PaddleX Object Detection Task Data Preparation Tutorial¶
This section will introduce how to use Labelme and PaddleLabel annotation tools to complete data annotation for single-model object detection tasks. Click the above links to install the annotation tools and view detailed usage instructions.
1. Annotation Data Examples¶

2. Labelme Annotation¶
2.1 Introduction to Labelme Annotation Tool¶
Labelme is a Python-based image annotation software with a graphical user interface. It can be used for tasks such as image classification, object detection, and image segmentation. For object detection annotation tasks, labels are stored as JSON files.
2.2 Labelme Installation¶
To avoid environment conflicts, it is recommended to install in a conda environment.
2.3 Labelme Annotation Process¶
2.3.1 Prepare Data for Annotation¶
- Create a root directory for the dataset, e.g.,
helmet. - Create an
imagesdirectory (must be namedimages) withinhelmetand store the images to be annotated in theimagesdirectory, as shown below:
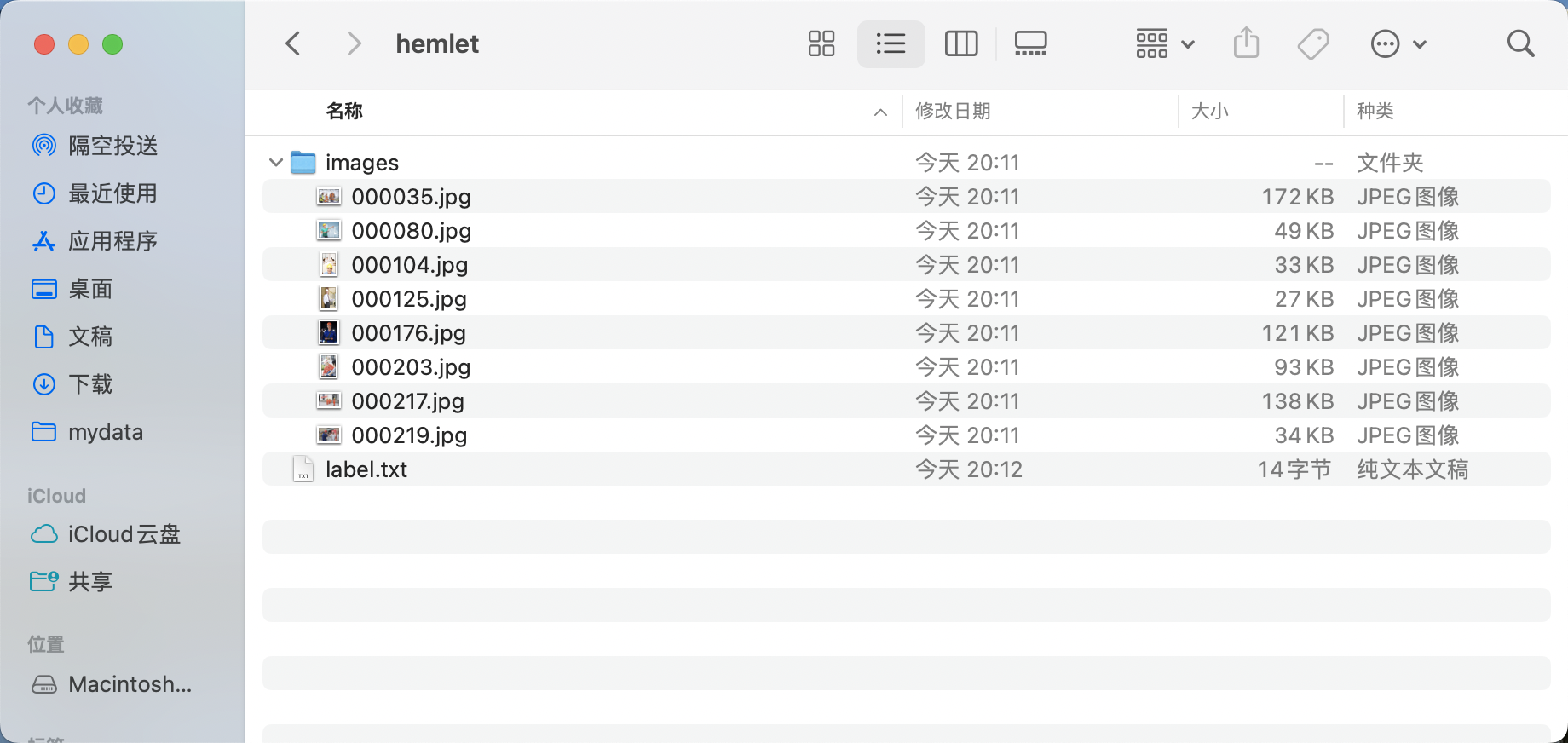 * Create a category label file
* Create a category label file label.txt in the helmet folder and write the categories of the dataset to be annotated, line by line. For example, for a helmet detection dataset, label.txt would look like this:

2.3.2 Start Labelme¶
Navigate to the root directory of the dataset to be annotated in the terminal and start the Labelme annotation tool:
flags creates classification labels for images, passing in the path to the labels.
* nodata stops storing image data in the JSON file.
* autosave enables automatic saving.
* output specifies the path for storing label files.
2.3.3 Begin Image Annotation¶
- After starting
Labelme, it will look like this:
 * Click "Edit" to select the annotation type.
* Click "Edit" to select the annotation type.
 * Choose to create a rectangular box.
* Choose to create a rectangular box.
 * Drag the crosshair to select the target area on the image.
* Drag the crosshair to select the target area on the image.
 * Click again to select the category of the target box.
* Click again to select the category of the target box.
 * After annotation, click Save. (If
* After annotation, click Save. (If output is not specified when starting Labelme, it will prompt to select a save path upon the first save. If autosave is enabled, no need to click Save.)
 * Click
* Click Next Image to annotate the next.
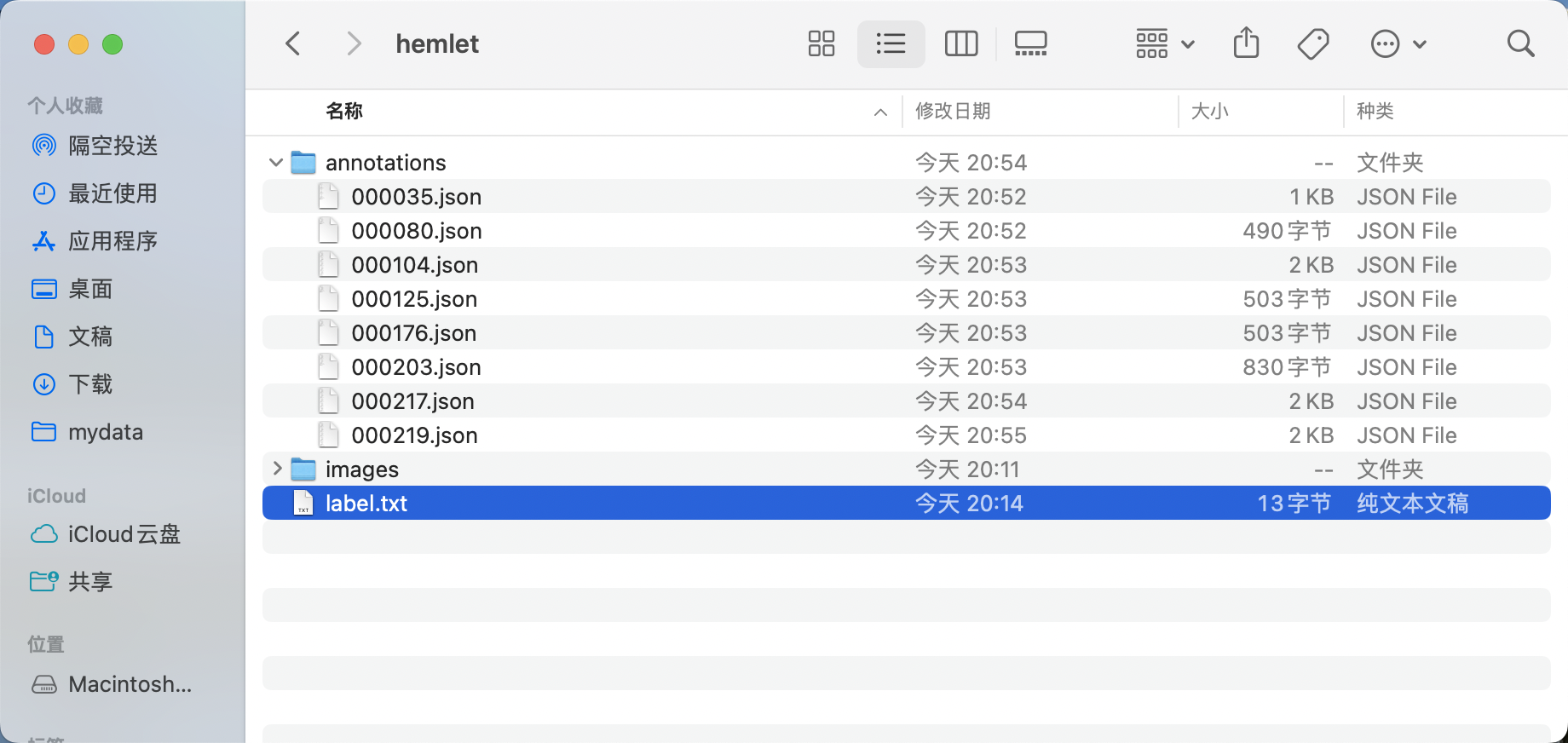
 * The final labeled tag file looks like this:
* The final labeled tag file looks like this:
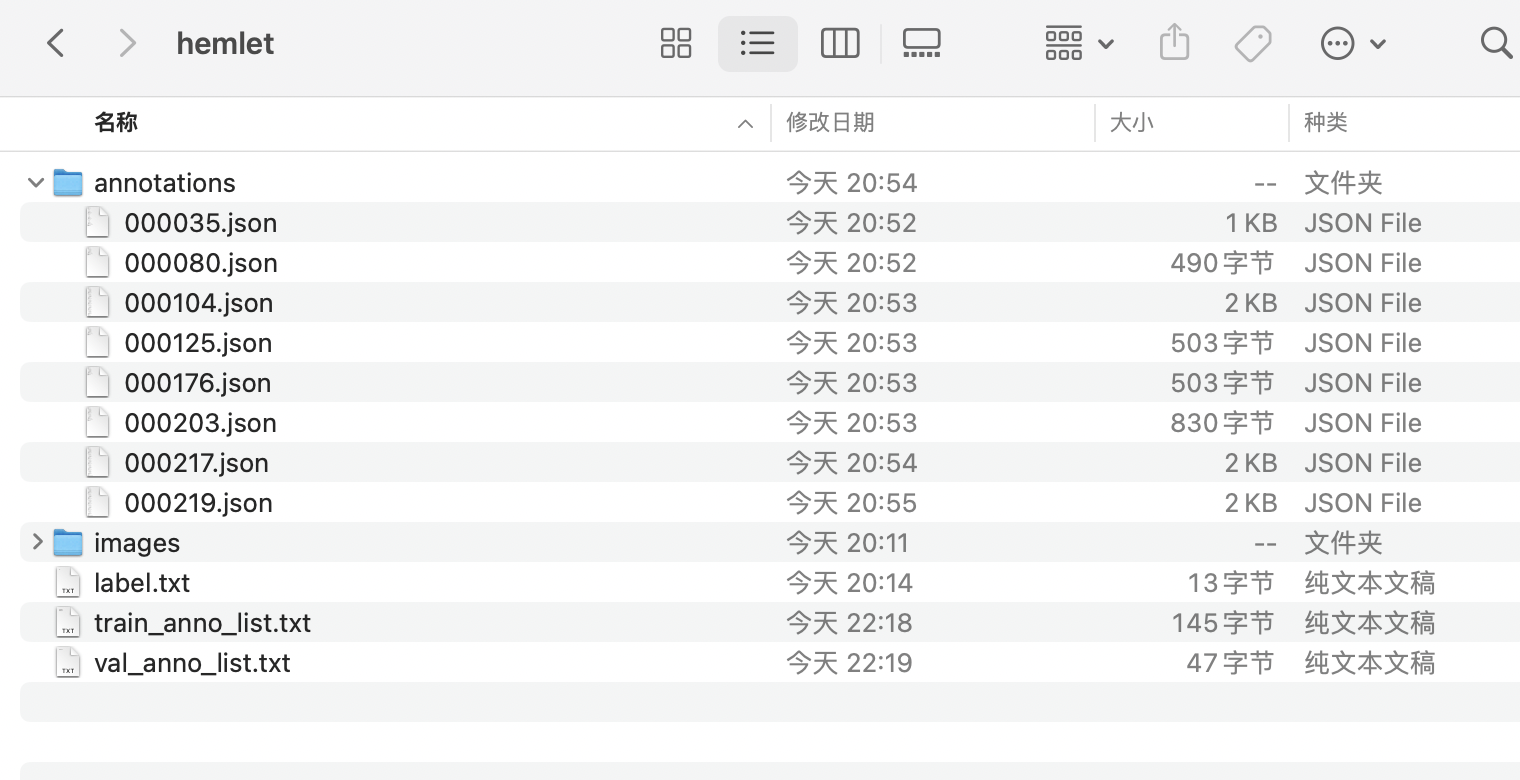
 * Adjust the directory to obtain the safety helmet detection dataset in the standard
* Adjust the directory to obtain the safety helmet detection dataset in the standard Labelme format
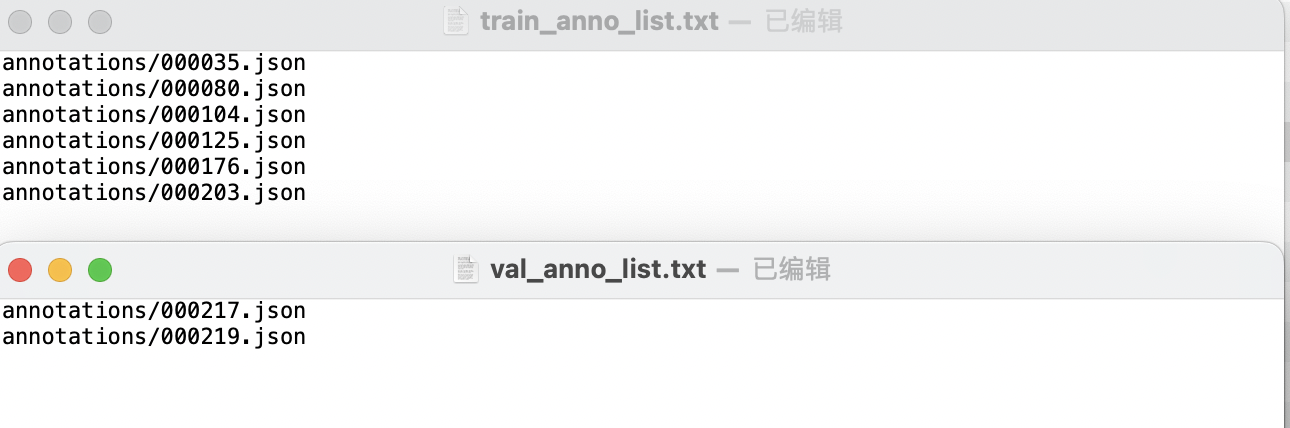
* Create two text files, train_anno_list.txt and val_anno_list.txt, in the root directory of the dataset. Write the paths of all json files in the annotations directory into train_anno_list.txt and val_anno_list.txt at a certain ratio, or write all of them into train_anno_list.txt and create an empty val_anno_list.txt file. Use the data splitting function to re-split. The specific filling format of train_anno_list.txt and val_anno_list.txt is shown below:
 * The final directory structure after organization is as follows:
* The final directory structure after organization is as follows:
2.3.4 Format Conversion¶
After labeling with Labelme, the data format needs to be converted to coco format. Below is a code example for converting the data labeled using Labelme according to the above tutorial:
cd /path/to/paddlex
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/data/det_labelme_examples.tar -P ./dataset
tar -xf ./dataset/det_labelme_examples.tar -C ./dataset/
python main.py -c paddlex/configs/obeject_detection/PicoDet-L.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/det_labelme_examples \
-o CheckDataset.convert.enable=True \
-o CheckDataset.convert.src_dataset_type=LabelMe
3. PaddleLabel Annotation¶
3.1 Installation and Startup of PaddleLabel¶
- To avoid environment conflicts, it is recommended to create a clean
condaenvironment: - Alternatively, you can install it with
pipin one command: - After successful installation, you can start PaddleLabel using one of the following commands in the terminal: PaddleLabel will automatically open a webpage in your browser after startup. You can then proceed with the annotation process based on your task.
3.2 Annotation Process of PaddleLabel¶
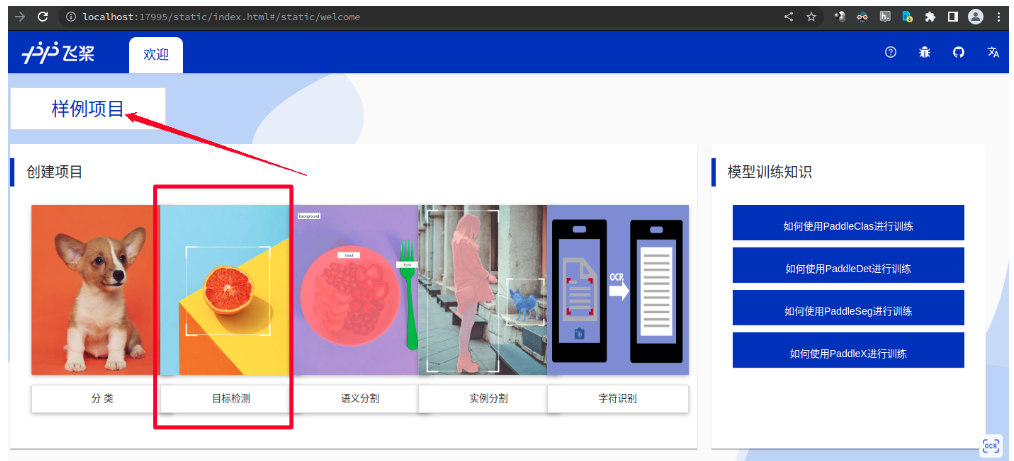
- Open the automatically popped-up webpage, click on the sample project, and then click on Object Detection.
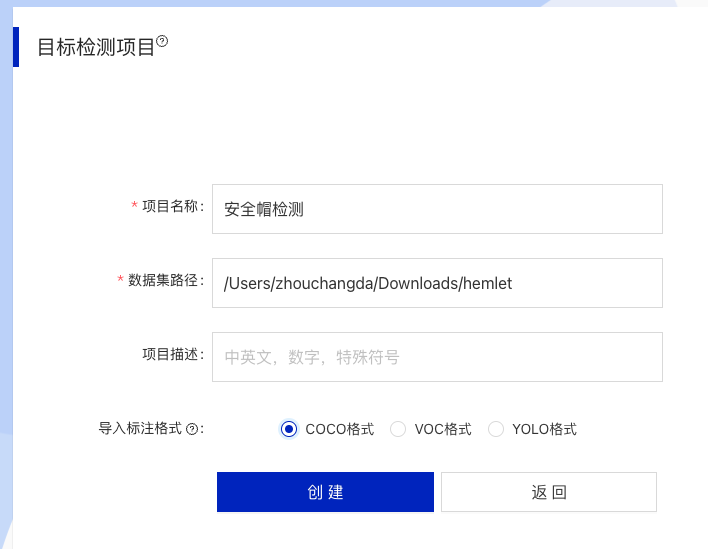
 * Fill in the project name and dataset path. Note that the path should be an absolute path on your local machine. Click Create when done.
* Fill in the project name and dataset path. Note that the path should be an absolute path on your local machine. Click Create when done.
 * First, define the categories that need to be annotated. Taking layout analysis as an example, provide 10 categories, each with a unique corresponding ID. Click Add Category to create the required category names.
* Start Annotating
* First, select the label you need to annotate.
* Click the rectangular selection button on the left.
* Draw a bounding box around the desired area in the image, paying attention to semantic partitioning. If there are multiple columns, please annotate each separately.
* After completing the annotation, the annotation result will appear in the lower right corner. You can check if the annotation is correct.
* When all annotations are complete, click Project Overview.
* First, define the categories that need to be annotated. Taking layout analysis as an example, provide 10 categories, each with a unique corresponding ID. Click Add Category to create the required category names.
* Start Annotating
* First, select the label you need to annotate.
* Click the rectangular selection button on the left.
* Draw a bounding box around the desired area in the image, paying attention to semantic partitioning. If there are multiple columns, please annotate each separately.
* After completing the annotation, the annotation result will appear in the lower right corner. You can check if the annotation is correct.
* When all annotations are complete, click Project Overview.
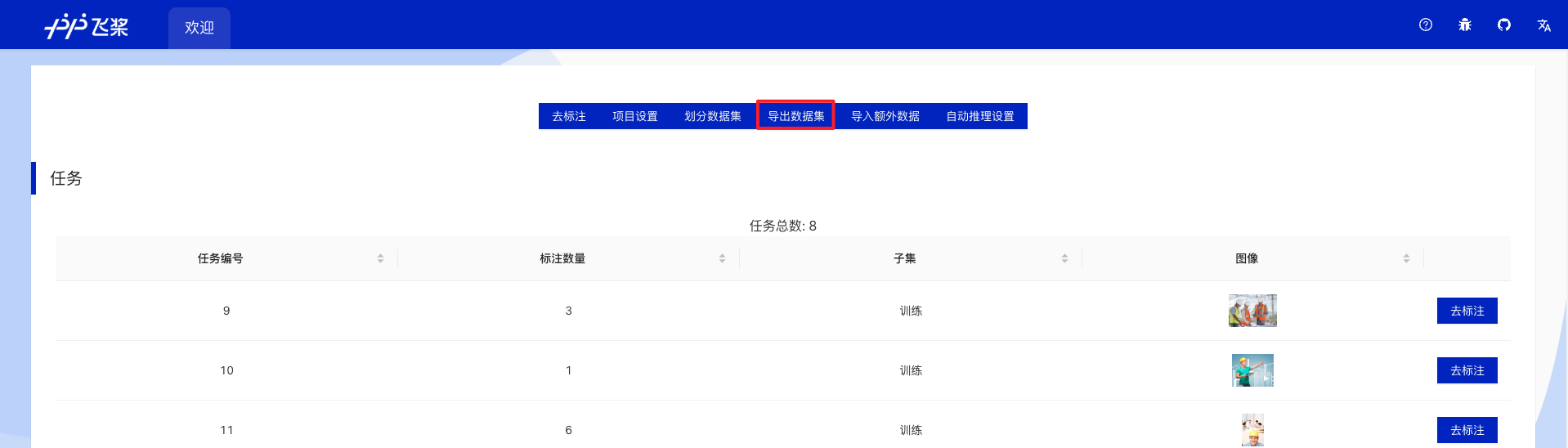
 * Export Annotation Files
* In Project Overview, divide the dataset as needed, then click Export Dataset.
* Export Annotation Files
* In Project Overview, divide the dataset as needed, then click Export Dataset.
 * Fill in the export path and export format. The export path should also be an absolute path, and the export format should be selected as
* Fill in the export path and export format. The export path should also be an absolute path, and the export format should be selected as coco.
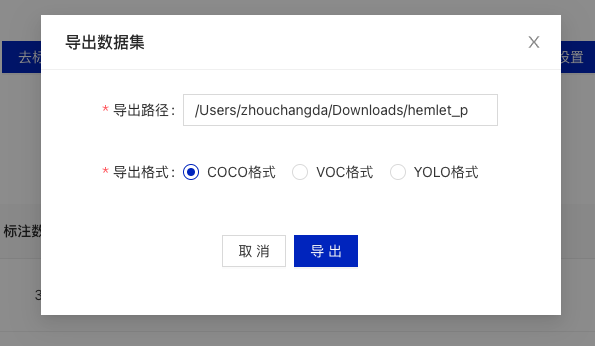 * After successful export, you can obtain the annotation files in the specified path.
* After successful export, you can obtain the annotation files in the specified path.
 * Adjust the directory to obtain the standard
* Adjust the directory to obtain the standard coco format dataset for helmet detection
* Rename the three json files and the image directory according to the following correspondence:
| Original File (Directory) Name | Renamed File (Directory) Name |
|---|---|
train.json |
instance_train.json |
val.json |
instance_val.json |
test.json |
instance_test.json |
image |
images |
- Create an
annotationsdirectory in the root directory of the dataset and move alljsonfiles to theannotationsdirectory. The final dataset directory structure will look like this:
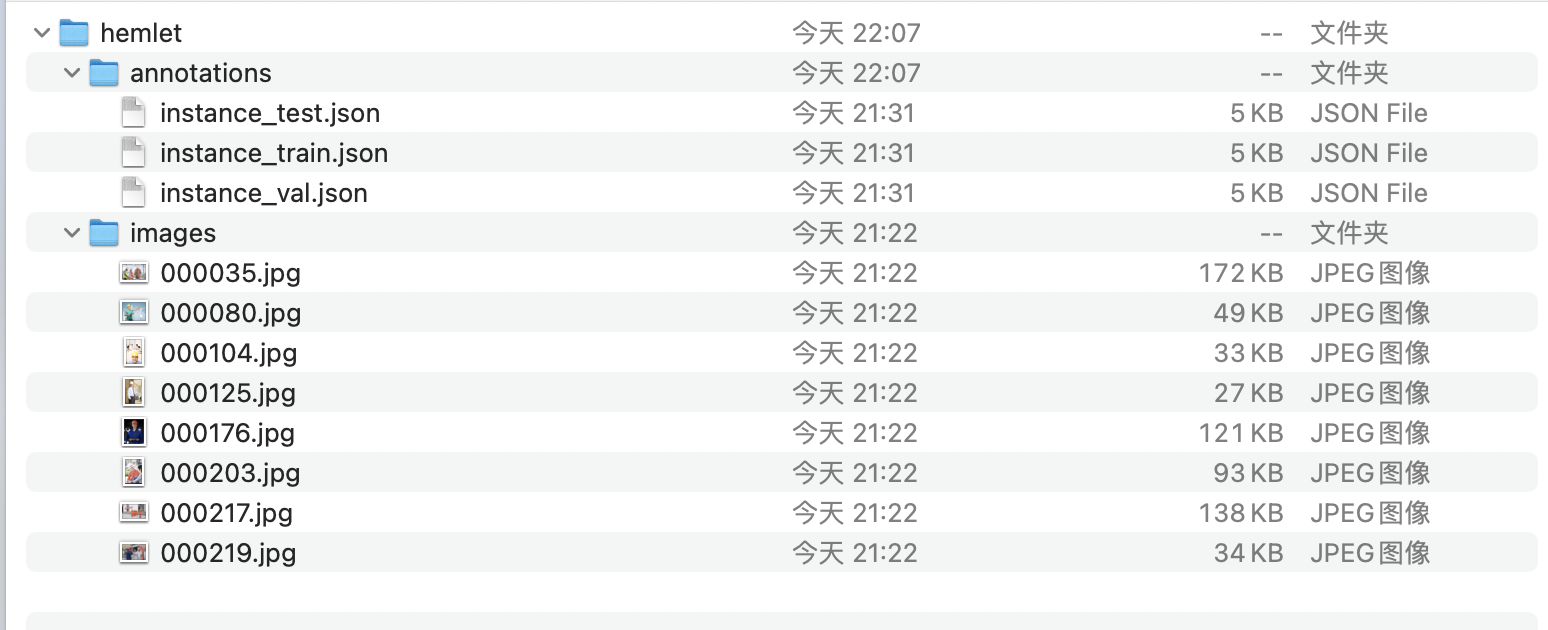 * Compress the
* Compress the helmet directory into a .tar or .zip format compressed package to obtain the standard coco format dataset for helmet detection.
4. Data Format¶
The dataset defined by PaddleX for object detection tasks is named COCODetDataset, with the following organizational structure and annotation format:
dataset_dir # Root directory of the dataset, the directory name can be changed
├── annotations # Directory for saving annotation files, the directory name cannot be changed
│ ├── instance_train.json # Annotation file for the training set, the file name cannot be changed, using COCO annotation format
│ └── instance_val.json # Annotation file for the validation set, the file name cannot be changed, using COCO annotation format
└── images # Directory for saving images, the directory name cannot be changed
The annotation files use the COCO format. Please prepare your data according to the above specifications. Additionally, you can refer to the example dataset.