PaddleX 服务化部署指南¶
服务化部署是实际生产环境中常见的一种部署形式。通过将推理功能封装为服务,客户端可以通过网络请求来访问这些服务,以获取推理结果。
PaddleX 产线服务化部署示意图:
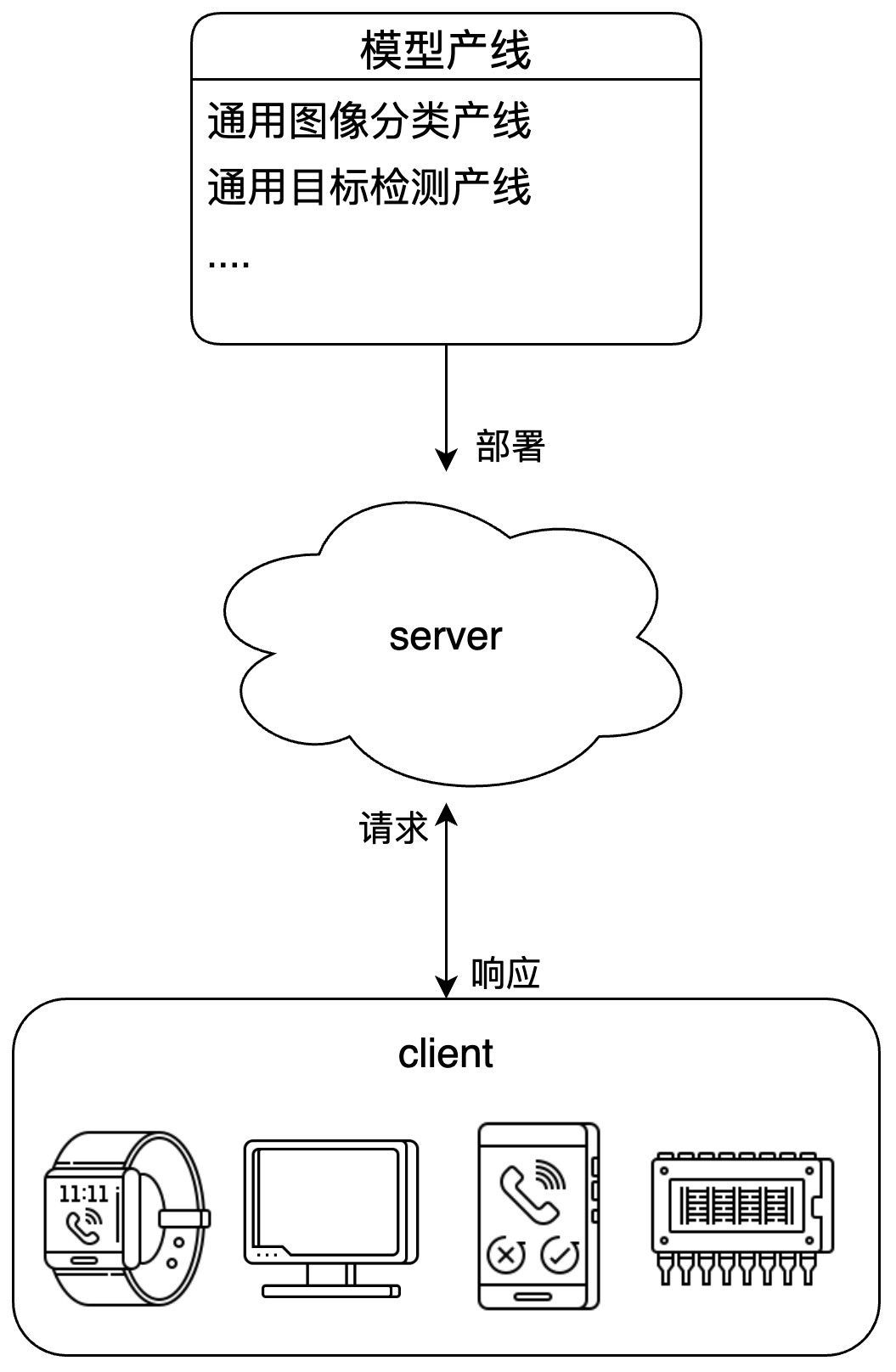
针对用户的不同需求,PaddleX 提供多种产线服务化部署方案:
- 基础服务化部署:简单易用的服务化部署方案,开发成本低。
- 高稳定性服务化部署:基于 NVIDIA Triton Inference Server 打造。与基础服务化部署相比,该方案提供更高的稳定性,并允许用户调整配置以优化性能。
建议首先使用基础服务化部署方案进行快速验证,然后根据实际需要,评估是否尝试更复杂的方案。
注意
- PaddleX 对产线而不是模块进行服务化部署。
1. 基础服务化部署¶
1.1 安装服务化部署插件¶
执行如下命令,安装服务化部署插件:
1.2 运行服务器¶
通过 PaddleX CLI 运行服务器:
以通用图像分类产线为例:
可以看到类似以下展示的信息:
INFO: Started server process [63108]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
--pipeline 可指定为官方产线名称或本地产线配置文件路径。PaddleX 以此构建产线并部署为服务。如需调整配置(如模型路径、batch size、部署设备等),请参考 通用图像分类产线使用教程 中的 ”模型应用“ 部分。
与服务化部署相关的命令行选项如下:
| 名称 | 说明 |
|---|---|
--pipeline |
产线名称或产线配置文件路径。 |
--device |
产线部署设备。默认情况下,当 GPU 可用时,将使用 GPU;否则使用 CPU。 |
--host |
服务器绑定的主机名或 IP 地址。默认为 0.0.0.0。 |
--port |
服务器监听的端口号。默认为 8080。 |
--use_hpip |
如果指定,则启用高性能推理插件。 |
--hpi_config |
高性能推理配置。 |
在对于服务响应时间要求较严格的应用场景中,可以使用 PaddleX 高性能推理插件对模型推理及前后处理进行加速,从而降低响应时间、提升吞吐量。
使用 PaddleX 高性能推理插件,请参考 PaddleX 高性能推理指南 。
可以通过指定 --use_hpip 以使用高性能推理插件。示例如下:
1.3 调用服务¶
各产线使用教程中的 “开发集成/部署” 部分提供了服务的 API 参考与多语言调用示例。在 此处 可以找到各产线的使用教程。
2. 高稳定性服务化部署¶
请注意,当前高稳定性服务化部署方案仅支持 Linux 系统。
2.1 下载高稳定性服务化部署 SDK¶
在下表中找到产线对应的高稳定性服务化部署 SDK 并下载:
👉 点击查看
如需手动打包可参考 hps 项目文档。
2.2 调整配置¶
高稳定性服务化部署 SDK 的 server/pipeline_config.yaml 文件为产线配置文件。用户可以修改该文件以设置要使用的模型目录等。
此外,PaddleX 高稳定性服务化部署方案基于 NVIDIA Triton Inference Server 打造,支持用户修改 Triton Inference Server 的配置文件。
在高稳定性服务化部署 SDK 的 server/model_repo/{端点名称} 目录中,可以找到一个或多个 config*.pbtxt 文件。如果目录中存在 config_{设备类型}.pbtxt 文件,请修改期望使用的设备类型对应的配置文件;否则,请修改 config.pbtxt。
一个常见的需求是调整执行实例数量。为了实现这一点,需要修改配置文件中的 instance_group 配置,使用 count 指定每一设备上放置的实例数量,使用 kind 指定设备类型,使用 gpus 指定 GPU 编号。示例如下:
-
在 GPU 0 上放置 4 个实例:
-
在 GPU 1 上放置 2 个实例,在 GPU 2 和 3 上分别放置 1 个实例:
关于更多配置细节,请参阅 Triton Inference Server 文档。
2.3 运行服务器¶
用于部署的机器上需要安装有 19.03 或更高版本的 Docker Engine。
首先,根据需要拉取 Docker 镜像:
-
支持使用 NVIDIA GPU 部署的镜像(机器上需要安装有支持 CUDA 11.8 的 NVIDIA 驱动):
-
CPU-only 镜像:
如需自定义构建镜像可参考 hps 项目文档。
准备好镜像后,切换到 server 目录,执行如下命令运行服务器:
docker run \
-it \
-e PADDLEX_HPS_DEVICE_TYPE={部署设备类型} \
-v "$(pwd)":/app \
-w /app \
--rm \
--gpus all \
--init \
--network host \
--shm-size 8g \
{镜像名称} \
/bin/bash server.sh
- 部署设备类型可以为
cpu或gpu,CPU-only 镜像仅支持cpu。 - 如果希望使用 CPU 部署,则不需要指定
--gpus。 - 如果需要进入容器内部调试,可以将命令中的
/bin/bash server.sh替换为/bin/bash,然后在容器中执行/bin/bash server.sh。 - 如果希望服务器在后台运行,可以将命令中的
-it替换为-d。容器启动后,可通过docker logs -f {容器 ID}查看容器日志。 - 在命令中添加
-e PADDLEX_HPS_USE_HPIP=1可以使用 PaddleX 高性能推理插件加速产线推理过程。请参考 PaddleX 高性能推理指南 获取更多信息。
可观察到类似下面的输出信息:
I1216 11:37:21.601943 35 grpc_server.cc:4117] Started GRPCInferenceService at 0.0.0.0:8001
I1216 11:37:21.602333 35 http_server.cc:2815] Started HTTPService at 0.0.0.0:8000
I1216 11:37:21.643494 35 http_server.cc:167] Started Metrics Service at 0.0.0.0:8002
2.4 调用服务¶
用户可以通过 SDK 中的 Python 客户端调用产线服务,或者手动构造 HTTP 请求(对客户端语言无限制)。
使用高稳定性服务化部署方案部署的服务,提供与基础服务化部署方案相匹配的主要操作。对于每个主要操作,端点名称以及请求和响应的数据字段都与基础服务化部署方案保持一致。请参阅各产线使用教程中的 “开发集成/部署” 部分。在 此处 可以找到各产线的使用教程。
2.4.1 使用 Python 客户端¶
切换到高稳定性服务化部署 SDK 的 client 目录,执行如下命令安装依赖:
# 建议在虚拟环境中安装
python -m pip install -r requirements.txt
python -m pip install paddlex_hps_client-*.whl
Python 客户端目前支持的 Python 版本为 3.8 至 3.12。
client 目录的 client.py 脚本包含服务的调用示例,并提供命令行接口。
2.4.2 手动构造 HTTP 请求¶
以下方式手工构造 HTTP 请求体并调用,适用于 Python 客户端不适用的情形。
首先,需要构造请求体。请求体为 JSON 格式,包含以下字段:
inputs:输入张量信息。输入张量名称name统一为input,张量形状shape为[1, 1],数据类型datatype为BYTES。张量数据data包含一个 JSON 字符串,JSON 的内容需对应不同产线字段(与基础服务化部署一致)。outputs:输出张量信息。输出张量名称name统一为output。
以通用 OCR 产线为例,构造的请求体内容示例如下:
{
"inputs": [
{
"name": "input",
"shape": [1, 1],
"datatype": "BYTES",
"data": [
"{\"file\":\"https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_001.png\",\"visualize\":false}"
]
}
],
"outputs": [
{
"name": "output"
}
]
}
将构造好的请求体通过发送到服务对应的 HTTP 推理端点。服务默认监听的 HTTP 端口为 8000,推理请求的 URL 格式为 http://{主机名}:8000/v2/models/{端点名称}/infer。
以通用 OCR 产线为例,如下是通过 curl 向发送请求的例子:
# 假设 `REQUEST_JSON` 为上一步骤中构造的请求体
curl -s -X POST http://localhost:8000/v2/models/ocr/infer \
-H 'Content-Type: application/json' \
-d "${REQUEST_JSON}"
最后,需要解析服务的响应。响应体的原始结构如下:
{
"outputs": [
{
"name": "output",
"data": [
"{\"errorCode\": 0, \"result\": {\"ocrResults\": [...]}}"
]
}
]
}
其中 outputs[0].data[0] 是一个 JSON 字符串,其中的字段与基础服务化部署方案中的响应体保持一致,具体解析规则可以查看各产线使用教程。
3. 以 URL 形式返回二进制内容¶
基础服务化与高稳定性服务化默认以 Base64 编码内联返回响应中的图像等二进制内容。当响应中包含较大图像或多页 PDF 时,Base64 会显著增加响应体积,可配置服务返回 URL。
两种部署方案共用同一组配置项。在产线配置文件的 Serving 节中配置(return_urls 为顶层字段,file_storage、url_expires_in 位于 Serving.extra):
Serving:
return_urls: true
extra:
file_storage:
type: bos
endpoint: <BOS 访问域名,例如 https://bj.bcebos.com>
ak: xxx
sk: xxx
bucket_name: <存储空间名称>
key_prefix: <可选,对象 key 前缀>
url_expires_in: 3600 # 预签名 URL 有效期(秒),-1 表示不过期
字段说明:
endpoint:BOS 访问域名,必须配置。ak:百度智能云 AK,必须配置。sk:百度智能云 SK,必须配置。bucket_name:BOS 存储空间名称,必须配置。key_prefix:可选,写入对象的 key 前缀。
部署方式落地:
- 基础服务化:上述配置写入
paddlex --serve --pipeline指定的产线配置文件。 - 高稳定性服务化:上述配置写入 SDK 内的
server/pipeline_config.yaml,重启容器后生效。
注意事项:
file_storage.type支持bos、file_system、memory;其中**仅bos提供预签名 URL 能力**。启用return_urls: true时file_storage必须为bos,否则服务启动失败。- 启用前后字段类型不变,值的形态从 Base64 字符串切换为可在
url_expires_in秒内 GET 下载的预签名 URL。 - 有关 AK/SK 获取等更多信息,请参考 百度智能云官方文档。