General Table Recognition Pipeline Tutorial¶
1. Introduction to General Table Recognition Pipeline¶
Table recognition is a technology that automatically identifies and extracts table content and structure from documents or images. It is widely used in data entry, information retrieval, and document analysis. By using computer vision and machine learning algorithms, table recognition can convert complex table information into editable formats, facilitating further processing and analysis of data.
The General Table Recognition Pipeline is designed to solve table recognition tasks by identifying tables in images and outputting them in HTML format. This pipeline integrates the well-known SLANet and SLANet_plus table structure recognition models. Based on this pipeline, precise predictions of tables can be achieved, covering a wide range of applications in general, manufacturing, finance, transportation, and other fields. The pipeline also provides flexible service deployment options, supporting various hardware and programming languages for integration. Moreover, it offers custom development capabilities, allowing you to train and optimize models on your own dataset, which can then be seamlessly integrated.
 The General Table Recognition Pipeline includes essential modules for table structure recognition, text detection, and text recognition, as well as optional modules for layout area detection, document image orientation classification, and text image correction.
The General Table Recognition Pipeline includes essential modules for table structure recognition, text detection, and text recognition, as well as optional modules for layout area detection, document image orientation classification, and text image correction.
If you prioritize model accuracy, choose a high-accuracy model; if you prioritize inference speed, choose a faster model; if you care about model size, choose a smaller model.
The inference time only includes the model inference time and does not include the time for pre- or post-processing.
👉Model List Details
Table Structure Recognition Module Models:
| Model | Model Download Link | Accuracy (%) | GPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
Model Storage Size (MB) | Introduction |
|---|---|---|---|---|---|---|
| SLANet | Inference Model/Training Model | 59.52 | 23.96 / 21.75 | - / 43.12 | 6.9 | SLANet is a self-developed table structure recognition model by the Baidu PaddleX Team. This model significantly improves the accuracy and inference speed of table structure recognition by using a CPU-friendly lightweight backbone network PP-LCNet, a high-low feature fusion module CSP-PAN, and a feature decoding module SLA Head that aligns structure and position information. |
| SLANet_plus | Inference Model/Training Model | 63.69 | 23.43 / 22.16 | - / 41.80 | 6.9 |
Text Detection Module Models:
| Model | Model Download Link | Detection Hmean (%) | GPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
Model Storage Size (MB) | Introduction |
|---|---|---|---|---|---|---|
| PP-OCRv5_server_det | Inference Model/Training Model | 83.8 | 89.55 / 70.19 | 383.15 / 383.15 | 84.3 | PP-OCRv5 server-side text detection model with higher accuracy, suitable for deployment on high-performance servers |
| PP-OCRv5_mobile_det | Inference Model/Training Model | 79.0 | 10.67 / 6.36 | 57.77 / 28.15 | 4.7 | PP-OCRv5 mobile-side text detection model with higher efficiency, suitable for deployment on edge devices |
| PP-OCRv4_server_det | Inference Model/Training Model | 69.2 | 127.82 / 98.87 | 585.95 / 489.77 | 109 | PP-OCRv4 server-side text detection model with higher accuracy, suitable for deployment on high-performance servers |
| PP-OCRv4_mobile_det | Inference Model/Training Model | 63.8 | 9.87 / 4.17 | 56.60 / 20.79 | 4.7 | PP-OCRv4 mobile-side text detection model with higher efficiency, suitable for deployment on edge devices |
Text Recognition Module Models:
| Model | Model Download Link | Recognition Avg Accuracy(%) | GPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
Model Storage Size (MB) | Introduction |
|---|---|---|---|---|---|---|
| PP-OCRv4_mobile_rec | Inference Model/Training Model | 78.20 | 5.26 / 1.12 | 17.48 / 3.61 | 10.5 | PP-OCRv4 is the next version of the self-developed text recognition model PP-OCRv3 by the PaddlePaddle Vision Team. By introducing data augmentation and GTC-NRTR guidance branches, it further improves text recognition accuracy without changing the model inference speed. This model provides both server and mobile versions to meet industrial needs in different scenarios. |
| PP-OCRv4_server_rec | Inference Model/Training Model | 85.19 | 8.75 / 2.49 | 36.93 / 36.93 | 173 |
| Model | Model Download Link | Recognition Avg Accuracy(%) | GPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
Model Storage Size (MB) | Introduction |
|---|---|---|---|---|---|---|
| ch_SVTRv2_rec | Inference Model/Training Model | 68.81 | 10.38 / 8.31 | 66.52 / 30.83 | 80.5 | SVTRv2 is a server text recognition model developed by the OpenOCR team from the Visual and Learning Laboratory (FVL) at Fudan University. It won the first prize in the PaddleOCR Algorithm Model Challenge - Task 1: End-to-End OCR Recognition, with a 6% improvement in end-to-end recognition accuracy compared to PP-OCRv4. |
| Model | Model Download Link | Recognition Avg Accuracy(%) | GPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
Model Storage Size (MB) | Introduction |
|---|---|---|---|---|---|---|
| ch_RepSVTR_rec | Inference Model/Training Model | 65.07 | 6.29 / 1.57 | 20.64 / 5.40 | 48.8 | The RepSVTR text recognition model is a mobile text recognition model based on SVTRv2. It won the first prize in the PaddleOCR algorithm model competition - Task 1: OCR end-to-end recognition task. Compared with PP-OCRv4, the end-to-end recognition accuracy on the B list was improved by 2.5%, while the inference speed remained the same. |
| Model | Model Download Link | mAP(0.5)(%) | GPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
Model Storage Size (MB) | Introduction |
|---|---|---|---|---|---|---|
| PP-DocLayout-L | Inference Model/Training Model | 90.4 | 33.59 / 33.59 | 503.01 / 251.08 | 123.76 | A high-precision layout region localization model trained on a self-built dataset containing Chinese and English papers, magazines, contracts, books, exams, and research reports, based on RT-DETR-L. |
| PP-DocLayout-M | Inference Model/Training Model | 75.2 | 13.03 / 4.72 | 43.39 / 24.44 | 22.578 | A layout region localization model with balanced accuracy and efficiency, trained on a self-built dataset containing Chinese and English papers, magazines, contracts, books, exams, and research reports, based on PicoDet-L. |
| PP-DocLayout-S | Inference Model/Training Model | 70.9 | 11.54 / 3.86 | 18.53 / 6.29 | 4.834 | A high-efficiency layout region localization model trained on a self-built dataset containing Chinese and English papers, magazines, contracts, books, exams, and research reports, based on PicoDet-S. |
Layout Detection Module Models (Optional):
| Model | Model Download Link | mAP(0.5) (%) | GPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
Model Storage Size (MB) | Introduction |
|---|---|---|---|---|---|---|
| PicoDet_layout_1x | Inference Model/Training Model | 97.8 | 9.62 / 6.75 | 26.96 / 12.77 | 7.4 | A high-efficiency layout detection model trained on the PubLayNet dataset based on PicoDet-1x, capable of locating five types of regions: text, title, table, image, and list. |
| PicoDet_layout_1x_table | Inference Model/Training Model | 97.5 | 9.57 / 6.63 | 27.66 / 16.75 | 7.4 | A high-efficiency layout detection model trained on a custom dataset based on PicoDet-1x, capable of locating one type of region: table. |
| PicoDet-S_layout_3cls | Inference Model/Training Model | 88.2 | 8.43 / 3.44 | 17.60 / 6.51 | 4.8 | A high-efficiency layout detection model trained on a custom dataset in Chinese and English papers, magazines, and research reports based on the lightweight PicoDet-S model, including three categories: table, image, and seal. |
| PicoDet-S_layout_17cls | Inference Model/Training Model | 87.4 | 8.80 / 3.62 | 17.51 / 6.35 | 4.8 | A high-efficiency layout detection model trained on a custom dataset in Chinese and English papers, magazines, and research reports based on the lightweight PicoDet-S model, including 17 common layout categories: paragraph title, image, text, number, abstract, content, chart title, formula, table, table title, reference, document title, footnote, header, algorithm, footer, seal. |
| PicoDet-L_layout_3cls | Inference Model/Training Model | 89.0 | 12.80 / 9.57 | 45.04 / 23.86 | 22.6 | A high-efficiency layout detection model trained on a custom dataset in Chinese and English papers, magazines, and research reports based on PicoDet-L, including three categories: table, image, and seal. |
| PicoDet-L_layout_17cls | Inference Model/Training Model | 89.0 | 12.60 / 10.27 | 43.70 / 24.42 | 22.6 | A high-efficiency layout detection model trained on a custom dataset in Chinese and English papers, magazines, and research reports based on PicoDet-L, including 17 common layout categories: paragraph title, image, text, number, abstract, content, chart title, formula, table, table title, reference, document title, footnote, header, algorithm, footer, seal. |
| RT-DETR-H_layout_3cls | Inference Model/Training Model | 95.8 | 114.80 / 25.65 | 924.38 / 924.38 | 470.1 | A high-precision layout detection model trained on a custom dataset in Chinese and English papers, magazines, and research reports based on RT-DETR-H, including three categories: table, image, and seal. |
| RT-DETR-H_layout_17cls | Inference Model/Training Model | 92.6 | 115.29 / 101.18 | 964.75 / 964.75 | 470.2 | A high-precision layout detection model trained on a custom dataset in Chinese and English papers, magazines, and research reports based on RT-DETR-H, including 17 common layout categories: paragraph title, image, text, number, abstract, content, chart title, formula, table, table title, reference, document title, footnote, header, algorithm, footer, seal. |
Text Image Rectification Module Models (Optional):
| Model | Model Download Link | CER | GPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
Model Storage Size (MB) | Introduction |
|---|---|---|---|---|---|---|
| UVDoc | Inference Model/Training Model | 0.179 | 19.05 / 19.05 | - / 869.82 | 30.3 | High-precision text image rectification model. |
Document Image Orientation Classification Module Models (Optional):
| Model | Model Download Link | Top-1 Acc (%) | GPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
Model Storage Size (MB) | Introduction |
|---|---|---|---|---|---|---|
| PP-LCNet_x1_0_doc_ori | Inference Model/Training Model | 99.06 | 2.62 / 0.59 | 3.24 / 1.19 | 7 | A document image classification model based on PP-LCNet_x1_0, containing four categories: 0 degrees, 90 degrees, 180 degrees, and 270 degrees. |
Text Recognition Module Models:
| Model | Model Download Link | Recognition Avg Accuracy(%) | CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
Model Storage Size (MB) | Introduction |
|---|---|---|---|---|---|---|
| PP-OCRv4_server_rec_doc | Inference Model/Training Model | 86.58 | 8.69 / 2.78 | 37.93 / 37.93 | 182 | PP-OCRv4_server_rec_doc is trained on a mixed dataset of more Chinese document data and PP-OCR training data based on PP-OCRv4_server_rec. It has added the ability to recognize some traditional Chinese characters, Japanese, and special characters, and can support the recognition of more than 15,000 characters. In addition to improving the text recognition capability related to documents, it also enhances the general text recognition capability. |
| PP-OCRv4_mobile_rec | Inference Model/Training Model | 78.74 | 5.26 / 1.12 | 17.48 / 3.61 | 10.5 | The lightweight recognition model of PP-OCRv4 has high inference efficiency and can be deployed on various hardware devices, including edge devices. |
| PP-OCRv4_server_rec | Inference Model/Training Model | 85.19 | 8.75 / 2.49 | 36.93 / 36.93 | 173 | The server-side model of PP-OCRv4 offers high inference accuracy and can be deployed on various types of servers. |
| en_PP-OCRv4_mobile_rec | Inference Model/Training Model | 70.39 | 4.81 / 1.23 | 17.20 / 4.18 | 7.5 | The ultra-lightweight English recognition model, trained based on the PP-OCRv4 recognition model, supports the recognition of English letters and numbers. |
👉Model List Details
* Chinese Recognition Model| Model | Model Download Link | Recognition Avg Accuracy(%) | CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
Model Storage Size (MB) | Introduction |
|---|---|---|---|---|---|---|
| PP-OCRv4_server_rec_doc | Inference Model/Training Model | 86.58 | 8.69 / 2.78 | 37.93 / 37.93 | 182 | PP-OCRv4_server_rec_doc is trained on a mixed dataset of more Chinese document data and PP-OCR training data based on PP-OCRv4_server_rec. It has added the recognition capabilities for some traditional Chinese characters, Japanese, and special characters. The number of recognizable characters is over 15,000. In addition to the improvement in document-related text recognition, it also enhances the general text recognition capability. |
| PP-OCRv4_mobile_rec | Inference Model/Training Model | 78.74 | 5.26 / 1.12 | 17.48 / 3.61 | 10.5 | The lightweight recognition model of PP-OCRv4 has high inference efficiency and can be deployed on various hardware devices, including edge devices. |
| PP-OCRv4_server_rec | Inference Model/Training Model | 85.19 | 8.75 / 2.49 | 36.93 / 36.93 | 173 | The server-side model of PP-OCRv4 offers high inference accuracy and can be deployed on various types of servers. |
| PP-OCRv3_mobile_rec | Inference Model/Training Model | 72.96 | 3.89 / 1.16 | 8.72 / 3.56 | 10.3 | PP-OCRv3’s lightweight recognition model is designed for high inference efficiency and can be deployed on a variety of hardware devices, including edge devices. |
| Model | Model Download Link | Recognition Avg Accuracy(%) | GPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
Model Storage Size (MB) | Introduction |
|---|---|---|---|---|---|---|
| ch_SVTRv2_rec | Inference Model/Training Model | 68.81 | 10.38 / 8.31 | 66.52 / 30.83 | 80.5 | SVTRv2 is a server text recognition model developed by the OpenOCR team of Fudan University's Visual and Learning Laboratory (FVL). It won the first prize in the PaddleOCR Algorithm Model Challenge - Task One: OCR End-to-End Recognition Task. The end-to-end recognition accuracy on the A list is 6% higher than that of PP-OCRv4. |
| Model | Model Download Link | Recognition Avg Accuracy(%) | GPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
Model Storage Size (MB) | Introduction |
|---|---|---|---|---|---|---|
| ch_RepSVTR_rec | Inference Model/Training Model | 65.07 | 6.29 / 1.57 | 20.64 / 5.40 | 48.8 | The RepSVTR text recognition model is a mobile text recognition model based on SVTRv2. It won the first prize in the PaddleOCR Algorithm Model Challenge - Task One: OCR End-to-End Recognition Task. The end-to-end recognition accuracy on the B list is 2.5% higher than that of PP-OCRv4, with the same inference speed. |
| Model | Model Download Link | Recognition Avg Accuracy(%) | GPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
Model Storage Size (MB) | Introduction |
|---|---|---|---|---|---|---|
| en_PP-OCRv4_mobile_rec | Inference Model/Training Model | 70.39 | 4.81 / 1.23 | 17.20 / 4.18 | 7.5 | The ultra-lightweight English recognition model trained based on the PP-OCRv4 recognition model supports the recognition of English and numbers. |
| en_PP-OCRv3_mobile_rec | Inference Model/Training Model | 70.69 | 3.56 / 0.78 | 8.44 / 5.78 | 17.3 | The ultra-lightweight English recognition model trained based on the PP-OCRv3 recognition model supports the recognition of English and numbers. |
| Model | Model Download Link | Recognition Avg Accuracy(%) | GPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
Model Storage Size (MB) | Introduction |
|---|---|---|---|---|---|---|
| korean_PP-OCRv3_mobile_rec | Inference Model/Training Model | 60.21 | 3.73 / 0.98 | 8.76 / 2.91 | 9.6 | The ultra-lightweight Korean recognition model trained based on the PP-OCRv3 recognition model supports the recognition of Korean and numbers. |
| japan_PP-OCRv3_mobile_rec | Inference Model/Training Model | 45.69 | 3.86 / 1.01 | 8.62 / 2.92 | 9.8 | The ultra-lightweight Japanese recognition model trained based on the PP-OCRv3 recognition model supports the recognition of Japanese and numbers. |
| chinese_cht_PP-OCRv3_mobile_rec | Inference Model/Training Model | 82.06 | 3.90 / 1.16 | 9.24 / 3.18 | 10.8 | The ultra-lightweight Traditional Chinese recognition model trained based on the PP-OCRv3 recognition model supports the recognition of Traditional Chinese and numbers. |
| te_PP-OCRv3_mobile_rec | Inference Model/Training Model | 95.88 | 3.59 / 0.81 | 8.28 / 6.21 | 8.7 | The ultra-lightweight Telugu recognition model trained based on the PP-OCRv3 recognition model supports the recognition of Telugu and numbers. |
| ka_PP-OCRv3_mobile_rec | Inference Model/Training Model | 96.96 | 3.49 / 0.89 | 8.63 / 2.77 | 17.4 | The ultra-lightweight Kannada recognition model trained based on the PP-OCRv3 recognition model supports the recognition of Kannada and numbers. |
| ta_PP-OCRv3_mobile_rec | Inference Model/Training Model | 76.83 | 3.49 / 0.86 | 8.35 / 3.41 | 8.7 | The ultra-lightweight Tamil recognition model trained based on the PP-OCRv3 recognition model supports the recognition of Tamil and numbers. |
| latin_PP-OCRv3_mobile_rec | Inference Model/Training Model | 76.93 | 3.53 / 0.78 | 8.50 / 6.83 | 8.7 | The ultra-lightweight Latin recognition model trained based on the PP-OCRv3 recognition model supports the recognition of Latin script and numbers. |
| arabic_PP-OCRv3_mobile_rec | Inference Model/Training Model | 73.55 | 3.60 / 0.83 | 8.44 / 4.69 | 17.3 | The ultra-lightweight Arabic script recognition model trained based on the PP-OCRv3 recognition model supports the recognition of Arabic script and numbers. |
| cyrillic_PP-OCRv3_mobile_rec | Inference Model/Training Model | 94.28 | 3.56 / 0.79 | 8.22 / 2.76 | 8.7 | The ultra-lightweight cyrillic alphabet recognition model trained based on the PP-OCRv3 recognition model supports the recognition of cyrillic letters and numbers. |
| devanagari_PP-OCRv3_mobile_rec | Inference Model/Training Model | 96.44 | 3.60 / 0.78 | 6.95 / 2.87 | 7.9 | The ultra-lightweight Devanagari script recognition model trained based on the PP-OCRv3 recognition model supports the recognition of Devanagari script and numbers. |
- Performance Test Environment
- Test Dataset:
- Document Image Orientation Classification Module: A self-built dataset using PaddleX, covering multiple scenarios such as ID cards and documents, containing 1000 images.
- Text Image Rectification Model: DocUNet.
- Layout Region Detection Model: A layout region analysis dataset built by PaddleOCR, containing 10,000 images of common document types such as Chinese and English papers, magazines, and research reports.
- Table Structure Recognition Model: An internal English table recognition dataset built by PaddleX.
- Text Detection Model: A Chinese dataset built by PaddleOCR, covering multiple scenarios such as street scenes, web images, documents, and handwriting, with 500 images for detection.
- Chinese Recognition Model: A Chinese dataset built by PaddleOCR, covering multiple scenarios such as street scenes, web images, documents, and handwriting, with 11,000 images for text recognition.
- ch_SVTRv2_rec: PaddleOCR Algorithm Model Challenge - Task 1: OCR End-to-End Recognition Task A-list evaluation set.
- ch_RepSVTR_rec: PaddleOCR Algorithm Model Challenge - Task 1: OCR End-to-End Recognition Task B-list evaluation set.
- English Recognition Model: An English dataset built by PaddleX.
- Multilingual Recognition Model: A multilingual dataset built by PaddleX.
- Hardware Configuration:
- GPU: NVIDIA Tesla T4
- CPU: Intel Xeon Gold 6271C @ 2.60GHz
- Software Environment:
- Ubuntu 20.04 / CUDA 11.8 / cuDNN 8.9 / TensorRT 8.6.1.6
- paddlepaddle 3.0.0 / paddlex 3.0.3
- Test Dataset:
| Mode | GPU Configuration | CPU Configuration | Acceleration Technology Combination |
|---|---|---|---|
| Normal Mode | FP32 Precision / No TRT Acceleration | FP32 Precision / 8 Threads | PaddleInference |
| High-Performance Mode | Optimal combination of pre-selected precision types and acceleration strategies | FP32 Precision / 8 Threads | Pre-selected optimal backend (Paddle/OpenVINO/TRT, etc.) |
2. Quick Start¶
The pre-trained models provided by PaddleX can be quickly experienced. You can experience the effect of the general table recognition pipeline online on the Baidu AIStudio Community, or you can experience it locally using the command line or Python.
2.1 Online Experience¶
You can experience online the effect of the general table recognition pipeline using the official demo images, for example:
If you are satisfied with the performance of the pipeline, you can directly integrate and deploy it. You can choose to download the deployment package from the cloud, or refer to the method in Section 2.2 Local Experience for local deployment. If you are not satisfied with the effect, you can fine-tune the models in the pipeline using private data. If you have local training hardware resources, you can start training directly on your local machine; if not, the Baidu AI Studio provides a one-click training service. No code is required; simply upload your data to start the training task.
2.2 Local Experience¶
Before using the General Table Recognition pipeline locally, ensure you have installed the PaddleX wheel package following the PaddleX Local Installation Guide. If you wish to selectively install dependencies, please refer to the relevant instructions in the installation guide. The dependency group corresponding to this pipeline is ocr.
2.1 Command Line Experience¶
You can quickly experience the table recognition pipeline with a single command. Use the test file, and replace --input with your local path for prediction.
{kind=link}
paddlex --pipeline table_recognition \
--use_doc_orientation_classify=False \
--use_doc_unwarping=False \
--input table_recognition.jpg \
--save_path ./output \
--device gpu:0
Note: The official models would be download from HuggingFace by first. PaddleX also support to specify the preferred source by setting the environment variable PADDLE_PDX_MODEL_SOURCE. The supported values are huggingface, aistudio, bos, and modelscope. For example, to prioritize using bos, set: PADDLE_PDX_MODEL_SOURCE="bos".
The content of the parameters can refer to the parameter description in 2.2 Python Script Method. Supports specifying multiple devices simultaneously for parallel inference. For details, please refer to the documentation on pipeline parallel inference.
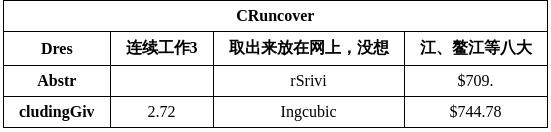
After running, the result will be printed to the terminal, as follows:
{'res': {'input_path': 'table_recognition.jpg', 'page_index': None, 'model_settings': {'use_doc_preprocessor': False, 'use_layout_detection': True, 'use_ocr_model': True}, 'layout_det_res': {'input_path': None, 'page_index': None, 'boxes': [{'cls_id': 0, 'label': 'Table', 'score': 0.9922188520431519, 'coordinate': [3.0127392, 0.14648987, 547.5102, 127.72023]}]}, 'overall_ocr_res': {'input_path': None, 'page_index': None, 'model_settings': {'use_doc_preprocessor': False, 'use_textline_orientation': False}, 'dt_polys': array([[[234, 6],
...,
[234, 25]],
...,
[[448, 101],
...,
[448, 121]]], dtype=int16), 'text_det_params': {'limit_side_len': 960, 'limit_type': 'max', 'thresh': 0.3, 'box_thresh': 0.6, 'unclip_ratio': 2.0}, 'text_type': 'general', 'textline_orientation_angles': array([-1, ..., -1]), 'text_rec_score_thresh': 0, 'rec_texts': ['CRuncover', 'Dres', '连续工作3', '取出来放在网上', '没想', '江、整江等八大', 'Abstr', 'rSrivi', '$709.', 'cludingGiv', '2.72', 'Ingcubic', '$744.78'], 'rec_scores': array([0.99512607, ..., 0.99844509]), 'rec_polys': array([[[234, 6],
...,
[234, 25]],
...,
[[448, 101],
...,
[448, 121]]], dtype=int16), 'rec_boxes': array([[234, ..., 25],
...,
[448, ..., 121]], dtype=int16)}, 'table_res_list': [{'cell_box_list': array([[ 5.01273918, ..., 32.14648987],
...,
[405.01273918, ..., 124.14648987]]), 'pred_html': '<html><body><table><tbody><tr><td colspan="4">CRuncover</td></tr><tr><td>Dres</td><td>连续工作3</td><td>取出来放在网上 没想</td><td>江、整江等八大</td></tr><tr><td>Abstr</td><td></td><td>rSrivi</td><td>$709.</td></tr><tr><td>cludingGiv</td><td>2.72</td><td>Ingcubic</td><td>$744.78</td></tr></tbody></table></body></html>', 'table_ocr_pred': {'rec_polys': array([[[234, 6],
...,
[234, 25]],
...,
[[448, 101],
...,
[448, 121]]], dtype=int16), 'rec_texts': ['CRuncover', 'Dres', '连续工作3', '取出来放在网上', '没想', '江、整江等八大', 'Abstr', 'rSrivi', '$709.', 'cludingGiv', '2.72', 'Ingcubic', '$744.78'], 'rec_scores': array([0.99512607, ..., 0.99844509]), 'rec_boxes': array([[234, ..., 25],
...,
[448, ..., 121]], dtype=int16)}}]}}
The running result parameters can be referred to the result explanation in 2.2 Python Script Integration.
The visualization results are saved under save_path, where the visualization result of table recognition is as follows:

2.2 Python Script Integration¶
- The above command line is for a quick experience to view the results. Generally, in a project, it is often necessary to integrate through code. You can complete the fast inference of the pipeline with just a few lines of code. The inference code is as follows:
from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="table_recognition")
output = pipeline.predict(
input="table_recognition.jpg",
use_doc_orientation_classify=False,
use_doc_unwarping=False,
)
for res in output:
res.print()
res.save_to_img("./output/")
res.save_to_xlsx("./output/")
res.save_to_html("./output/")
res.save_to_json("./output/")
In the above Python script, the following steps are executed:
(1) The create_pipeline() function is used to instantiate a general table recognition pipeline object, with the specific parameters described as follows:
| Parameter | Parameter Description | Parameter Type | Default Value | |
|---|---|---|---|---|
pipeline |
The name of the pipeline or the path to the pipeline configuration file. If it is a pipeline name, it must be supported by PaddleX. | str |
None |
|
config |
The specific configuration information of the pipeline (if set simultaneously with pipeline, it has a higher priority than pipeline, and the pipeline name must be consistent with pipeline). |
dict[str, Any] |
None |
|
device |
The inference device for the pipeline. It supports specifying the specific GPU card number, such as "gpu:0", other hardware card numbers, such as "npu:0", and CPU as "cpu". Supports specifying multiple devices simultaneously for parallel inference. For details, please refer to Pipeline Parallel Inference. | str |
gpu:0 |
|
use_hpip |
Whether to enable the high-performance inference plugin. If set to None, the setting from the configuration file or config will be used. |
bool |
None | None |
hpi_config |
High-performance inference configuration | dict | None |
None | None |
engine |
Inference engine | str | None |
Optional paddle, paddle_static, paddle_dynamic, hpi, flexible, transformers, genai_client. |
None |
engine_config |
Inference engine configuration | dict | None |
Different engines support different fields, please refer to Inference Engine and Configuration. | None |
pp_option |
Used for changing runtime mode and other configuration items | PaddlePredictorOption |
For detailed inference configuration, please refer to Compatible Configuration (PaddlePredictorOption). | None |
(2) The predict() method of the general table recognition pipeline object is called to perform inference prediction. This method returns a generator. Below are the parameters and their descriptions for the predict() method:
| Parameter | Description | Type | Options | Default Value |
|---|---|---|---|---|
input |
Data to be predicted, supports multiple input types, required. | Python Var|str|list |
|
None |
use_doc_orientation_classify |
Whether to use the document orientation classification module. | bool|None |
|
None |
use_doc_unwarping |
Whether to use the document unwarping module. | bool|None |
|
None |
use_layout_detection |
Whether to use the layout detection module. | bool|None |
|
None |
text_det_limit_side_len |
Image side length limit for text detection | int|None |
|
None |
text_det_limit_type |
Type of image side length limit for text detection | str|None |
|
None |
text_det_thresh |
Detection pixel threshold, in the output probability map, pixels with scores greater than this threshold will be considered as text pixels | float|None |
|
None |
text_det_box_thresh |
Detection box threshold, for a detection result, if the average score of all pixels within the bounding box is greater than this threshold, it will be considered as a text area | float|None |
|
None |
text_det_unclip_ratio |
Text detection expansion ratio, this value determines how much the text area will be expanded, the larger the value, the larger the expansion area | float|None |
|
None |
text_rec_score_thresh |
Text recognition threshold, text results with scores greater than this threshold will be retained | float|None |
|
None |
use_table_cells_ocr_results |
Whether to enable Table-Cells-OCR mode, when not enabled, use global OCR result to fill to HTML table, when enabled, do OCR cell by cell and fill to HTML table (it will increase the time consuming). Both of them perform differently in different scenarios, please choose according to the actual situation. | bool |
|
(3) Process the prediction results. Each sample's prediction result is represented as a corresponding Result object, and supports operations such as printing, saving as an image, saving as an xlsx file, saving as an HTML file, and saving as a json file.
| Method | Description | Parameter | Type | Parameter Description | Default Value |
|---|---|---|---|---|---|
print() |
Print the result to the terminal | format_json |
bool |
Whether to format the output content using JSON indentation |
True |
indent |
int |
Specify the indentation level to beautify the output JSON data and make it more readable. Only effective when format_json is True |
4 | ||
ensure_ascii |
bool |
Control whether to escape non-ASCII characters to Unicode. When set to True, all non-ASCII characters will be escaped; False retains the original characters. Only effective when format_json is True |
False |
||
save_to_json() |
Save the result as a JSON file | save_path |
str |
The path where the file will be saved. If it is a directory, the saved file name will match the input file name | None |
indent |
int |
Specify the indentation level to beautify the output JSON data and make it more readable. Only effective when format_json is True |
4 | ||
ensure_ascii |
bool |
Control whether to escape non-ASCII characters to Unicode. When set to True, all non-ASCII characters will be escaped; False retains the original characters. Only effective when format_json is True |
False |
||
save_to_img() |
Save the result as an image file | save_path |
str |
The path where the file will be saved, supporting both directory and file paths | None |
save_to_xlsx() |
Save the result as an xlsx file | save_path |
str |
The path where the file will be saved, supporting both directory and file paths | None |
save_to_html() |
Save the result as an html file | save_path |
str |
The path where the file will be saved, supporting both directory and file paths | None |
-
Calling the
print()method will print the result to the terminal, and the content printed to the terminal is explained as follows:-
input_path:(str)The input path of the image to be predicted -
page_index:(Union[int, None])If the input is a PDF file, it indicates which page of the PDF is currently being processed; otherwise, it isNone -
model_settings:(Dict[str, bool])Model parameters required for the pipeline configurationuse_doc_preprocessor:(bool)Controls whether to enable the document preprocessor sub-linedoc_preprocessor_res:(Dict[str, Union[str, Dict[str, bool], int]])Output result of the document preprocessor sub-line. It exists only whenuse_doc_preprocessor=True
input_path:(Union[str, None])The image path accepted by the image preprocessor sub-line. When the input isnumpy.ndarray, it is saved asNonemodel_settings:(Dict)Model configuration parameters for the preprocessor sub-lineuse_doc_orientation_classify:(bool)Controls whether to enable document orientation classificationuse_doc_unwarping:(bool)Controls whether to enable document warping correction
angle:(int)The prediction result of document orientation classification. When enabled, the values are [0,1,2,3], corresponding to [0°,90°,180°,270°]; when not enabled, it is -1
-
dt_polys:(List[numpy.ndarray])A list of polygon boxes for text detection. Each detection box is represented by a numpy array of four vertex coordinates, with a shape of (4, 2) and a data type of int16 -
dt_scores:(List[float])A list of confidence scores for text detection boxes -
text_det_params:(Dict[str, Dict[str, int, float]])Configuration parameters for the text detection modulelimit_side_len:(int)The side length limit value during image preprocessinglimit_type:(str)The processing method for the side length limitthresh:(float)The confidence threshold for text pixel classificationbox_thresh:(float)The confidence threshold for text detection boxesunclip_ratio:(float)The expansion ratio for text detection boxestext_type:(str)The type of text detection, currently fixed as "general"
-
text_rec_score_thresh:(float)The filtering threshold for text recognition results -
rec_texts:(List[str])A list of text recognition results, containing only texts with confidence scores exceedingtext_rec_score_thresh -
rec_scores:(List[float])A list of confidence scores for text recognition, filtered bytext_rec_score_thresh -
rec_polys:(List[numpy.ndarray])A list of text detection boxes after confidence filtering, in the same format asdt_polys -
rec_boxes:(numpy.ndarray)An array of rectangular bounding boxes for detection boxes, with a shape of (n, 4) and a dtype of int16. Each row represents the coordinates [x_min, y_min, x_max, y_max] of a rectangular box, where (x_min, y_min) is the top-left corner and (x_max, y_max) is the bottom-right corner
-
-
Calling the
save_to_json()method will save the above content to the specifiedsave_path. If it is a directory, the saved path will besave_path/{your_img_basename}.json; if it is a file, it will be saved directly to that file. Since JSON files do not support saving numpy arrays, thenumpy.arraytype will be converted to a list format. - Calling the
save_to_img()method will save the visualization results to the specifiedsave_path. If it is a directory, the saved path will besave_path/{your_img_basename}_ocr_res_img.{your_img_extension}; if it is a file, it will be saved directly to that file. (The pipeline usually contains many result images, so it is not recommended to specify a specific file path directly, otherwise multiple images will be overwritten and only the last one will be retained) - Calling the
save_to_html()method will save the above content to the specifiedsave_path. If it is a directory, the saved path will besave_path/{your_img_basename}.html; if it is a file, it will be saved directly to that file. In the general table recognition pipeline, the HTML form of the table in the image will be written to the specified HTML file. -
Calling the
save_to_xlsx()method will save the above content to the specifiedsave_path. If it is a directory, the saved path will besave_path/{your_img_basename}.xlsx; if it is a file, it will be saved directly to that file. In the general table recognition pipeline, the Excel table form of the table in the image will be written to the specified xlsx file. -
In addition, it also supports obtaining visualized images with results and prediction results through attributes, as follows:
| Attribute | Attribute Description |
|---|---|
json |
Get the prediction result in json format |
img |
Get the visualized image in dict format |
- The prediction result obtained through the
jsonattribute is data of the dict type, and its content is consistent with the content saved by calling thesave_to_json()method. - The prediction result returned by the
imgattribute is data of the dictionary type. The keys aretable_res_img,ocr_res_img,layout_res_img, andpreprocessed_img, and the corresponding values are fourImage.Imageobjects, in order: the visualized image of table recognition results, the visualized image of OCR results, the visualized image of layout area detection results, and the visualized image of image preprocessing. If a sub-module is not used, the corresponding result image will not be included in the dictionary.
In addition, you can obtain the configuration file for the general table recognition pipeline and load the configuration file for prediction. You can execute the following command to save the result in my_path:
If you have obtained the configuration file, you can customize the settings for the general table recognition pipeline. You just need to modify the value of the pipeline parameter in the create_pipeline method to the path of the pipeline configuration file. The example is as follows:
from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="./my_path/table_recognition.yaml")
output = pipeline.predict(
input="table_recognition.jpg",
use_doc_orientation_classify=False,
use_doc_unwarping=False,
)
for res in output:
res.print()
res.save_to_img("./output/")
res.save_to_xlsx("./output/")
res.save_to_html("./output/")
res.save_to_json("./output/")
Note: The parameters in the configuration file are the initialization parameters for the pipeline. If you want to change the general table recognition pipeline initialization parameters, you can directly modify the parameters in the configuration file and load the configuration file for prediction. At the same time, CLI prediction also supports passing in a configuration file, and you can specify the path of the configuration file with --pipeline.
3. Development Integration/Deployment¶
If the pipeline meets your requirements for inference speed and accuracy, you can directly proceed with development integration/deployment.
If you need to apply the pipeline directly in your Python project, you can refer to the example code in 2.2 Python Script Method.
In addition, PaddleX also provides three other deployment methods, which are detailed as follows:
🚀 High-Performance Inference: In actual production environments, many applications have strict performance requirements (especially response speed) for deployment strategies to ensure efficient system operation and smooth user experience. To this end, PaddleX provides a high-performance inference plugin, which aims to deeply optimize the performance of model inference and pre/post-processing to significantly speed up the end-to-end process. For detailed high-performance inference procedures, please refer to the PaddleX High-Performance Inference Guide.
☁️ Serving Deployment: Serving Deployment is a common form of deployment in actual production environments. By encapsulating inference functions as services, clients can access these services through network requests to obtain inference results. PaddleX supports multiple pipeline serving deployment solutions. For detailed pipeline serving deployment procedures, please refer to the PaddleX Serving Deployment Guide.
Below are the API references for basic serving deployment and multi-language service invocation examples:
API Reference
For the main operations provided by the service:
- The HTTP request method is POST.
- Both the request body and response body are JSON data (JSON objects).
- When the request is processed successfully, the response status code is
200, and the attributes of the response body are as follows:
| Name | Type | Meaning |
|---|---|---|
logId |
string |
The UUID of the request. |
errorCode |
integer |
Error code. Fixed as 0. |
errorMsg |
string |
Error message. Fixed as "Success". |
result |
object |
The result of the operation. |
- When the request is not processed successfully, the attributes of the response body are as follows:
| Name | Type | Meaning |
|---|---|---|
logId |
string |
The UUID of the request. |
errorCode |
integer |
Error code. Same as the response status code. |
errorMsg |
string |
Error message. |
The main operations provided by the service are as follows:
infer
Locate and recognize tables in the image.
POST /table-recognition
- The properties of the request body are as follows:
| Name | Type | Description | Required |
|---|---|---|---|
file |
string |
The URL of image files (including TIFF; multi-page TIFF is processed page by page) or PDF file accessible by the server, or the Base64-encoded content of the above file types. By default, for PDF or multi-page TIFF files exceeding 10 pages, only the first 10 pages will be processed. To remove the page limit, please add the following configuration to the pipeline configuration file: |
Yes |
fileType |
integer | null |
The file type. 0 indicates a PDF file, and 1 indicates an image file. If this attribute is missing in the request body, the file type will be inferred based on the URL. |
No |
useDocOrientationClassify |
boolean | null |
Please refer to the description of the use_doc_orientation_classify parameter of the pipeline object's predict method. |
No |
useDocUnwarping |
boolean | null |
Please refer to the description of the use_doc_unwarping parameter of the pipeline object's predict method. |
No |
useLayoutDetection |
boolean | null |
Please refer to the description of the use_layout_detection parameter of the pipeline object's predict method. |
No |
useOcrModel |
boolean | null |
Please refer to the description of the use_ocr_model parameter of the pipeline object's predict method. |
No |
layoutThreshold |
number | object | null |
Please refer to the description of the layout_threshold parameter of the pipeline object's predict method. |
No |
layoutNms |
boolean | null |
Please refer to the description of the layout_nms parameter of the pipeline object's predict method. |
No |
layoutUnclipRatio |
number | array | null |
Please refer to the description of the layout_unclip_ratio parameter of the pipeline object's predict method. |
No |
layoutMergeBboxesMode |
string | null |
Please refer to the description of the layout_merge_bboxes_mode parameter of the pipeline object's predict method. |
No |
textDetLimitSideLen |
integer | null |
Please refer to the description of the text_det_limit_side_len parameter of the pipeline object's predict method. |
No |
textDetLimitType |
string | null |
Please refer to the description of the text_det_limit_type parameter of the pipeline object's predict method. |
No |
textDetThresh |
number | null |
Please refer to the description of the text_det_thresh parameter of the pipeline object's predict method. |
No |
textDetBoxThresh |
number | null |
Please refer to the description of the text_det_box_thresh parameter of the pipeline object's predict method. |
No |
textDetUnclipRatio |
number | null |
Please refer to the description of the text_det_unclip_ratio parameter of the pipeline object's predict method. |
No |
textRecScoreThresh |
number | null |
Please refer to the description of the text_rec_score_thresh parameter of the pipeline object's predict method. |
No |
useOcrResultsWithTableCells |
boolean |
Please refer to the description of the use_ocr_results_with_table_cells parameter of the pipeline object's predict method. |
No |
visualize |
boolean | null |
Whether to return the final visualization image and intermediate images during the processing.
For example, adding the following setting to the pipeline config file: visualize parameter in the request.If neither the request body nor the configuration file is set (If visualize is set to null in the request and not defined in the configuration file), the image is returned by default.
|
No |
- When the request is processed successfully, the
resultin the response body has the following properties:
| Name | Type | Meaning |
|---|---|---|
tableRecResults |
object |
The table recognition results. The array length is 1 (for image input) or the actual number of document pages processed (for PDF input). For PDF input, each element in the array represents the result of each page actually processed in the PDF file. |
dataInfo |
object |
Information about the input data. |
Image fields in the element schema below (e.g. outputImages, inputImage) are returned inline as Base64 strings by default; when the server is configured to return URLs, those values become pre-signed URLs while the field types remain unchanged. See the "Returning Binary Content as URLs" section of the Serving Deployment Guide for configuration.
Each element in tableRecResults is an object with the following properties:
| Name | Type | Meaning |
|---|---|---|
prunedResult |
object |
A simplified version of the res field in the JSON representation of the result generated by the predict method of the production object, with the input_path and the page_index fields removed. |
outputImages |
object | null |
Refer to the description of the img attribute of the production prediction results. The image is in JPEG format and encoded in Base64 by default; returned as a pre-signed URL when URL-return mode is enabled. |
inputImage |
string | null |
The input image. The image is in JPEG format and encoded in Base64 by default; returned as a pre-signed URL when URL-return mode is enabled. |
Multi-language Service Call Example
Python
import base64
import requests
API_URL = "http://localhost:8080/table-recognition"
file_path = "./demo.jpg"
with open(file_path, "rb") as file:
file_bytes = file.read()
file_data = base64.b64encode(file_bytes).decode("ascii")
payload = {"file": file_data, "fileType": 1}
response = requests.post(API_URL, json=payload)
assert response.status_code == 200
result = response.json()["result"]
for i, res in enumerate(result["tableRecResults"]):
print(res["prunedResult"])
for img_name, img in res["outputImages"].items():
img_path = f"{img_name}_{i}.jpg"
with open(img_path, "wb") as f:
f.write(base64.b64decode(img))
print(f"Output image saved at {img_path}")
C++
#include <iostream>
#include <fstream>
#include <vector>
#include <string>
#include "cpp-httplib/httplib.h" // https://github.com/Huiyicc/cpp-httplib
#include "nlohmann/json.hpp" // https://github.com/nlohmann/json
#include "base64.hpp" // https://github.com/tobiaslocker/base64
int main() {
httplib::Client client("localhost", 8080);
const std::string filePath = "./demo.jpg";
std::ifstream file(filePath, std::ios::binary | std::ios::ate);
if (!file) {
std::cerr << "Error opening file." << std::endl;
return 1;
}
std::streamsize size = file.tellg();
file.seekg(0, std::ios::beg);
std::vector buffer(size);
if (!file.read(buffer.data(), size)) {
std::cerr << "Error reading file." << std::endl;
return 1;
}
std::string bufferStr(buffer.data(), static_cast(size));
std::string encodedFile = base64::to_base64(bufferStr);
nlohmann::json jsonObj;
jsonObj["file"] = encodedFile;
jsonObj["fileType"] = 1;
auto response = client.Post("/table-recognition", jsonObj.dump(), "application/json");
if (response && response->status == 200) {
nlohmann::json jsonResponse = nlohmann::json::parse(response->body);
auto result = jsonResponse["result"];
if (!result.is_object() || !result["tableRecResults"].is_array()) {
std::cerr << "Unexpected response structure." << std::endl;
return 1;
}
for (size_t i = 0; i < result["tableRecResults"].size(); ++i) {
auto tableRecResult = result["tableRecResults"][i];
std::cout << tableRecResult["prunedResult"] << std::endl;
if (tableRecResult["outputImages"].is_object()) {
for (auto& img : tableRecResult["outputImages"].items()) {
std::string imgName = img.key();
std::string encodedImage = img.value();
std::string decodedImage = base64::from_base64(encodedImage);
std::string imgPath = imgName + "_" + std::to_string(i) + ".jpg";
std::ofstream outputImage(imgPath, std::ios::binary);
if (outputImage.is_open()) {
outputImage.write(decodedImage.c_str(), static_cast(decodedImage.size()));
outputImage.close();
std::cout << "Output image saved at " << imgPath << std::endl;
} else {
std::cerr << "Unable to open file for writing: " << imgPath << std::endl;
}
}
}
}
} else {
std::cerr << "Failed to send HTTP request." << std::endl;
if (response) {
std::cerr << "HTTP status code: " << response->status << std::endl;
std::cerr << "Response body: " << response->body << std::endl;
}
return 1;
}
return 0;
}
Java
import okhttp3.*;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.node.ObjectNode;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Base64;
public class Main {
public static void main(String[] args) throws IOException {
String API_URL = "http://localhost:8080/table-recognition";
String imagePath = "./demo.jpg";
File file = new File(imagePath);
byte[] fileContent = java.nio.file.Files.readAllBytes(file.toPath());
String base64Image = Base64.getEncoder().encodeToString(fileContent);
ObjectMapper objectMapper = new ObjectMapper();
ObjectNode payload = objectMapper.createObjectNode();
payload.put("file", base64Image);
payload.put("fileType", 1);
OkHttpClient client = new OkHttpClient();
MediaType JSON = MediaType.get("application/json; charset=utf-8");
RequestBody body = RequestBody.create(JSON, payload.toString());
Request request = new Request.Builder()
.url(API_URL)
.post(body)
.build();
try (Response response = client.newCall(request).execute()) {
if (response.isSuccessful()) {
String responseBody = response.body().string();
JsonNode root = objectMapper.readTree(responseBody);
JsonNode result = root.get("result");
JsonNode tableRecResults = result.get("tableRecResults");
for (int i = 0; i < tableRecResults.size(); i++) {
JsonNode item = tableRecResults.get(i);
JsonNode prunedResult = item.get("prunedResult");
System.out.println("Pruned Result [" + i + "]: " + prunedResult.toString());
JsonNode outputImages = item.get("outputImages");
outputImages.fieldNames().forEachRemaining(imgName -> {
String imgBase64 = outputImages.get(imgName).asText();
byte[] imgBytes = Base64.getDecoder().decode(imgBase64);
String imgPath = "output_" + imgName + ".jpg";
try (FileOutputStream fos = new FileOutputStream(imgPath)) {
fos.write(imgBytes);
System.out.println("Saved image to: " + imgPath);
} catch (IOException e) {
e.printStackTrace();
}
});
}
} else {
System.err.println("Request failed with HTTP code: " + response.code());
}
}
}
}
Go
package main
import (
"bytes"
"encoding/base64"
"encoding/json"
"fmt"
"io/ioutil"
"net/http"
)
func main() {
API_URL := "http://localhost:8080/table-recognition"
filePath := "./demo.jpg"
fileBytes, err := ioutil.ReadFile(filePath)
if err != nil {
fmt.Printf("Error reading file: %v\n", err)
return
}
fileData := base64.StdEncoding.EncodeToString(fileBytes)
payload := map[string]interface{}{
"file": fileData,
"fileType": 1,
}
payloadBytes, err := json.Marshal(payload)
if err != nil {
fmt.Printf("Error marshaling payload: %v\n", err)
return
}
client := &http.Client{}
req, err := http.NewRequest("POST", API_URL, bytes.NewBuffer(payloadBytes))
if err != nil {
fmt.Printf("Error creating request: %v\n", err)
return
}
req.Header.Set("Content-Type", "application/json")
res, err := client.Do(req)
if err != nil {
fmt.Printf("Error sending request: %v\n", err)
return
}
defer res.Body.Close()
if res.StatusCode != http.StatusOK {
fmt.Printf("Unexpected status code: %d\n", res.StatusCode)
return
}
body, err := ioutil.ReadAll(res.Body)
if err != nil {
fmt.Printf("Error reading response body: %v\n", err)
return
}
type TableRecResult struct {
PrunedResult map[string]interface{} `json:"prunedResult"`
OutputImages map[string]string `json:"outputImages"`
InputImage *string `json:"inputImage"`
}
type Response struct {
Result struct {
TableRecResults []TableRecResult `json:"tableRecResults"`
DataInfo interface{} `json:"dataInfo"`
} `json:"result"`
}
var respData Response
if err := json.Unmarshal(body, &respData); err != nil {
fmt.Printf("Error unmarshaling response: %v\n", err)
return
}
for i, res := range respData.Result.TableRecResults {
fmt.Printf("Result %d - prunedResult: %+v\n", i, res.PrunedResult)
for imgName, imgData := range res.OutputImages {
imgBytes, err := base64.StdEncoding.DecodeString(imgData)
if err != nil {
fmt.Printf("Error decoding image %s_%d: %v\n", imgName, i, err)
continue
}
filename := fmt.Sprintf("%s_%d.jpg", imgName, i)
if err := ioutil.WriteFile(filename, imgBytes, 0644); err != nil {
fmt.Printf("Error saving image %s: %v\n", filename, err)
continue
}
fmt.Printf("Saved image to %s\n", filename)
}
}
}
C#
using System;
using System.IO;
using System.Net.Http;
using System.Text;
using System.Threading.Tasks;
using Newtonsoft.Json.Linq;
class Program
{
static readonly string API_URL = "http://localhost:8080/table-recognition";
static readonly string inputFilePath = "./demo.jpg";
static async Task Main(string[] args)
{
var httpClient = new HttpClient();
byte[] fileBytes = File.ReadAllBytes(inputFilePath);
string fileData = Convert.ToBase64String(fileBytes);
var payload = new JObject
{
{ "file", fileData },
{ "fileType", 1 }
};
var content = new StringContent(payload.ToString(), Encoding.UTF8, "application/json");
HttpResponseMessage response = await httpClient.PostAsync(API_URL, content);
response.EnsureSuccessStatusCode();
string responseBody = await response.Content.ReadAsStringAsync();
JObject jsonResponse = JObject.Parse(responseBody);
JArray tableRecResults = (JArray)jsonResponse["result"]["tableRecResults"];
for (int i = 0; i < tableRecResults.Count; i++)
{
var res = tableRecResults[i];
Console.WriteLine($"[{i}] prunedResult:\n{res["prunedResult"]}");
JObject outputImages = res["outputImages"] as JObject;
if (outputImages != null)
{
foreach (var img in outputImages)
{
string imgName = img.Key;
string base64Img = img.Value?.ToString();
if (!string.IsNullOrEmpty(base64Img))
{
string imgPath = $"{imgName}_{i}.jpg";
byte[] imageBytes = Convert.FromBase64String(base64Img);
File.WriteAllBytes(imgPath, imageBytes);
Console.WriteLine($"Output image saved at {imgPath}");
}
}
}
}
}
}
Node.js
const axios = require('axios');
const fs = require('fs');
const path = require('path');
const API_URL = 'http://localhost:8080/table-recognition';
const inputImagePath = './demo.jpg';
function encodeImageToBase64(filePath) {
const bitmap = fs.readFileSync(filePath);
return Buffer.from(bitmap).toString('base64');
}
async function callTableRecognitionAPI() {
const payload = {
file: encodeImageToBase64(inputImagePath),
fileType: 1
};
try {
const response = await axios.post(API_URL, payload, {
headers: {
'Content-Type': 'application/json'
},
maxBodyLength: Infinity
});
const results = response.data.result.tableRecResults;
results.forEach((res, index) => {
console.log(`Result [${index}] prunedResult:\n`, res.prunedResult);
const outputImages = res.outputImages || {};
Object.entries(outputImages).forEach(([imgName, base64Img]) => {
const outputPath = `${imgName}_${index}.jpg`;
fs.writeFileSync(outputPath, Buffer.from(base64Img, 'base64'));
console.log(`Saved image: ${outputPath}`);
});
});
} catch (error) {
console.error('API request failed:', error.message);
}
}
callTableRecognitionAPI();
PHP
<?php
$API_URL = "http://localhost:8080/table-recognition";
$image_path = "./demo.jpg";
$image_data = base64_encode(file_get_contents($image_path));
$payload = array(
"file" => $image_data,
"fileType" => 1
);
$ch = curl_init($API_URL);
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_POSTFIELDS, json_encode($payload));
curl_setopt($ch, CURLOPT_HTTPHEADER, array('Content-Type: application/json'));
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$response = curl_exec($ch);
curl_close($ch);
$result_array = json_decode($response, true);
$results = $result_array["result"]["tableRecResults"];
foreach ($results as $i => $item) {
echo "[$i] prunedResult:\n";
print_r($item["prunedResult"]);
if (!empty($item["outputImages"])) {
foreach ($item["outputImages"] as $img_name => $base64_img) {
$img_path = $img_name . "_" . $i . ".jpg";
file_put_contents($img_path, base64_decode($base64_img));
echo "Output image saved at $img_path\n";
}
} else {
echo "No outputImages found for item $i\n";
}
}
?>
📱 On-Device Deployment: Edge deployment is a method of placing computing and data processing capabilities on the user's device itself, allowing the device to process data directly without relying on remote servers. PaddleX supports deploying models on edge devices such as Android. For detailed edge deployment procedures, please refer to the PaddleX On-Device Deployment Guide. You can choose the appropriate deployment method for your model pipeline according to your needs, and then proceed with the subsequent AI application integration.
4. Custom Development¶
If the default model weights provided by the general table recognition pipeline are not satisfactory in terms of accuracy or speed in your scenario, you can try to further fine-tune the existing model using your own specific domain or application scenario data to improve the recognition performance of the general table recognition pipeline in your scenario.
4.1 Model Fine-tuning¶
Since the general table recognition pipeline consists of several modules, if the performance of the model pipeline does not meet expectations, the issue may originate from any one of these modules. You can analyze the images with poor recognition results to determine which module is problematic, and then refer to the corresponding fine-tuning tutorial links in the table below for model fine-tuning.
| Scenario | Fine-tuning Module | Fine-tuning Reference Link |
|---|---|---|
| Table structure recognition error or cell positioning error | Table Structure Recognition Module | Link |
| Failed to detect the table area | Layout Area Detection Module | Link |
| Text detection omission | Text Detection Module | Link |
| Text content is inaccurate | Text Recognition Module | Link |
| Whole image rotation correction is inaccurate | Document Image Orientation Classification Module | Link |
| Image distortion correction is inaccurate | Text Image Correction Module | Fine-tuning not supported yet |
4.2 Model Application¶
After you complete fine-tuning with your private dataset, you will obtain a local model weight file.
If you need to use the fine-tuned model weights, simply modify the production configuration file by replacing the local path of the fine-tuned model weights to the corresponding position in the production configuration file.
SubModules:
LayoutDetection:
module_name: layout_detection
model_name: PicoDet_layout_1x_table
model_dir: null # Replace with fine-tuned model weight paths
TableStructureRecognition:
module_name: table_structure_recognition
model_name: SLANet_plus
model_dir: null # Replace with fine-tuned model weight paths
SubPipelines:
DocPreprocessor:
pipeline_name: doc_preprocessor
use_doc_orientation_classify: True
use_doc_unwarping: True
SubModules:
DocOrientationClassify:
module_name: doc_text_orientation
model_name: PP-LCNet_x1_0_doc_ori
model_dir: null # Replace with fine-tuned model weight paths
DocUnwarping:
module_name: image_unwarping
model_name: UVDoc
model_dir: null
GeneralOCR:
pipeline_name: OCR
text_type: general
use_doc_preprocessor: False
use_textline_orientation: False
SubModules:
TextDetection:
module_name: text_detection
model_name: PP-OCRv5_server_det
model_dir: null # Replace with fine-tuned model weight paths
limit_side_len: 960
limit_type: max
max_side_limit: 4000
thresh: 0.3
box_thresh: 0.4
unclip_ratio: 1.5
TextRecognition:
module_name: text_recognition
model_name: PP-OCRv5_server_rec
model_dir: null # Replace with fine-tuned model weight paths
batch_size: 1
score_thresh: 0
Subsequently, refer to the command line method or Python script method in 2.2 Local Experience to load the modified production configuration file.
5. Multi-Hardware Support¶
PaddleX supports a variety of mainstream hardware devices such as NVIDIA GPU, Kunlunxin XPU, Ascend NPU, and Cambricon MLU. Simply modify the --device parameter to seamlessly switch between different hardware.
For example, if you use Ascend NPU for table recognition production inference, the CLI command is:
paddlex --pipeline table_recognition \
--use_doc_orientation_classify=False \
--use_doc_unwarping=False \
--input table_recognition.jpg \
--save_path ./output \
--device npu:0
Of course, you can also specify the hardware device when calling create_pipeline() or predict() in the Python script.
If you want to use the universal table recognition pipeline on a wider range of hardware, please refer to the PaddleX Multi-Device Usage Guide.