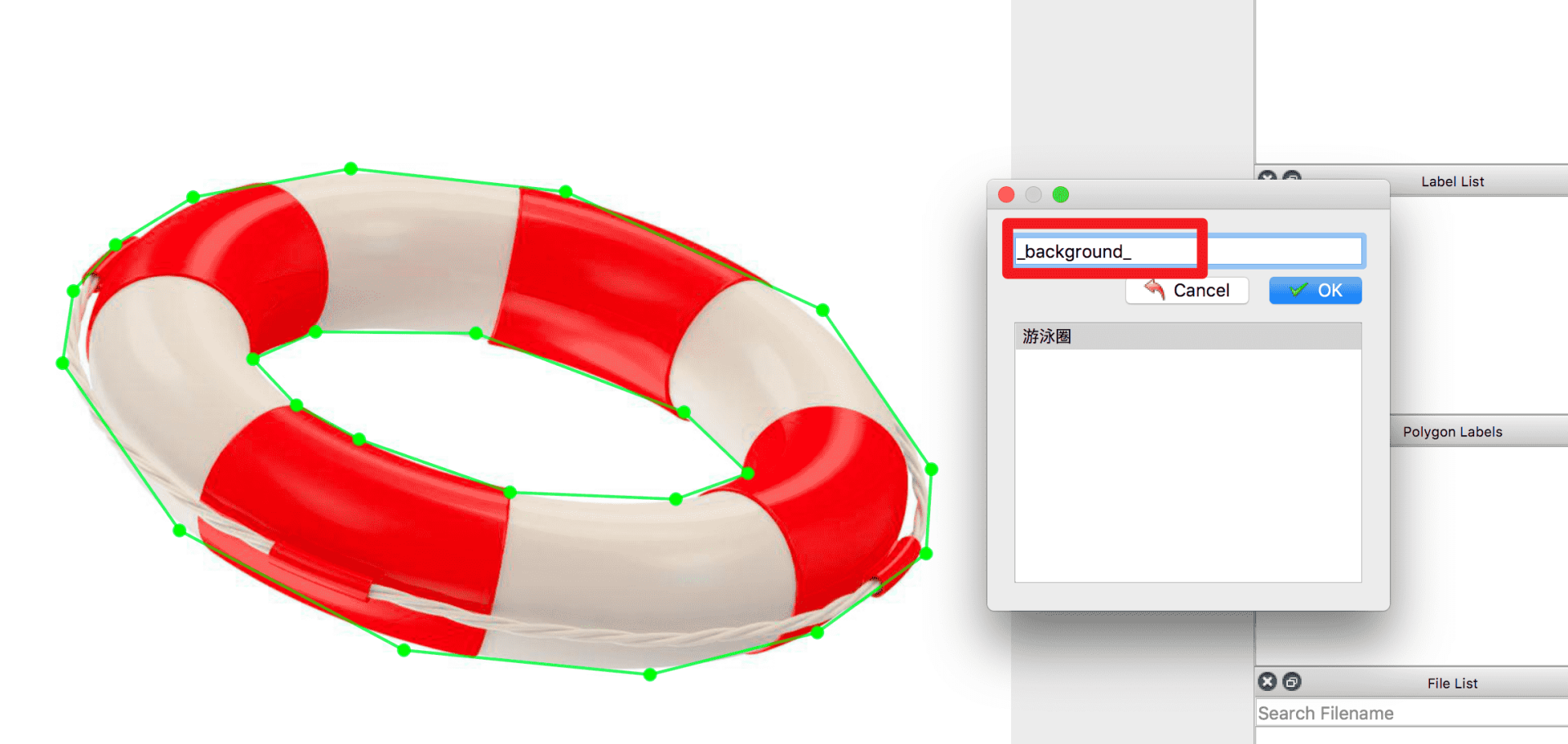
Typically, only the foreground objects need to be labeled with their respective categories, while other pixels are automatically considered as background. If manual background labeling is required, the category must be set to background, otherwise errors may occur during dataset format conversion. For noisy parts or irrelevant sections in the image that should not participate in model training, the ignore class can be used, and the model will automatically skip those parts during training. For objects with holes, after outlining the main object, draw polygons along the edges of the holes and assign a specific category to the holes. If the hole represents background, assign it as background. An example is shown below:
- After labeling, click "Save". (If the
outputfield is not specified when startinglabelme, it will prompt to select a save path upon the first save. Ifautosaveis enabled, the save button is not required.)
 * Then click "Next Image" to proceed to the next image for labeling.
* Then click "Next Image" to proceed to the next image for labeling.

- The final labeled file will look like this:
-
Adjust the directory structure to obtain a standard LabelMe format dataset for safety helmet detection: a. Download and execute the directory organization script in the root directory of your dataset,
seg_dataset. After executing the script, thetrain_anno_list.txtandval_anno_list.txtfiles will contain content as shown: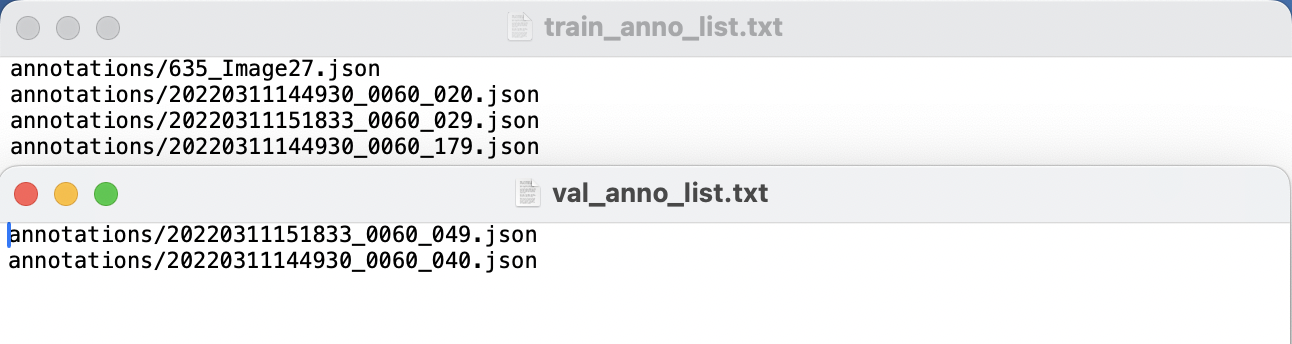 b. The final directory structure after organization will look like this:
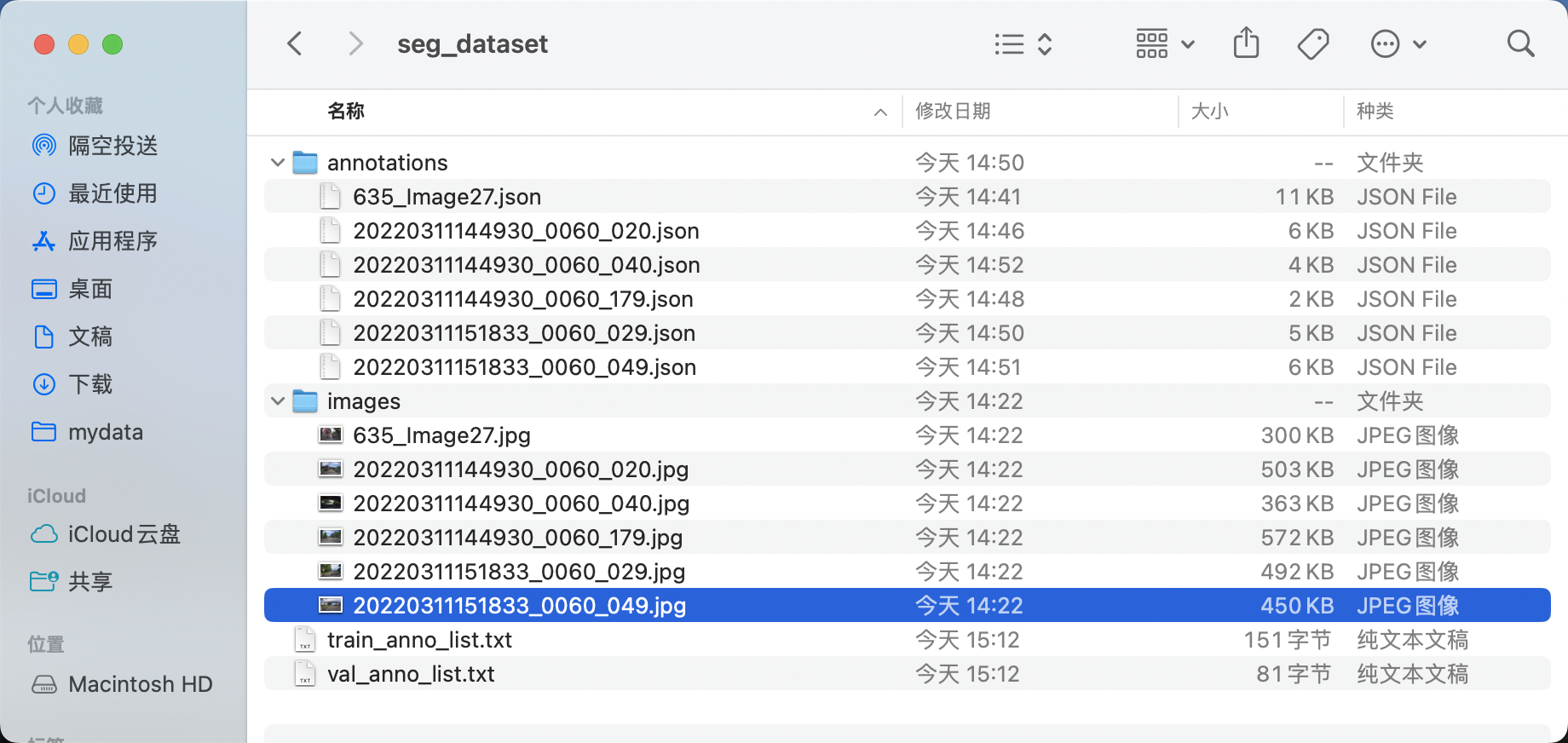
b. The final directory structure after organization will look like this:
2.3.4 Format Conversion¶
After labeling with LabelMe, the data format needs to be converted to the Seg data format. Below is a code example for converting data labeled using LabelMe according to the above tutorial.
cd /path/to/paddlex
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/data/seg_dataset_to_convert.tar -P ./dataset
tar -xf ./dataset/seg_dataset_to_convert.tar -C ./dataset/
python main.py -c paddlex/configs/semantic_segmentation/PP-LiteSeg-T.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/seg_dataset_to_convert \
-o CheckDataset.convert.enable=True \
-o CheckDataset.convert.src_dataset_type=LabelMe
Data Format¶
The dataset defined by PaddleX for image segmentation tasks is named SegDataset, with the following organizational structure and annotation format:
dataset_dir # Root directory of the dataset, the directory name can be changed
├── annotations # Directory for storing annotated images, the directory name can be changed, matching the content of the manifest files
├── images # Directory for storing original images, the directory name can be changed, matching the content of the manifest files
├── train.txt # Annotation file for the training set, the file name cannot be changed. Each line contains the path to the original image and the annotated image, separated by a space. Example: images/P0005.jpg annotations/P0005.png
└── val.txt # Annotation file for the validation set, the file name cannot be changed. Each line contains the path to the original image and the annotated image, separated by a space. Example: images/N0139.jpg annotations/N0139.png
PNG format. Each pixel value in the label image represents a category, and the categories should start from 0 and increase sequentially, for example, 0, 1, 2, 3 represent 4 categories. The pixel storage of the label image is 8bit, so a maximum of 256 categories are supported for labeling.
Please prepare your data according to the above specifications. Additionally, you can refer to: Example Dataset