PaddleX 3.0 人脸识别产线———卡通人脸识别教程¶
PaddleX 提供了丰富的模型产线,模型产线由一个或多个模型组合实现,每个模型产线都能够解决特定的场景任务问题。PaddleX 所提供的模型产线均支持快速体验,如果效果不及预期,也同样支持使用私有数据微调模型,并且 PaddleX 提供了 Python API,方便将产线集成到个人项目中。在使用之前,您首先需要安装 PaddleX, 安装方式请参考 PaddleX 安装。此处以一个卡通人脸识别的任务为例子,介绍模型产线工具的使用流程。
1. 选择产线¶
首先,需要根据您的任务场景,选择对应的 PaddleX 产线,此处为人脸识别,对应 PaddleX 的人脸识别产线。如果无法确定任务和产线的对应关系,您可以在 PaddleX 支持的 模型产线列表 中了解相关产线的能力介绍。
2. 快速体验¶
在PaddleX人脸识别产线中,官方提供的各模型权重均基于真实人脸数据进行训练,我们首先以一个真实场景的人脸演示数据集进行体验。PaddleX 提供了以下快速体验的方式,可以直接通过 Python API在本地体验。
- 真实人脸数据本地体验方式:
(1) 下载真实人脸演示数据集, 并解压至本地目录,命令如下:
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/data/face_demo_gallery.tar
tar -xf ./face_demo_gallery.tar
(2) 执行python脚本,实现图片推理
from paddlex import create_pipeline
# 创建人脸识别产线
pipeline = create_pipeline(pipeline="face_recognition")
# 构建真实人脸特征底库
index_data = pipeline.build_index(gallery_imgs="face_demo_gallery", gallery_label="face_demo_gallery/gallery.txt")
# 图像预测
output = pipeline.predict("face_demo_gallery/test_images/friends1.jpg", index=index_data)
for res in output:
res.print()
res.save_to_img("./output/") # 保存可视化结果图像
真实人脸演示数据快速体验产出的推理结果示例:

- 卡通人脸数据本地体验方式:
(1) 下载卡通人脸演示数据集, 并解压至本地目录,命令如下:
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/data/cartoonface_demo_gallery.tar
tar -xf ./cartoonface_demo_gallery.tar
(2) 执行python脚本,实现图片推理
from paddlex import create_pipeline
# 创建人脸识别产线
pipeline = create_pipeline(pipeline="face_recognition")
# 构建卡通人脸特征底库
index_data = pipeline.build_index(gallery_imgs="cartoonface_demo_gallery", gallery_label="cartoonface_demo_gallery/gallery.txt")
# 图像预测
output = pipeline.predict("cartoonface_demo_gallery/test_images/cartoon_demo.jpg", index=index_data)
for res in output:
res.print()
res.save_to_img("./output/") # 保存可视化结果图像

当体验完该产线之后,需要确定产线是否符合预期(包含精度、速度等),产线包含的模型是否需要继续微调,如果模型的速度或者精度不符合预期,则需要根据模型选择可替换的模型继续测试,确定效果是否满意。如果最终效果均不满意,则需要微调模型。
本教程希望能够实现卡通人脸识别,通过上述快速体验的结果可以发现,官方默认模型在真实人脸场景中表现尚佳,但是在推理卡通数据时,出现了卡通人脸的漏检以及人脸的误识别,无法满足实际应用需求,因此我们需要通过二次开发来训练微调人脸检测和人脸特征模型。
3. 人脸特征底库构建¶
3.1 数据准备¶
本教程以真实人脸演示数据集为例,您可以下载官方提供的真实人脸演示数据集并解压至本地目录,命令如下:
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/data/face_demo_gallery.tar
tar -xf ./face_demo_gallery.tar
data_root # 数据集根目录,目录名称可以改变
├── images # 图像的保存目录,目录名称可以改变
│ ├── ID0 # 身份ID名字,最好是有意义的名字,比如人名
│ │ ├── xxx.jpg # 图片,此处支持层级嵌套
│ │ ├── xxx.jpg # 图片,此处支持层级嵌套
│ │ ...
│ ├── ID1 # 身份ID名字,最好是有意义的名字,比如人名
│ │ ├── xxx.jpg # 图片,此处支持层级嵌套
│ │ ├── xxx.jpg # 图片,此处支持层级嵌套
│ │ ...
│ ...
└── gallery.txt # 特征库数据集标注文件,文件名称可以改变。每行给出待检索人脸图像路径和图像标签,使用空格分隔,内容举例:images/Chandler/Chandler00037.jpg Chandler
3.2 人脸特征底库的构建¶
PaddleX 提供了简单的建库命令,仅需要如下几行代码即可实现人脸特征底库的构建和保存:
from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="face_recognition")
# gallery_imgs:人脸底库图片根目录, gallery_label:标注文件
index_data = pipeline.build_index(gallery_imgs="face_demo_gallery", gallery_label="face_demo_gallery/gallery.txt")
# 保存人脸特征底库
index_data.save("face_index")
4. 人脸特征底库的增加与删除¶
人脸特征底库的质量对人脸识别结果至关重要,对于识别效果较差的情况,例如特定光照条件、特定拍摄角度等,需要收集并添加相应的图片到特征底库中,另外身份的新增也同样需要将相应人脸图片增加到人脸特征底库中,而错误索引或是需要移除的身份,则需要将相应的索引从人脸特征底库中删除。
PaddleX 提供了简单的人脸特征底库调整命令,添加图像到人脸特征底库中,可以调用 append_index 方法;删除索引则可以调用 remove_index 方法。对于本教程中的人脸识别数据集调整人脸特征底库命令如下:
from paddlex import create_pipeline
pipeline = create_pipeline("face_recognition")
index_data = pipeline.build_index(gallery_imgs="face_demo_gallery", gallery_label="face_demo_gallery/gallery.txt", index_type="Flat")
index_data.save("face_index_base")
index_data = pipeline.remove_index(remove_ids="face_demo_gallery/remove_ids.txt", index="face_index_base")
index_data.save("face_index_del")
index_data = pipeline.append_index(gallery_imgs="face_demo_gallery", gallery_label="face_demo_gallery/gallery.txt", index="face_index_del")
index_data.save("face_index_add")
注: 1. 默认的 “HNSW32” 索引方式不支持删除索引,因此使用了 “Flat”,关于不同索引方式的区别,请参考人脸识别产线教程文档; 2. 对于命令中参数的详细介绍可参考人脸识别产线教程文档。
通过上述方法对特征底库进行删除和增加后,再次使用示例图片对生成的不同底库依次进行测试:
from paddlex import create_pipeline
# 创建人脸识别产线
pipeline = create_pipeline(pipeline="face_recognition")
# 传入待预测的图片和本地特征底库
output = pipeline.predict("face_demo_gallery/test_images/friends1.jpg", index='./face_index_del')
for res in output:
res.print()
res.save_to_img("./output/")
预测结果可视化图片如下:

5. 使用卡通数据训练微调人脸检测模型¶
5.1 模型选择¶
PaddleX 提供了 4个人脸检测模型,具体可参考 模型列表,其中人脸检测部分模型的benchmark如下:
| 模型 | 模型下载链接 | AP(%) | GPU推理耗时(ms) [常规模式 / 高性能模式] |
CPU推理耗时(ms) [常规模式 / 高性能模式] |
模型存储大小(MB) | 介绍 |
|---|---|---|---|---|---|---|
| BlazeFace | 推理模型/训练模型 | 15.4 | 50.90 / 45.74 | 71.92 / 71.92 | 0.447 | 轻量高效的人脸检测模型 |
| BlazeFace-FPN-SSH | 推理模型/训练模型 | 18.7 | 58.99 / 51.75 | 87.39 / 87.39 | 0.606 | BlazeFace的改进模型,增加FPN和SSH结构 |
| PicoDet_LCNet_x2_5_face | 推理模型/训练模型 | 31.4 | 33.91 / 26.53 | 153.56 / 79.21 | 28.9 | 基于PicoDet_LCNet_x2_5的人脸检测模型 |
| PP-YOLOE_plus-S_face | 推理模型/训练模型 | 36.1 | 21.28 / 11.09 | 137.26 / 72.09 | 26.5 | 基于PP-YOLOE_plus-S的人脸检测模型 |
注:以上精度指标是在 COCO 格式的 WIDER-FACE 验证集上,以640 *640作为输入尺寸评估得到的。所有模型 GPU 推理耗时基于 NVIDIA V100 机器,精度类型为 FP32, CPU 推理速度基于 Intel(R) Xeon(R) Gold 6271C CPU @ 2.60GHz,精度类型为 FP32。
5.2 数据准备和校验¶
本教程采用 卡通人脸检测数据集 作为示例数据集,可通过以下命令获取示例数据集。如果您使用自备的已标注数据集,需要按照 PaddleX 的格式要求对自备数据集进行调整,以满足 PaddleX 的数据格式要求。关于数据格式介绍,您可以参考 PaddleX 目标检测任务模块数据准备教程。
数据集获取命令:
cd /path/to/paddlex
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/data/cartoonface_coco_examples.tar -P ./dataset
tar -xf ./dataset/cartoonface_coco_examples.tar -C ./dataset/
数据集校验,在对数据集校验时,只需一行命令:
python main.py -c paddlex/configs/modules/face_detection/PP-YOLOE_plus-S_face.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/cartoonface_coco_examples
执行上述命令后,PaddleX 会对数据集进行校验,并统计数据集的基本信息。命令运行成功后会在 log 中打印出 Check dataset passed ! 信息,同时相关产出会保存在当前目录的 ./output/check_dataset 目录下,产出目录中包括可视化的示例样本图片和样本分布直方图。校验结果文件保存在 ./output/check_dataset_result.json,校验结果文件具体内容为
{
"done_flag": true,
"check_pass": true,
"attributes": {
"num_classes": 1,
"train_samples": 2000,
"train_sample_paths": [
"check_dataset\/demo_img\/personai_icartoonface_dettrain_27140.jpg",
"check_dataset\/demo_img\/personai_icartoonface_dettrain_23804.jpg",
"check_dataset\/demo_img\/personai_icartoonface_dettrain_76484.jpg",
"check_dataset\/demo_img\/personai_icartoonface_dettrain_18197.jpg",
"check_dataset\/demo_img\/personai_icartoonface_dettrain_35260.jpg",
"check_dataset\/demo_img\/personai_icartoonface_dettrain_00404.jpg",
"check_dataset\/demo_img\/personai_icartoonface_dettrain_15455.jpg",
"check_dataset\/demo_img\/personai_icartoonface_dettrain_10119.jpg",
"check_dataset\/demo_img\/personai_icartoonface_dettrain_26397.jpg",
"check_dataset\/demo_img\/personai_icartoonface_dettrain_17044.jpg"
],
"val_samples": 500,
"val_sample_paths": [
"check_dataset\/demo_img\/personai_icartoonface_dettrain_77030.jpg",
"check_dataset\/demo_img\/personai_icartoonface_dettrain_36265.jpg",
"check_dataset\/demo_img\/personai_icartoonface_dettrain_63390.jpg",
"check_dataset\/demo_img\/personai_icartoonface_dettrain_59167.jpg",
"check_dataset\/demo_img\/personai_icartoonface_dettrain_82024.jpg",
"check_dataset\/demo_img\/personai_icartoonface_dettrain_50449.jpg",
"check_dataset\/demo_img\/personai_icartoonface_dettrain_71386.jpg",
"check_dataset\/demo_img\/personai_icartoonface_dettrain_23112.jpg",
"check_dataset\/demo_img\/personai_icartoonface_dettrain_69609.jpg",
"check_dataset\/demo_img\/personai_icartoonface_dettrain_39296.jpg"
]
},
"analysis": {
"histogram": "check_dataset\/histogram.png"
},
"dataset_path": ".\/dataset\/cartoonface_coco_examples",
"show_type": "image",
"dataset_type": "COCODetDataset"
}
上述校验结果中,check_pass 为 True 表示数据集格式符合要求,其他部分指标的说明如下:
* attributes.num_classes:该数据集只有人脸 1 个类别;
* attributes.train_samples:该数据集训练集样本数量为 2000;
* attributes.val_samples:该数据集验证集样本数量为 500;
* attributes.train_sample_paths:该数据集训练集样本可视化图片相对路径列表;
* attributes.val_sample_paths:该数据集验证集样本可视化图片相对路径列表;
另外,数据集校验还对数据集中所有类别的标注数量分布情况进行了分析,并绘制了分布直方图(histogram.png):
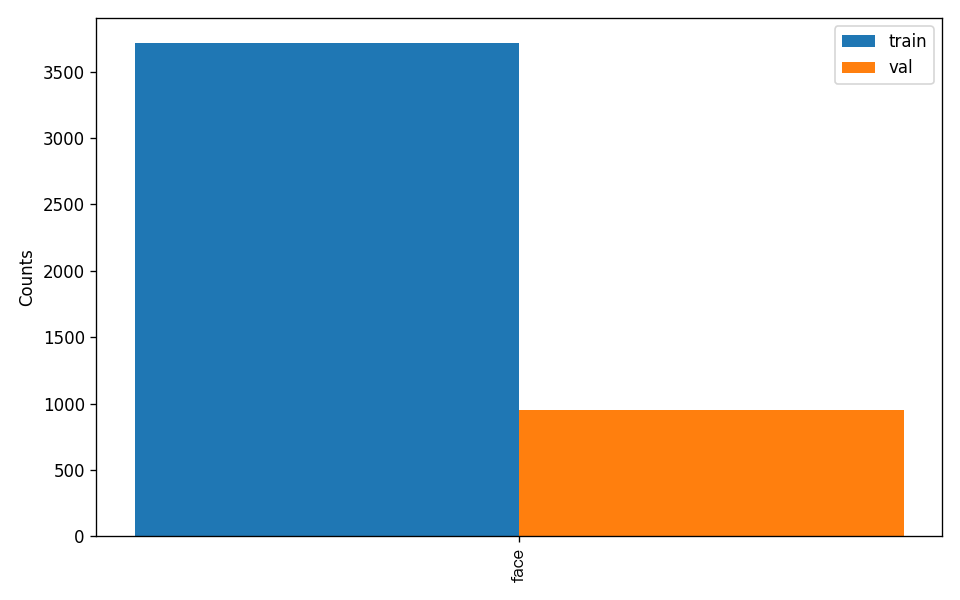
注:只有通过数据校验的数据才可以训练和评估。
数据集格式转换/数据集划分(非必选)¶
如需对数据集格式进行转换或是重新划分数据集,可通过修改配置文件或是追加超参数的方式进行设置。
数据集校验相关的参数可以通过修改配置文件中 CheckDataset 下的字段进行设置,配置文件中部分参数的示例说明如下:
CheckDataset:convert:enable: 是否进行数据集格式转换,为True时进行数据集格式转换,默认为False;src_dataset_type: 如果进行数据集格式转换,则需设置源数据集格式,数据可选源格式为LabelMe和VOC;
split:enable: 是否进行重新划分数据集,为True时进行数据集格式转换,默认为False;train_percent: 如果重新划分数据集,则需要设置训练集的百分比,类型为 0-100 之间的任意整数,需要保证和val_percent值加和为 100;val_percent: 如果重新划分数据集,则需要设置验证集的百分比,类型为 0-100 之间的任意整数,需要保证和train_percent值加和为 100;
数据转换和数据划分支持同时开启,对于数据划分原有标注文件会被在原路径下重命名为 xxx.bak,以上参数同样支持通过追加命令行参数的方式进行设置,例如重新划分数据集并设置训练集与验证集比例:-o CheckDataset.split.enable=True -o CheckDataset.split.train_percent=80 -o CheckDataset.split.val_percent=20。
5.3 模型训练和评估¶
模型训练¶
在训练之前,请确保您已经对数据集进行了校验。完成 PaddleX 模型的训练,只需如下一条命令:
python main.py -c paddlex/configs/modules/face_detection/PP-YOLOE_plus-S_face.yaml \
-o Global.mode=train \
-o Global.dataset_dir=./dataset/cartoonface_coco_examples \
-o Train.epochs_iters=10
在 PaddleX 中模型训练支持:修改训练超参数、单机单卡/多卡训练等功能,只需修改配置文件或追加命令行参数。
PaddleX 中每个模型都提供了模型开发的配置文件,用于设置相关参数。模型训练相关的参数可以通过修改配置文件中 Train 下的字段进行设置,配置文件中部分参数的示例说明如下:
Global:mode:模式,支持数据校验(check_dataset)、模型训练(train)、模型评估(evaluate);device:训练设备,可选cpu、gpu、xpu、npu、mlu,除 cpu 外,多卡训练可指定卡号,如:gpu:0,1,2,3;
Train:训练超参数设置;epochs_iters:训练轮次数设置;learning_rate:训练学习率设置;
更多超参数介绍,请参考 PaddleX 通用模型配置文件参数说明。
注:
- 以上参数可以通过追加令行参数的形式进行设置,如指定模式为模型训练:
-o Global.mode=train;指定前 2 卡 gpu 训练:-o Global.device=gpu:0,1;设置训练轮次数为 10:-o Train.epochs_iters=10。 - 模型训练过程中,PaddleX 会自动保存模型权重文件,默认为
output,如需指定保存路径,可通过配置文件中-o Global.output字段 - PaddleX 对您屏蔽了动态图权重和静态图权重的概念。在模型训练的过程中,会同时产出动态图和静态图的权重,在模型推理时,默认选择静态图权重推理。
训练产出解释:
在完成模型训练后,所有产出保存在指定的输出目录(默认为./output/)下,通常有以下产出:
train_result.json:训练结果记录文件,记录了训练任务是否正常完成,以及产出的权重指标、相关文件路径等;train.log:训练日志文件,记录了训练过程中的模型指标变化、loss 变化等;config.yaml:训练配置文件,记录了本次训练的超参数的配置;.pdparams、.pdema、.pdopt.pdstate、.pdiparams、.pdmodel:模型权重相关文件,包括网络参数、优化器、EMA、静态图网络参数、静态图网络结构等;
模型评估¶
在完成模型训练后,可以对指定的模型权重文件在验证集上进行评估,验证模型精度。使用 PaddleX 进行模型评估,只需一行命令:
python main.py -c paddlex/configs/modules/face_detection/PP-YOLOE_plus-S.yaml \
-o Global.mode=evaluate \
-o Global.dataset_dir=./dataset/cartoonface_coco_examples
与模型训练类似,模型评估支持修改配置文件或追加命令行参数的方式设置。
注: 在模型评估时,需要指定模型权重文件路径,每个配置文件中都内置了默认的权重保存路径,如需要改变,只需要通过追加命令行参数的形式进行设置即可,如-o Evaluate.weight_path=./output/best_model/best_model.pdparams。
5.4 模型调优¶
在学习了模型训练和评估后,我们可以通过调整超参数来提升模型的精度。通过合理调整训练轮数,您可以控制模型的训练深度,避免过拟合或欠拟合;而学习率的设置则关乎模型收敛的速度和稳定性。因此,在优化模型性能时,务必审慎考虑这两个参数的取值,并根据实际情况进行灵活调整,以获得最佳的训练效果。
推荐在调试参数时遵循控制变量法: 1. 首先固定训练迭代次数为 10,批大小为 4。 2. 基于 PP-YOLOE_plus-S_face 模型启动两个实验,学习率分别为:0.001,0.0001。 3. 可以发现实验二精度最高的配置为学习率为 0.0001,在该训练超参数基础上,增加训练轮数到20,可以看到达到更优的精度。
学习率探寻实验结果:
| 实验 | 轮次 | 学习率 | batch_size | 训练环境 | mAP@0.5 |
|---|---|---|---|---|---|
| 实验一 | 10 | 0.001 | 4 | 4卡 | 0.323 |
| 实验二 | 10 | 0.0001 | 4 | 4卡 | 0.334 |
改变 epoch 实验结果:
| 实验 | 轮次 | 学习率 | batch_size | 训练环境 | mAP@0.5 |
|---|---|---|---|---|---|
| 实验二 | 10 | 0.0001 | 4 | 4卡 | 0.334 |
| 实验二增大训练轮次 | 20 | 0.0001 | 4 | 4卡 | 0.360 |
注:本教程为4卡教程,如果您只有1张GPU,可通过调整训练卡数完成本次实验,但最终指标未必和上述指标对齐,属正常情况。
5.5 模型推理¶
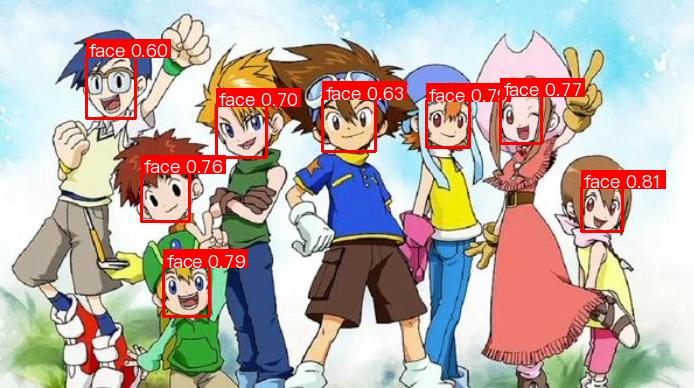
在完成模型的训练、评估和微调后,您可以使用指标令您满意的模型权重进行推理预测。通过命令行的方式进行推理预测,只需如下一条命令。我们以之前 快速体验 中官方模型权重表现差的卡通人脸演示数据为例,进行推理
python main.py -c paddlex/configs/modules/face_detection/PP-YOLOE_plus-S.yaml \
-o Global.mode=predict \
-o Predict.model_dir="output/best_model/inference" \
-o Predict.input="cartoonface_demo_gallery/test_images/cartoon_demo.jpg"
通过上述指令可在./output下生成预测结果,其中cartoon_demo.jpg的预测结果如下:
6. 使用卡通数据训练微调人脸特征模型¶
PaddleX训练过程中会保存最优模型的路径到output/best_model/inference中,在开始本节实验之前,请注意保存之前实验的最优权重到其他路径,避免被新的实验重写覆盖。
6.1 模型选择¶
PaddleX 提供了 2个人脸特征模型,具体可参考 模型列表,其中人脸特征部分模型的benchmark如下:
| 模型 | 模型下载链接 | 输出特征维度 | Acc (%) AgeDB-30/CFP-FP/LFW |
GPU推理耗时(ms) [常规模式 / 高性能模式] |
CPU推理耗时(ms) [常规模式 / 高性能模式] |
模型存储大小(MB) | 介绍 |
|---|---|---|---|---|---|---|---|
| MobileFaceNet | 推理模型/训练模型 | 128 | 96.28/96.71/99.58 | 3.31 / 0.73 | 5.93 / 1.30 | 4.1 | 基于MobileFaceNet在MS1Mv3数据集上训练的人脸特征提取模型 |
| ResNet50_face | 推理模型/训练模型 | 512 | 98.12/98.56/99.77 | 6.12 / 3.11 | 15.85 / 9.44 | 87.2 | 基于ResNet50在MS1Mv3数据集上训练的人脸特征提取模型 |
注:以上精度指标是分别在AgeDB-30、CFP-FP和LFW数据集上测得的Accuracy。所有模型 GPU 推理耗时基于 NVIDIA Tesla T4 机器,精度类型为 FP32, CPU 推理速度基于 Intel(R) Xeon(R) Gold 5117 CPU @ 2.00GHz,线程数为8,精度类型为 FP32。
6.2 数据准备和校验¶
本教程采用 卡通人脸识别数据集 作为示例数据集,可通过以下命令获取示例数据集。如果您使用自备的已标注数据集,需要按照 PaddleX 的格式要求对自备数据集进行调整,以满足 PaddleX 的数据格式要求。关于数据格式介绍,您可以参考 人脸特征模块教程文档。
数据集获取命令:
cd /path/to/paddlex
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/data/cartoonface_rec_examples.tar -P ./dataset
tar -xf ./dataset/cartoonface_rec_examples.tar -C ./dataset/
数据集校验 在对数据集校验时,只需一行命令:
python main.py -c paddlex/configs/modules/face_feature/ResNet50_face.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/cartoonface_rec_examples
执行上述命令后,PaddleX 会对数据集进行校验,并统计数据集的基本信息。命令运行成功后会在 log 中打印出 Check dataset passed ! 信息,同时相关产出会保存在当前目录的 ./output/check_dataset 目录下,产出目录中包括可视化的示例样本图片。校验结果文件保存在 ./output/check_dataset_result.json,校验结果文件具体内容为
{
"done_flag": true,
"check_pass": true,
"attributes": {
"train_label_file": "..\/..\/dataset\/cartoonface_rec_examples\/train\/label.txt",
"train_num_classes": 5006,
"train_samples": 77934,
"train_sample_paths": [
"check_dataset\/demo_img\/0000259.jpg",
"check_dataset\/demo_img\/0000052.jpg",
"check_dataset\/demo_img\/0000009.jpg",
"check_dataset\/demo_img\/0000203.jpg",
"check_dataset\/demo_img\/0000007.jpg",
"check_dataset\/demo_img\/0000055.jpg",
"check_dataset\/demo_img\/0000273.jpg",
"check_dataset\/demo_img\/0000006.jpg",
"check_dataset\/demo_img\/0000155.jpg",
"check_dataset\/demo_img\/0000006.jpg"
],
"val_label_file": "..\/..\/dataset\/cartoonface_rec_examples\/val\/pair_label.txt",
"val_num_classes": 2,
"val_samples": 8000,
"val_sample_paths": [
"check_dataset\/demo_img\/0000011.jpg",
"check_dataset\/demo_img\/0000121.jpg",
"check_dataset\/demo_img\/0000118.jpg",
"check_dataset\/demo_img\/0000034.jpg",
"check_dataset\/demo_img\/0000229.jpg",
"check_dataset\/demo_img\/0000070.jpg",
"check_dataset\/demo_img\/0000033.jpg",
"check_dataset\/demo_img\/0000089.jpg",
"check_dataset\/demo_img\/0000139.jpg",
"check_dataset\/demo_img\/0000081.jpg"
]
},
"analysis": {},
"dataset_path": ".\/dataset\/cartoonface_rec_examples",
"show_type": "image",
"dataset_type": "ClsDataset"
}
上述校验结果中,check_pass 为 True 表示数据集格式符合要求,其他部分指标的说明如下:
* attributes.train_num_classes:该数据集训练集有5006个人脸类别,此处类别数量为后续训练需要传入的类别数量;
* attributes.val_num_classes:人脸特征模型的验证集只有0、1两个类别,分别代表两张人脸图像不属于同一身份和属于同一个身份;
* attributes.train_samples:该数据集训练集样本数量为 77934;
* attributes.val_samples:该数据集验证集样本数量为 8000;
* attributes.train_sample_paths:该数据集训练集样本可视化图片相对路径列表;
* attributes.val_sample_paths:该数据集验证集样本可视化图片相对路径列表;
注:只有通过数据校验的数据才可以训练和评估。
6.3 模型训练和模型评估¶
模型训练¶
在训练之前,请确保您已经对数据集进行了校验。完成 PaddleX 模型的训练,只需如下一条命令:
python main.py -c paddlex/configs/modules/face_feature/ResNet50_face.yaml \
-o Global.mode=train \
-o Global.dataset_dir=./dataset/cartoonface_rec_examples \
-o Train.num_classes=5006 \
-o Train.log_interval=50
在 PaddleX 中模型训练支持:修改训练超参数、单机单卡/多卡训练等功能,只需修改配置文件或追加命令行参数。
PaddleX 中每个模型都提供了模型开发的配置文件,用于设置相关参数。模型训练相关的参数可以通过修改配置文件中 Train 下的字段进行设置,配置文件中部分参数的示例说明如下:
Global:mode:模式,支持数据校验(check_dataset)、模型训练(train)、模型评估(evaluate);device:训练设备,可选cpu、gpu、xpu、npu、mlu,除 cpu 外,多卡训练可指定卡号,如:gpu:0,1,2,3;
Train:训练超参数设置;epochs_iters:训练轮次数设置;learning_rate:训练学习率设置;
更多超参数介绍,请参考 PaddleX 通用模型配置文件参数说明
注:
- 以上参数可以通过追加令行参数的形式进行设置,如指定模式为模型训练:
-o Global.mode=train;指定前 2 卡 gpu 训练:-o Global.device=gpu:0,1;设置训练轮次数为 50:-o Train.epochs_iters=50。 - 模型训练过程中,PaddleX 会自动保存模型权重文件,默认为
output,如需指定保存路径,可通过配置文件中-o Global.output字段 - PaddleX 对您屏蔽了动态图权重和静态图权重的概念。在模型训练的过程中,会同时产出动态图和静态图的权重,在模型推理时,默认选择静态图权重推理。
训练产出解释:
在完成模型训练后,所有产出保存在指定的输出目录(默认为./output/)下,通常有以下产出: * train_result.json:训练结果记录文件,记录了训练任务是否正常完成,以及产出的权重指标、相关文件路径等; * train.log:训练日志文件,记录了训练过程中的模型指标变化、loss 变化等; * config.yaml:训练配置文件,记录了本次训练的超参数的配置; * .pdparams、.pdema、.pdopt.pdstate、.pdiparams、.pdmodel:模型权重相关文件,包括网络参数、优化器、EMA、静态图网络参数、静态图网络结构等;
模型评估¶
在完成模型训练后,可以对指定的模型权重文件在验证集上进行评估,验证模型精度。使用 PaddleX 进行模型评估,只需一行命令:
python main.py -c paddlex/configs/modules/face_feature/ResNet50_face.yaml \
-o Global.mode=evaluate \
-o Global.dataset_dir=./dataset/cartoonface_rec_examples \
-o Evaluate.log_interval=50
-o Evaluate.weight_path=./output/best_model/model.pdparams。
5.4 模型调优¶
PaddleX中的人脸特征模型基于ArcFace损失函数训练,除了学习率和训练轮数,ArcFace损失函数中的margin参数是一个关键的超参数,它通过在角度空间引入一个固定的角度间隔(margin),强化了类间的可分性,从而提高模型的判别能力,在模型调优的实验中我们主要对margin进行实验。
margin的大小对模型的训练效果和最终性能有较大影响,一般地:增大margin会使不同类别之间的判别边界更加明显,迫使模型在特征空间中将不同类别的特征向量分得更开,从而提高类间的可分性。但过大的margin可能导致训练过程中的优化难度加大,训练收敛速度变慢甚至无法收敛。此外在训练数据不足或数据噪声较大的情况下,过大的margin可能会使模型对训练数据过拟合,对未见过的数据泛化能力下降;
较小的margin可以减轻模型的训练难度,模型更容易收敛。对于数据量较小或质量不高的训练集,减小margin可以降低过拟合风险,提高模型的泛化能力。但过小的margin可能无法充分拉开不同类别之间的特征距离,模型无法学习到足够判别性的特征,影响识别准确率。
在数据校验环节中可以看到,我们使用的卡通人脸识别数据集有77934个训练样本,相对于一般的人脸识别数据集(MS1Mv2 580万,Glint360K 1700万)来说是一个小量的数据集,因此在使用该数据集训练人脸特征模型时,我们推荐减小margin参数以降低过拟合风险,提高模型的泛化能。在PaddleX中,可以通过追加令行参数-o Train.arcmargin_m=xx来指定人脸特征模型训练过程中margin参数的值。训练指令示例:
python main.py -c paddlex/configs/modules/face_feature/ResNet50_face.yaml \
-o Global.mode=train \
-o Global.dataset_dir=./dataset/cartoonface_rec_examples \
-o Train.num_classes=5006 \
-o Train.log_interval=50 \
-o Train.arcmargin_m=0.3
在调试参数时遵循控制变量法: 1. 固定训练迭代次数为 20,学习率为4e-4。 2. 基于 ResNet50_face 模型启动两个实验,margin分别为:0.5,0.3。
margin探寻实验结果:
| 实验 | 轮次 | 学习率 | margin | 训练环境 | Acc |
|---|---|---|---|---|---|
| 实验一 | 25 | 4e-4 | 0.5 | 4卡 | 0.925 |
| 实验二 | 25 | 4e-4 | 0.3 | 4卡 | 0.928 |
注:本教程为4卡教程,如果您只有1张GPU,可通过调整训练卡数完成本次实验,但最终指标未必和上述指标对齐,属正常情况。
7. 产线集成¶
在使用卡通场景数据完成人脸检测模型和人脸特征模型的训练微调后,您可挑选高精度的模型权重集成到PaddleX的人脸识别产线中。
首先获取 face_recognition 产线配置文件,并加载配置文件进行预测。可执行如下命令将结果保存在 my_path 中:
将配置文件中的 SubModules.Detection.model_dir 和 SubModules.Recognition.model_dir 分别修改为自己微调训练的人脸检测模型路径和人脸特征模型路径, 若您需要将人脸识别产线直接应用在您的 Python 项目中,可以参考如下示例:
pipeline_name: face_recognition
index: None
det_threshold: 0.6
rec_threshold: 0.4
rec_topk: 5
SubModules:
Detection:
module_name: face_detection
model_name: PP-YOLOE_plus-S_face
model_dir: "path/to/your/det_model" # 使用卡通人脸数据微调的人脸检测模型
batch_size: 1
Recognition:
module_name: face_feature
model_name: ResNet50_face
model_dir: "path/to/your/rec_model" # 使用卡通人脸数据微调的人脸特征模型
batch_size: 1
随后,在您的 Python 代码中,您可以这样使用产线:
from paddlex import create_pipeline
# 创建人脸识别产线
pipeline = create_pipeline(pipeline="my_path/face_recognition.yaml")
# 构建卡通人脸特征底库
index_data = pipeline.build_index(gallery_imgs="cartoonface_demo_gallery", gallery_label="cartoonface_demo_gallery/gallery.txt")
# 图像预测
output = pipeline.predict("cartoonface_demo_gallery/test_images/cartoon_demo.jpg", index=index_data)
for res in output:
res.print()
res.save_to_img("./output/") # 保存可视化结果图像
如果存在卡通人脸可以检出但识别为 “Unknown0.00“ 的情况,可以修改配置文件中的 rec_thresholds,降低检索阈值后再次尝试。如果存在人脸识别错误的情况,请更换最优权重为最后一轮权重,或者更换不同超参数训练的识别模型权重再次尝试。
8、产线服务化部署¶
除了前文中提到的 Python API 集成开发方式外,PaddleX 还提供了高性能部署和服务化部署能力,详细说明如下: * 高性能部署:在实际生产环境中,许多应用对部署策略的性能指标(尤其是响应速度)有着较严苛的标准,以确保系统的高效运行与用户体验的流畅性。为此,PaddleX 提供高性能推理插件,旨在对模型推理及前后处理进行深度性能优化,实现端到端流程的显著提速,详细的高性能部署流程请参考 PaddleX 高性能推理指南。 * 服务化部署:服务化部署是实际生产环境中常见的一种部署形式。通过将推理功能封装为服务,客户端可以通过网络请求来访问这些服务,以获取推理结果。PaddleX 支持用户以低成本实现产线的服务化部署,详细的服务化部署流程请参考 PaddleX 服务化部署指南。
您可以根据需要选择合适的方式部署模型产线,进而进行后续的 AI 应用集成。 本节以服务化部署为例,带着大家完成一次产线的服务化部署和接口调用,仅需简单5步即可完成产线的服务化部署:
(1) 执行以下Python脚本,保存卡通人脸演示数据的特征底库
from paddlex import create_pipeline
# 创建人脸识别产线
pipeline = create_pipeline(pipeline="face_recognition")
# 构建卡通人脸特征底库
index_data = pipeline.build_index(gallery_imgs="cartoonface_demo_gallery", gallery_label="cartoonface_demo_gallery/gallery.txt")
# 保存卡通人脸特征底库
index_data.save("cartoonface_index")
(2) 在命令行中执行以下命令,安装服务化部署插件
(3) 获取人脸识别产线配置文件
(4) 修改配置文件,配置特征底库目录
pipeline_name: face_recognition
index: ./cartoonface_index # 本地特征底库目录,使用第(1)步中构建好的特征底库
det_threshold: 0.6
rec_threshold: 0.4
rec_topk: 5
SubModules:
Detection:
module_name: face_detection
model_name: PP-YOLOE_plus-S_face
model_dir: "path/to/your/det_model" # 使用卡通人脸数据微调的人脸检测模型
batch_size: 1
Recognition:
module_name: face_feature
model_name: ResNet50_face
model_dir: "path/to/your/rec_model" # 使用卡通人脸数据微调的人脸特征模型
batch_size: 1
(5) 启动服务端服务
客户端调用¶
PaddleX 提供了简单快捷的调用接口和调用示例代码,这里以简单的图片推理为例,更多详细的调用接口支持可参考 人脸识别产线使用教程
客户端调用示例代码:
import base64
import pprint
import sys
import requests
API_BASE_URL = "http://0.0.0.0:8080"
infer_image_path = "cartoonface_demo_gallery/test_images/cartoon_demo.jpg" # 测试图片
with open(infer_image_path, "rb") as file:
image_bytes = file.read()
image_data = base64.b64encode(image_bytes).decode("ascii")
payload = {"image": image_data}
resp_infer = requests.post(f"{API_BASE_URL}/face-recognition-infer", json=payload)
if resp_infer.status_code != 200:
print(f"Request to face-recognition-infer failed with status code {resp_infer}.")
pprint.pp(resp_infer.json())
sys.exit(1)
result_infer = resp_infer.json()["result"]
output_image_path = './out.jpg'
with open(output_image_path, "wb") as file:
file.write(base64.b64decode(result_infer["image"]))
print(f"Output image saved at {output_image_path}")
print("\nDetected faces:")
pprint.pp(result_infer["faces"])