3D Multi-modal Fusion Detection Pipeline Usage Tutorial¶
1. Introduction to 3D Multi-modal Fusion Detection Pipeline¶
The 3D multi-modal fusion detection pipeline supports input from multiple sensors (LiDAR, surround RGB cameras, etc.), processes the data using deep learning methods, and outputs information such as the position, shape, orientation, and category of objects in three-dimensional space. It has a wide range of applications in fields such as autonomous driving, robot navigation, and industrial automation.
BEVFusion is a multi-modal 3D object detection model that fuses surround camera images and LiDAR point cloud data into a unified Bird's Eye View (BEV) representation, aligning and fusing features from different sensors, overcoming the limitations of a single sensor, and significantly improving detection accuracy and robustness. It is suitable for complex scenarios such as autonomous driving.

Please note that the 3D multi-modal fusion detection pipeline currently does not support Python 3.12 or above.
The 3D multi-modal fusion detection pipeline includes a 3D multi-modal fusion detection module,which contains a BEVFusion model. We provide benchmark data for this model:
The inference time only includes the model inference time and does not include the time for pre- or post-processing.
3D Multi-modal Fusion Detection Module:
| Model | Model Download Link | mAP(%) | NDS | Description |
|---|---|---|---|---|
| BEVFusion | Inference Model/Training Model | 53.9 | 60.9 | BEVFusion is a multi-modal fusion detection model from a BEV perspective. It uses two branches to process data from different modalities, obtaining features for LiDAR and camera in the BEV perspective. The camera branch uses the LSS bottom-up approach to explicitly generate image BEV features, while the LiDAR branch uses a classic point cloud detection network. Finally, the BEV features from both modalities are aligned and fused, applied to the detection head or segmentation head. |
Test Environment Description:
- Performance Test Environment
- Test Dataset:nuscenes validation set
- Hardware Configuration:
- GPU: NVIDIA Tesla T4
- CPU: Intel Xeon Gold 6271C @ 2.60GHz
- Software Environment:
- Ubuntu 20.04 / CUDA 11.8 / cuDNN 8.9 / TensorRT 8.6.1.6
- paddlepaddle 3.0.0 / paddlex 3.0.3
</li>
<li><b>Inference Mode Description</b></li>
| Mode | GPU Configuration | CPU Configuration | Acceleration Technology Combination |
|---|---|---|---|
| Normal Mode | FP32 Precision / No TRT Acceleration | FP32 Precision / 8 Threads | PaddleInference |
| High-Performance Mode | Optimal combination of pre-selected precision types and acceleration strategies | FP32 Precision / 8 Threads | Pre-selected optimal backend (Paddle/OpenVINO/TRT, etc.) |
2. Quick Start¶
The pre-trained model pipelines provided by PaddleX allow for quick experimentation. You can experience the effects of the 3D multi-modal fusion detection pipeline online or locally using the command line or Python.
2.1 Online Experience¶
Online experience is currently not supported.
2.2 Local Experience¶
❗ Before using the 3D multi-modal fusion detection pipeline locally, please ensure you have completed the PaddleX wheel package installation according to the PaddleX Installation Tutorial. If you wish to selectively install dependencies, please refer to the relevant instructions in the installation guide. The dependency group corresponding to this pipeline is
cv.
Demo dataset download: You can use the following command to download the demo dataset to a specified folder:
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/data/nuscenes_demo.tar -P ./data
tar -xf ./data/nuscenes_demo.tar -C ./data/
2.2.1 Command Line Experience¶
You can quickly experience the 3D multi-modal fusion detection pipeline with a single command. Use the test file,and --input replace with the local path for prediction.
--pipeline: The name of the pipeline, here it is the 3D multi-modal fusion detection pipeline.
--input: The input path to the .tar file containing image and lidar data to be processed. 3D multi-modal fusion detection pipeline is a multi-input pipeline depending on images, pointclouds and transition matrix information. Tar file contains "samples" directory with all images and pointclouds data, "sweeps" directories with pointclouds data of relative frames and nuscnes_infos_val.pkl file containing relative data path from "samples" and "sweeps" directories and transition matrix information.
--device: The GPU index to be used (e.g., gpu:0 means using the 0th GPU, gpu:1,2 means using the 1st and 2nd GPUs), or you can choose to use CPU (--device cpu).
After running, the results will be printed on the terminal as follows:
{"res":
{
'input_path': 'samples/LIDAR_TOP/n015-2018-10-08-15-36-50+0800__LIDAR_TOP__1538984253447765.pcd.bin',
'sample_id': 'b4ff30109dd14c89b24789dc5713cf8c',
'input_img_paths': [
'samples/CAM_FRONT_LEFT/n015-2018-10-08-15-36-50+0800__CAM_FRONT_LEFT__1538984253404844.jpg',
'samples/CAM_FRONT/n015-2018-10-08-15-36-50+0800__CAM_FRONT__1538984253412460.jpg',
'samples/CAM_FRONT_RIGHT/n015-2018-10-08-15-36-50+0800__CAM_FRONT_RIGHT__1538984253420339.jpg',
'samples/CAM_BACK_RIGHT/n015-2018-10-08-15-36-50+0800__CAM_BACK_RIGHT__1538984253427893.jpg',
'samples/CAM_BACK/n015-2018-10-08-15-36-50+0800__CAM_BACK__1538984253437525.jpg',
'samples/CAM_BACK_LEFT/n015-2018-10-08-15-36-50+0800__CAM_BACK_LEFT__1538984253447423.jpg'
]
"boxes_3d": [
[
14.5425386428833,
22.142045974731445,
-1.2903141975402832,
1.8441576957702637,
4.433370113372803,
1.7367216348648071,
6.367165565490723,
0.0036598597653210163,
-0.013568558730185032
]
],
"labels_3d": [
0
],
"scores_3d": [
0.9920279383659363
]
}
}
The meanings of the result parameters are as follows:
input_path: Indicates the path to the input point cloud data of the sample to be predicted.sample_id: Indicates the unique identifier of the input sample to be predicted.input_img_paths: Indicates the paths to the input image data of the sample to be predicted.boxes_3d: Represents all the predicted bounding box information for the 3D sample. Each bounding box information is a list of length 9, with each element representing:- 0: x-coordinate of the center point
- 1: y-coordinate of the center point
- 2: z-coordinate of the center point
- 3: Width of the detection box
- 4: Length of the detection box
- 5: Height of the detection box
- 6: Rotation angle
- 7: Velocity in the x-direction of the coordinate system
- 8: Velocity in the y-direction of the coordinate system
labels_3d: Represents the predicted categories corresponding to all the predicted bounding boxes of the 3D sample.scores_3d: Represents the confidence levels corresponding to all the predicted bounding boxes of the 3D sample.
2.2.2 Python Script Integration¶
- The above command line is for quick experience. Generally, in projects, integration through code is often required. You can complete quick inference of the pipeline with a few lines of code as follows:
from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="3d_bev_detection")
output = pipeline.predict("nuscenes_demo_infer.tar")
for res in output:
res.print() ## Print the structured output of the prediction
res.save_to_json("./output/") ## Save the results to a json file
res.visualize(save_path="./output/", show=True) ## 3D result visualization. If the runtime environment has a graphical interface, set `show=True`; otherwise, set it to `False`.
Note: 1、To visualize 3D detection results, you need to install the open3d package first. The installation command is as follows:
2、If the runtime environment does not have a graphical interface, visualization will not be possible, but the results will still be saved. You can run the script in an environment that supports a graphical interface to visualize the saved results: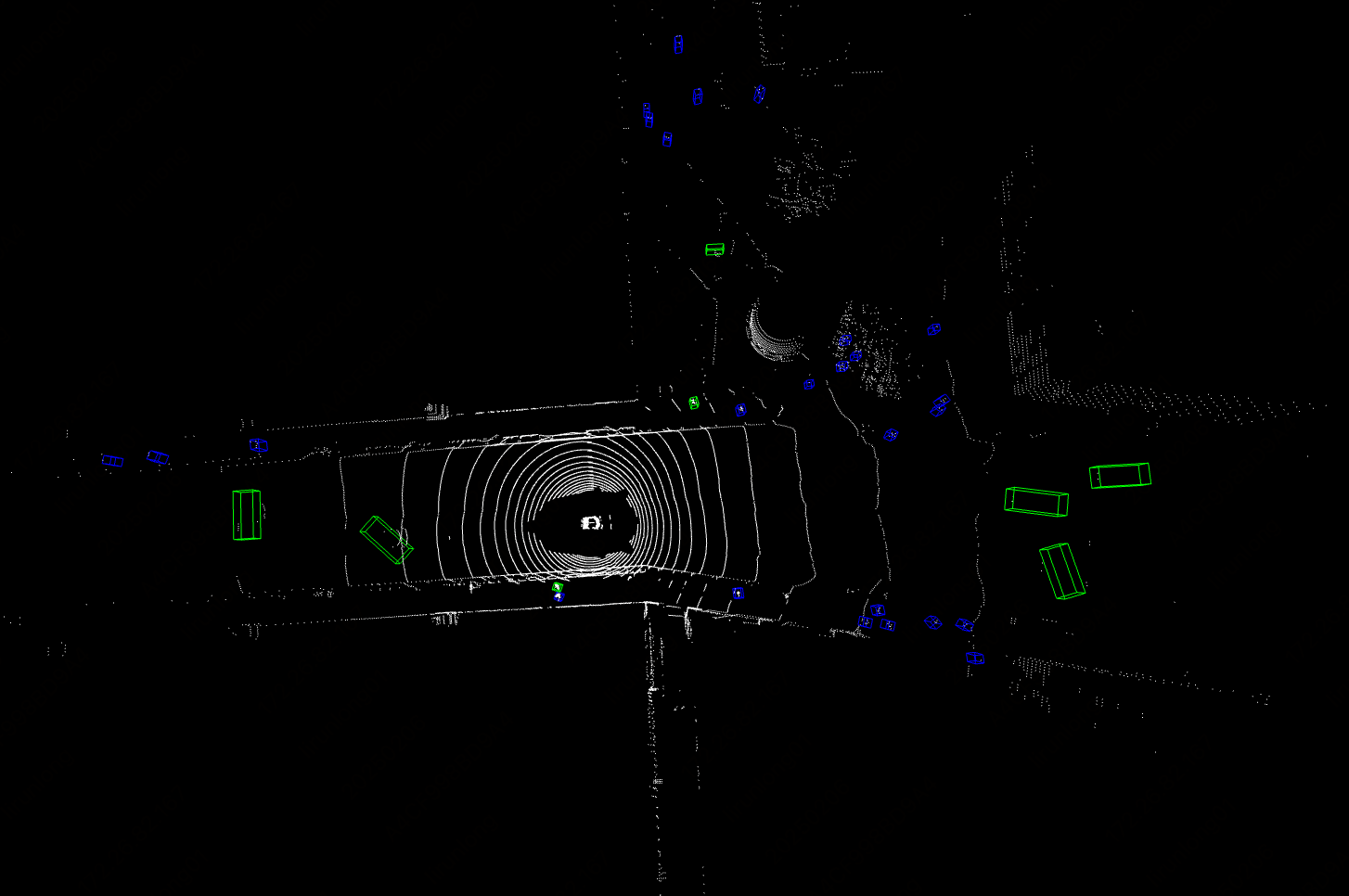
In the above Python script, the following steps are executed:
(1)Call create_pipeline to instantiate the 3D multi-modal fusion detection pipeline object. Specific parameter descriptions are as follows:
| Parameter | Parameter Description | Parameter Type | Default Value | |
|---|---|---|---|---|
pipeline |
The name of the pipeline or the path to the pipeline configuration file. If it is a pipeline name, it must be a pipeline supported by PaddleX. | str |
None | |
device |
The device for pipeline model inference. Supports: "gpu", "cpu". | str |
gpu |
|
use_hpip |
Whether to enable the high-performance inference plugin. If set to None, the setting from the configuration file or config will be used. |
bool |
None | None |
hpi_config |
High-performance inference configuration | dict | None |
None | None |
(2)Call the predict method of the 3D multi-modal fusion detection pipeline object for inference prediction: The predict method parameter is input, used to input data to be predicted, supporting multiple input methods. Specific examples are as follows:
| Parameter Type | Parameter Description |
|---|---|
| str | tar file path,e.g., /root/data/nuscenes_demo_infer.tar |
| list | List,list elements need to be data of the above type, e.g., ["/root/data/nuscenes_demo_infer1.tar", "/root/data/nuscenes_demo_infer2.tar"] |
Note: pkl files can be created according to the script.
(3)Call the predict method to obtain prediction results: The predict method is a generator, so prediction results need to be obtained through iteration. The predict method predicts data in batches, so the prediction results are represented as a list of prediction results.
(4)Process the prediction results: The prediction result for each sample is of dict type and supports printing or saving as a json file, as follows:
| Method | Description | Method Parameters |
|---|---|---|
| Print results to the terminal | - format_json:bool, whether to format the output content using json indentation, default is True;- indent:int, json formatting setting, only effective when format_json is True, default is 4;- ensure_ascii:bool, json formatting setting, only effective when format_json is True, default is False; |
|
| save_to_json | Save the results as a json format file | - save_path:str, the file path to save, when it is a directory, the saved file naming is consistent with the input file type naming;- indent:int, json formatting setting, default is 4;- ensure_ascii:bool, json formatting setting, default is False; |
Additionally, you can obtain the 3D multi-modal fusion detection pipeline configuration file and load it for prediction. You can execute the following command to save the result in my_path:
If you have obtained the configuration file, you can customize various configurations of the 3D multi-modal fusion detection pipeline. Simply modify the pipeline parameter value in the create_pipeline method to the path of the pipeline configuration file. An example is as follows:
from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="./my_path/3d_bev_detection.yaml")
output = pipeline.predict("nuscenes_demo_infer.tar")
for res in output:
res.print() ## Print the structured output of the prediction
res.save_to_json("./output/") ## Save the results to a json file
res.visualize(save_path="./output/", show=True) ## 3D result visualization. If the runtime environment has a graphical interface, set `show=True`; otherwise, set it to `False`.
Note: The parameters in the configuration file are pipeline initialization parameters. If you want to change the 3D multi-modal fusion detection pipeline initialization parameters, you can directly modify the parameters in the configuration file and load the configuration file for prediction. At the same time, CLI prediction also supports passing in a configuration file by specifying the path with --pipeline.
3. Development Integration/Deployment¶
If the 3D multi-modal fusion detection pipeline meets your requirements for inference speed and accuracy, you can proceed directly with development integration/deployment.
If you need to apply the general 3D multi-modal fusion detection pipeline directly to your Python project, you can refer to the example code in 2.2.2 Python Script Integration.
In addition, PaddleX also provides three other deployment methods, detailed as follows:
🚀 High-Performance Inference: In actual production environments, many applications have stringent performance indicators (especially response speed) for deployment strategies to ensure efficient system operation and smooth user experience. Therefore, PaddleX provides a high-performance inference plugin aimed at deeply optimizing model inference and pre/post-processing to achieve significant speedups in the end-to-end process. For detailed high-performance inference procedures, please refer to the PaddleX High-Performance Inference Guide.
☁️ Service Deployment: Service deployment is a common deployment form in actual production environments. By encapsulating inference functions as services, clients can access these services through network requests to obtain inference results. PaddleX supports multiple pipeline service deployment solutions. For detailed pipeline service deployment procedures, please refer to the PaddleX Service Deployment Guide.
API Reference
For the main operations provided by the service:
- The HTTP request method is POST.
- Both the request body and response body are JSON data (JSON objects).
- When the request is processed successfully, the response status code is
200, and the attributes of the response body are as follows:
| Name | Type | Meaning |
|---|---|---|
logId |
string |
The UUID of the request. |
errorCode |
integer |
Error code. Fixed as 0. |
errorMsg |
string |
Error message. Fixed as "Success". |
result |
object |
The result of the operation. |
- When the request is not processed successfully, the attributes of the response body are as follows:
| Name | Type | Meaning |
|---|---|---|
logId |
string |
The UUID of the request. |
errorCode |
integer |
Error code. Same as the response status code. |
errorMsg |
string |
Error message. |
The main operations provided by the service are as follows:
infer
Perform 3D multi-modal fusion detection.
POST /bev-3d-object-detection
- The attributes of the request body are as follows:
| Name | Type | Meaning | Required |
|---|---|---|---|
tar |
string |
The URL or path of the tar file accessible by the server. | Yes |
- When the request is processed successfully, the
resultin the response body has the following attributes:
| Name | Type | Meaning |
|---|---|---|
detectedObjects |
array |
Information about the location, category, and other details of the detected objects. |
Each element in detectedObjects is an object with the following attributes:
| Name | Type | Meaning |
|---|---|---|
bbox |
array |
A list of length 9: 0: x-coordinate of the center point, 1: y-coordinate of the center point, 2: z-coordinate of the center point, 3: width of the detection box, 4: length of the detection box, 5: height of the detection box, 6: rotation angle, 7: velocity in the x-direction of the coordinate system, 8: velocity in the y-direction of the coordinate system |
categoryId |
integer |
The category ID of the detected object. |
score |
number |
The score of the detected object. |
Multi-language Service Invocation Examples
Python
import base64
import requests
API_URL = "http://localhost:8080/bev-3d-object-detection" # Service URL
tar_path = "./nuscenes_demo_infer.tar"
with open(tar_path, "rb") as file:
tar_bytes = file.read()
tar_data = base64.b64encode(tar_bytes).decode("ascii")
payload = {"tar": tar_data}
# Call the API
response = requests.post(API_URL, json=payload)
# Process the response data
assert response.status_code == 200
result = response.json()["result"]
print("Detected objects:")
print(result["detectedObjects"])
📱 On-Device Deployment: Edge deployment is a method of placing computing and data processing functions on the user's device itself, allowing the device to process data directly without relying on remote servers. PaddleX supports deploying models on edge devices such as Android. For detailed edge deployment procedures, please refer to the PaddleX On-Device Deployment Guide.
You can choose an appropriate deployment method for your model pipeline based on your needs, and then proceed with subsequent AI application integration.
4. Custom Development¶
If the default model weights provided by the 3D multi-modal fusion detection pipeline do not meet your requirements for accuracy or speed in your scenario, you can attempt to further fine-tune the existing model using your own data from specific domains or application scenarios to improve the recognition performance of the 3D multi-modal fusion detection pipeline in your scenario.
4.1 Model Fine-Tuning¶
Refer to the Custom Development section in the 3D Multi-modal Fusion Detection Module Development Tutorial and use your private dataset to fine-tune the model.
4.2 Model Application¶
After completing fine-tuning training using your private dataset, you will obtain local model weight files.
If you need to use the fine-tuned model weights, simply modify the pipeline configuration file, replacing the local path of the fine-tuned 3D object detection model to the corresponding position in the pipeline configuration file:
......
Pipeline:
device: "gpu:0"
det_model: "BEVFusion" # Can be modified to the local path of the fine-tuned 3D object detection model
det_batch_size: 1
device: gpu
......
5. Multi-Hardware Support¶
PaddleX supports various mainstream hardware devices such as NVIDIA GPUs, Kunlun XPUs, Ascend NPUs, and Cambricon MLUs. Simply modify the --device parameter to achieve seamless switching between different hardware.
For example, when running the 3D multi-modal fusion detection pipeline in Python, to change the running device from an NVIDIA GPU to an Ascend NPU, you only need to modify the device in the script to npu:
from paddlex import create_pipeline
pipeline = create_pipeline(
pipeline="3d_bev_detection",
device="npu:0" # gpu:0 --> npu:0
)