PaddleX 3.0 文档场景信息抽取v3(PP-ChatOCRv3_doc) —— 印章信息抽取教程¶
PaddleX 提供了丰富的模型产线,模型产线由一个或多个模型组合实现,每个模型产线都能够解决特定的场景任务问题。PaddleX 所提供的模型产线均支持快速体验,如果效果不及预期,也同样支持使用私有数据微调模型,并且 PaddleX 提供了 Python API,方便将产线集成到个人项目中。在使用之前,您首先需要安装 PaddleX, 安装方式请参考 PaddleX本地安装教程。此处以一个印章的文档场景信息抽取任务为例子,介绍该产线的在实际场景中的使用流程。
1. 选择产线¶
印章信息抽取是文档处理的一部分,在很多场景都有用途,例如合同比对,出入库审核以及发票报销审核等场景。采用人工智能技术进行印章自动识别,可以为企业有效节省人力成本,提高效率。
首先,需要根据任务场景,选择对应的 PaddleX 产线,本节为印章信息抽取任务,不难发现印章信息抽取任务与文档场景信息抽取任务存在着紧密的关联。文档场景信息抽取,即从文档或图像中提取文本信息,是计算机视觉领域的一个经典问题。对应 PaddleX 的文档场景信息抽取v3产线。如果无法确定任务和产线的对应关系,您可以在 PaddleX 支持的产线列表中了解相关产线的能力介绍。
2. 快速体验¶
PaddleX 提供了两种体验的方式,你可以在线体验文档场景信息抽取v3产线的效果,也可以在本地使用 Python 体验文档场景信息抽取v3 产线的效果。
2.1 本地体验¶
在本地使用文档场景信息抽取v3产线前,请确保您已经按照PaddleX本地安装教程完成了PaddleX的wheel包安装。
首先需要配置获取 PP-ChatOCRv3-doc 产线的配置文件,可以通过以下命令获取:
执行上述命令后,配置文件会存储在当前路径下,打开配置文件,填写大语言模型的 ak/sk(access_token),如下所示:
......
SubModules:
LLM_Chat:
module_name: chat_bot
model_name: ernie-3.5
api_type: qianfan
ak: "" # Your LLM API key
sk: "" # Your LLM secret key
LLM_Retriever:
module_name: retriever
model_name: ernie-3.5
api_type: qianfan
ak: "" # Your LLM API key
sk: "" # Your LLM secret key
......
PP-ChatOCRv3 仅支持文心大模型,支持在百度云千帆平台或者星河社区 AIStudio上获取相关的 ak/sk(access_token)。如果使用百度云千帆平台,可以参考AK和SK鉴权调用API流程 获取ak/sk,如果使用星河社区 AIStudio,可以在星河社区 AIStudio 访问令牌中获取 access_token。
更新配置文件后,即可使用几行Python代码完成快速推理:
from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="./PP-ChatOCRv3-doc.yaml")
visual_predict_res = pipeline.visual_predict(input="https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/doc_images/practical_tutorial/PP-ChatOCRv3_doc_seal/test.png",
use_doc_orientation_classify=False,
use_doc_unwarping=False,
use_common_ocr=True,
use_seal_recognition=True,
use_table_recognition=True)
visual_info_list = []
for res in visual_predict_res:
visual_info_list.append(res["visual_info"])
layout_parsing_result = res["layout_parsing_result"]
layout_parsing_result.save_to_img("./output")
# layout_parsing_result.save_to_json("./output")
# layout_parsing_result.save_to_xlsx("./output")
# layout_parsing_result.save_to_html("./output")
vector_info = pipeline.build_vector(visual_info_list, flag_save_bytes_vector=True)
chat_result = pipeline.chat(key_list=["印章名称"], visual_info=visual_info_list, vector_info=vector_info)
print(chat_result)
输出打印的结果如下:
在output 目录中,保存了印章文本检测、OCR(如有表格,还有表格识别可视化结果以及表格html和xlsx)结果。
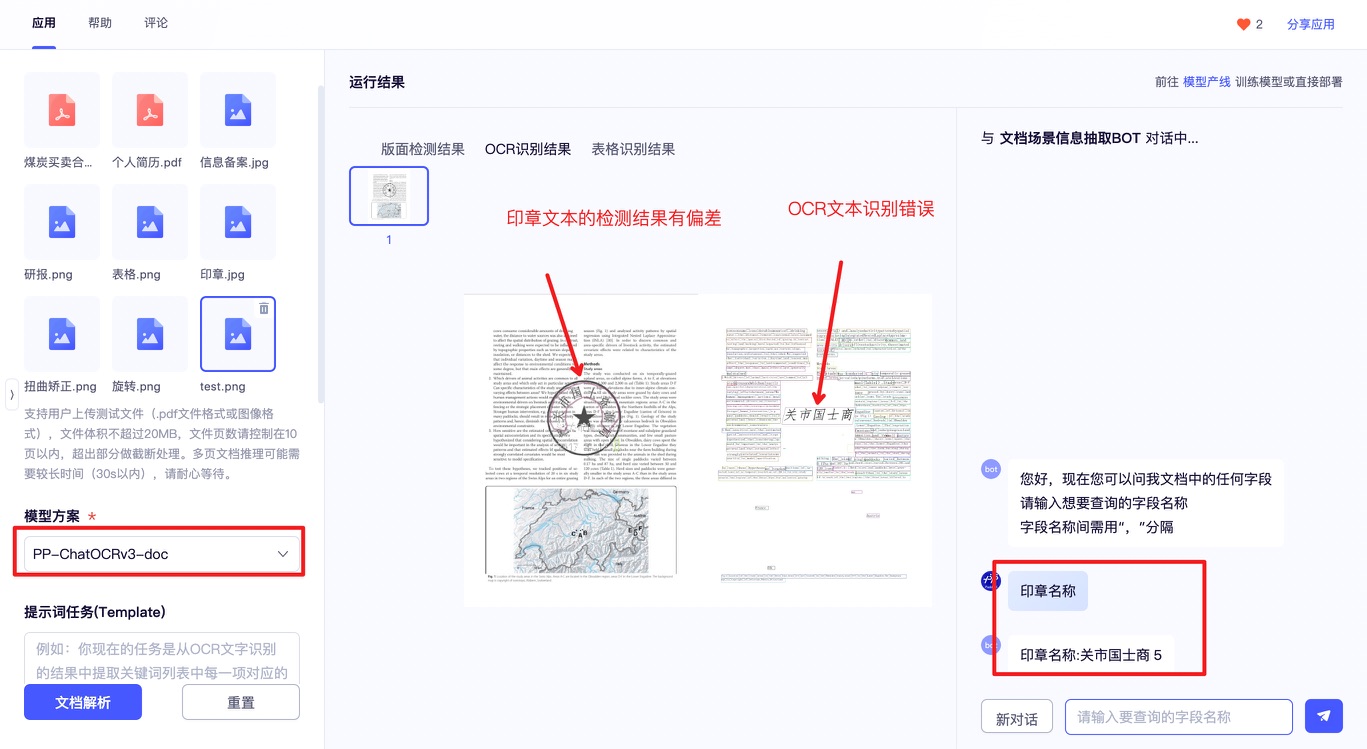
其中印章文本识别结果可视化如下:

通过上面的文档场景信息抽取的快速体验可以进行 Badcase 分析,发现文档场景信息抽取产线的官方模型,在当前需求场景中存在下面的问题:在OCR识别的可视化中,印章的文本弯曲检测框有偏差,导致印章文本识别错误;印章的信息没有被正确的抽取出来。在{'chat_res': {'印章名称': '大中国土资源局'}中的结果是错误的。因此,本节工作聚焦于印章信息抽取的场景,对文档场景信息抽取产线中的印章文本检测模型进行微调,从而达到能够精确提取文档中印章文本信息的能力。
2.2 在线体验¶
您可以在 AI Studio 星河社区 体验文档场景信息抽取v3产线的效果,点击链接下载 印章测试文件,上传至官方文档场景信息抽取v3 应用 体验抽取效果。如下:
{kind=link}
3. 选择模型¶
PaddleX 提供了 2 个端到端的印章文本检测模型,具体可参考 模型列表,其中印章文本检测模型的 benchmark 如下:
| 模型名称 | 检测Hmean(%) | GPU推理耗时(ms) [常规模式 / 高性能模式] |
CPU推理耗时(ms) | 模型存储大小(MB) | yaml 文件 |
|---|---|---|---|---|---|
| PP-OCRv4_mobile_seal_det | 96.36 | 9.70 / 3.56 | 50.38 / 19.64 | 4.7 | PP-OCRv4_mobile_seal_det.yaml |
| PP-OCRv4_server_seal_det | 98.40 | 124.64 / 91.57 | 545.68 / 439.86 | 109 | PP-OCRv4_server_seal_det.yaml |
注:以上精度指标的评估集是 PaddleX 自建的印章数据集,包含500印章图像。
4. 数据准备和校验¶
4.1 数据准备¶
本教程采用 印章文本检测数据集 作为示例数据集,可通过以下命令获取示例数据集。如果您使用自备的已标注数据集,需要按照 PaddleX 的格式要求对自备数据集进行调整,以满足 PaddleX 的数据格式要求。关于数据格式介绍,您可以参考 PaddleX 目标检测模块数据标注教程。
数据集获取命令:
cd /path/to/paddlex
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/data/practical_seal.tar -P ./dataset
tar -xf ./dataset/practical_seal.tar -C ./dataset/
4.2 数据集校验¶
在对数据集校验时,只需一行命令:
python main.py -c paddlex/configs/modules/seal_text_detection/PP-OCRv4_server_seal_det.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/practical_seal/
执行上述命令后,PaddleX 会对数据集进行校验,并统计数据集的基本信息。命令运行成功后会在 log 中打印出 Check dataset passed ! 信息,同时相关产出会保存在当前目录的 ./output/check_dataset 目录下,产出目录中包括可视化的示例样本图片和样本检测框长宽比分布直方图。校验结果文件保存在 ./output/check_dataset_result.json,校验结果文件具体内容为
{
"done_flag": true,
"check_pass": true,
"attributes": {
"train_samples": 793,
"train_sample_paths": [
"..\/dataset\/practical_seal\/images\/PMC4055390_00006_seal_0_crop.png",
"..\/dataset\/practical_seal\/images\/PMC3712248_00008_seal_0_crop.png",
"..\/dataset\/practical_seal\/images\/PMC4227328_00001_seal_0_crop.png",
"..\/dataset\/practical_seal\/images\/PMC3745965_00007_seal_0_crop.png",
"..\/dataset\/practical_seal\/images\/PMC3980931_00001_seal_0_crop.png",
"..\/dataset\/practical_seal\/images\/PMC5896212_00003_seal_0_crop.png",
"..\/dataset\/practical_seal\/images\/PMC3838814_00003_seal_0_crop.png",
"..\/dataset\/practical_seal\/images\/PMC4677212_00002_seal_0_crop.png",
"..\/dataset\/practical_seal\/images\/PMC4058803_00001_seal_0_crop.png",
"..\/dataset\/practical_seal\/images\/PMC4925966_00001_seal_0_crop.png"
],
"val_samples": 277,
"val_sample_paths": [
"..\/dataset\/practical_seal\/images\/15.jpg",
"..\/dataset\/practical_seal\/images\/16.jpg",
"..\/dataset\/practical_seal\/images\/17.jpg",
"..\/dataset\/practical_seal\/images\/18.jpg",
"..\/dataset\/practical_seal\/images\/19.jpg",
"..\/dataset\/practical_seal\/images\/20.jpg",
"..\/dataset\/practical_seal\/images\/21.jpg",
"..\/dataset\/practical_seal\/images\/22.jpg",
"..\/dataset\/practical_seal\/images\/23.jpg",
"..\/dataset\/practical_seal\/images\/24.jpg"
]
},
"analysis": {
"histogram": "check_dataset\/histogram.png"
},
"dataset_path": "practical_seal/",
"show_type": "image",
"dataset_type": "TextDetDataset"
}
- attributes.train_samples:该数据集训练集样本数量为 793;
- attributes.val_samples:该数据集验证集样本数量为 277;
- attributes.train_sample_paths:该数据集训练集样本可视化图片相对路径列表;
- attributes.val_sample_paths:该数据集验证集样本可视化图片相对路径列表;
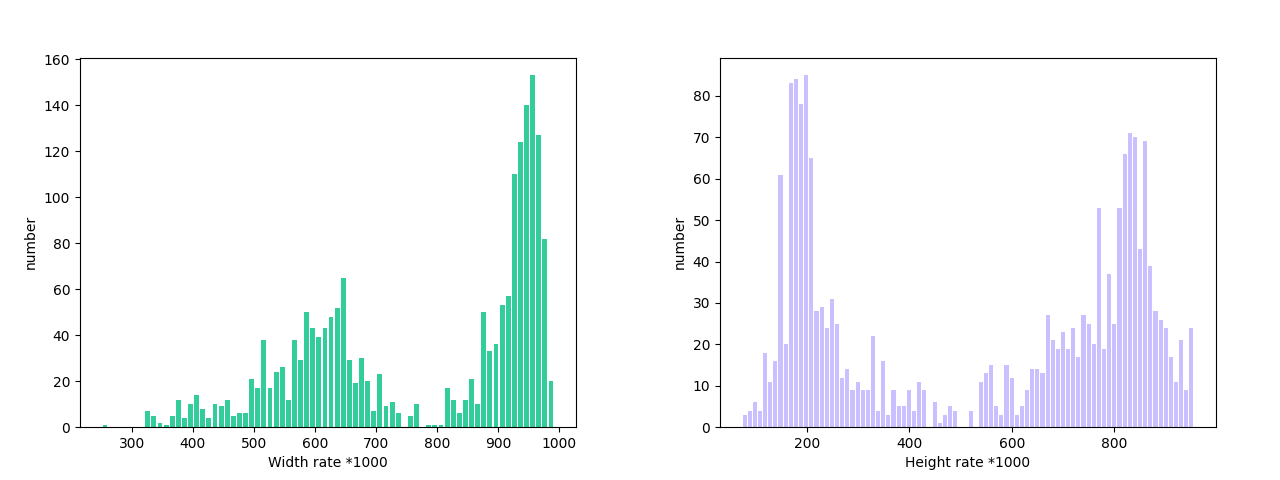
另外,数据集校验还对数据集中所有类别的样本长宽比分布情况进行了分析,并绘制了分布直方图(histogram.png):
注:只有通过数据校验的数据才可以训练和评估。
4.3 数据集划分(非必选)¶
如需对数据集格式进行转换或是重新划分数据集,可通过修改配置文件或是追加超参数的方式进行设置。
数据集校验相关的参数可以通过修改配置文件中 CheckDataset 下的字段进行设置,配置文件中部分参数的示例说明如下:
CheckDataset:split:enable: 是否进行重新划分数据集,为True时进行数据集格式转换,默认为False;train_percent: 如果重新划分数据集,则需要设置训练集的百分比,类型为 0-100 之间的任意整数,需要保证和val_percent值加和为 100;val_percent: 如果重新划分数据集,则需要设置验证集的百分比,类型为 0-100 之间的任意整数,需要保证和train_percent值加和为 100;
数据划分时,原有标注文件会被在原路径下重命名为 xxx.bak,以上参数同样支持通过追加命令行参数的方式进行设置,例如重新划分数据集并设置训练集与验证集比例:-o CheckDataset.split.enable=True -o CheckDataset.split.train_percent=80 -o CheckDataset.split.val_percent=20。
5. 模型训练和评估¶
5.1 模型训练¶
在训练之前,请确保您已经对数据集进行了校验。完成 PaddleX 模型的训练,只需如下一条命令:
python main.py -c paddlex/configs/modules/seal_text_detection/PP-OCRv4_server_seal_det.yaml \
-o Global.mode=train \
-o Global.dataset_dir=./dataset/practical_seal \
-o Train.epochs_iters=30 \
-o Train.batch_size=4 \
-o Train.learning_rate=0.0001
在 PaddleX 中模型训练支持:修改训练超参数、单机单卡/多卡训练等功能,只需修改配置文件或追加命令行参数。
PaddleX 中每个模型都提供了模型开发的配置文件,用于设置相关参数。模型训练相关的参数可以通过修改配置文件中 Train 下的字段进行设置,配置文件中部分参数的示例说明如下:
Global:mode:模式,支持数据校验(check_dataset)、模型训练(train)、模型评估(evaluate);device:训练设备,可选cpu、gpu、xpu、npu、mlu,除 cpu 外,多卡训练可指定卡号,如:gpu:0,1,2,3;
Train:训练超参数设置;epochs_iters:训练轮次数设置;learning_rate:训练学习率设置;
更多超参数介绍,请参考 PaddleX 通用模型配置文件参数说明。
注:
- 以上参数可以通过追加令行参数的形式进行设置,如指定模式为模型训练:-o Global.mode=train;指定前 2 卡 gpu 训练:-o Global.device=gpu:0,1;设置训练轮次数为 10:-o Train.epochs_iters=10。
- 模型训练过程中,PaddleX 会自动保存模型权重文件,默认为output,如需指定保存路径,可通过配置文件中 -o Global.output 字段
- PaddleX 对您屏蔽了动态图权重和静态图权重的概念。在模型训练的过程中,会同时产出动态图和静态图的权重,在模型推理时,默认选择静态图权重推理。
训练产出解释:
在完成模型训练后,所有产出保存在指定的输出目录(默认为./output/)下,通常有以下产出:
- train_result.json:训练结果记录文件,记录了训练任务是否正常完成,以及产出的权重指标、相关文件路径等;
- train.log:训练日志文件,记录了训练过程中的模型指标变化、loss 变化等;
- config.yaml:训练配置文件,记录了本次训练的超参数的配置;
- .pdparams、.pdopt、.pdstates、.pdiparams、.pdmodel:模型权重相关文件,包括网络参数、优化器、静态图网络参数、静态图网络结构等;
5.2 模型评估¶
在完成模型训练后,可以对指定的模型权重文件在验证集上进行评估,验证模型精度。使用 PaddleX 进行模型评估,只需一行命令:
python main.py -c paddlex/configs/modules/seal_text_detection/PP-OCRv4_server_seal_det.yaml \
-o Global.mode=evaluate \
-o Global.dataset_dir=./dataset/practical_seal
与模型训练类似,模型评估支持修改配置文件或追加命令行参数的方式设置。
注: 在模型评估时,需要指定模型权重文件路径,每个配置文件中都内置了默认的权重保存路径,如需要改变,只需要通过追加命令行参数的形式进行设置即可,如-o Evaluate.weight_path=./output/best_accuracy/best_accuracy.pdparams。
5.3 模型调优¶
在学习了模型训练和评估后,我们可以通过调整超参数来提升模型的精度。通过合理调整训练轮数,您可以控制模型的训练深度,避免过拟合或欠拟合;而学习率的设置则关乎模型收敛的速度和稳定性。因此,在优化模型性能时,务必审慎考虑这两个参数的取值,并根据实际情况进行灵活调整,以获得最佳的训练效果。
推荐在调试参数时遵循控制变量法:
1. 首先固定训练轮次为 30,批大小为 4。
2. 基于 PP-OCRv4_server_seal_det 模型启动三个实验,学习率分别为:0.001,0.0001,0.00001。
3. 可以发现实验1精度最高的配置为学习率为 0.001,同时观察验证集分数,精度在最后几轮仍在上涨。因此可以提升训练轮次为 100,模型精度会有进一步的提升。
学习率探寻实验结果:
| 实验ID | 学习率 | 检测 Hmean(%) |
|---|---|---|
| 1 | 0.001 | 97.35 |
| 2 | 0.0001 | 93.32 |
| 3 | 0.00001 | 87.63 |
接下来,我们可以在学习率设置为 0.001 的基础上,增加训练轮次,对比下面实验 [1,4] 可知,训练轮次增大,模型精度有了进一步的提升。
| 实验ID | 训练轮次 | 检测 Hmean(%) |
|---|---|---|
| 1 | 30 | 97.35 |
| 4 | 100 | 98.13 |
注:本教程为 4 卡教程,如果您只有 1 张 GPU,可通过调整训练卡数完成本次实验,但最终指标未必和上述指标完全对齐,属正常情况。
在选择训练环境时,要考虑训练卡数和总 batch_size,以及学习率的关系。首先训练卡数乘以单卡 batch_size 等于总 batch_size。其次,总 batch_size 和学习率是相关的,学习率应与总 batch_size 保持同步调整。 目前默认学习率对应基于 4 卡训练的总 batch_size,若您打算在单卡环境下进行训练,则设置学习率时需相应除以 4。若您打算在 8 卡环境下进行训练,则设置学习率时需相应乘以 2。
调整不同参数执行训练的命令可以参考:
python main.py -c paddlex/configs/modules/seal_text_detection/PP-OCRv4_server_seal_det.yaml \
-o Global.mode=train \
-o Global.dataset_dir=./dataset/practical_seal \
-o Train.learning_rate=0.0001 \
-o Train.epochs_iters=30 \
-o Train.batch_size=4
6. 产线测试¶
将产线中的模型替换为微调后的模型进行测试,使用 印章测试文件,进行预测:
首先获取并更新文档信息抽取v3的配置文件,执行下面的命令获取配置文件,(假设自定义保存位置为 ./my_path ):
参考2.1 填写大语言模型的 ak/sk(access_token), 并将PP-ChatOCRv3-doc.yaml中的SubPipelines.SealRecognition.SealOCR.SubModules.TextDetection.model_dir字段修改为上面微调后的模型路径,修改后配置如下:
......
SubPipelines:
...
SealRecognition:
...
SealOCR:
...
SubModules:
TextDetection:
module_name: seal_text_detection
model_name: PP-OCRv4_server_seal_det
model_dir: output/best_accuracy/inference # 修改为微调后的模型路径
limit_side_len: 736
limit_type: min
max_side_limit: 4000
thresh: 0.2
box_thresh: 0.6
unclip_ratio: 0.5
......
修改后,只需要修改 create_pipeline 方法中的 pipeline 参数值为产线配置文件路径即可应用配置。
from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="./my_path/PP-ChatOCRv3-doc.yaml")
visual_predict_res = pipeline.visual_predict(input="https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/doc_images/practical_tutorial/PP-ChatOCRv3_doc_seal/test.png",
use_doc_orientation_classify=False,
use_doc_unwarping=False,
use_common_ocr=True,
use_seal_recognition=True,
use_table_recognition=True)
visual_info_list = []
for res in visual_predict_res:
visual_info_list.append(res["visual_info"])
layout_parsing_result = res["layout_parsing_result"]
layout_parsing_result.save_to_img("./output_ft")
vector_info = pipeline.build_vector(visual_info_list, flag_save_bytes_vector=True)
chat_result = pipeline.chat(key_list=["印章名称"], visual_info=visual_info_list, vector_info=vector_info)
print(chat_result)
通过上述可在./output_ft下生成预测结果,打印的关键信息抽取结果:
可以发现,在模型微调之后,关键信息已经被正确的提取出来。
印章文本检测的可视化结果如下,已经正确抽取印章信息:

7. 开发集成/部署¶
如果文档场景信息抽取v3产线可以达到您对产线推理速度和精度的要求,您可以直接进行开发集成/部署。
- 直接将训练好的模型产线应用在您的 Python 项目中,如下面代码所示:
from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="./my_path/PP-ChatOCRv3-doc.yaml")
visual_predict_res = pipeline.visual_predict(input="https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/doc_images/practical_tutorial/PP-ChatOCRv3_doc_seal/test.png",
use_doc_orientation_classify=False,
use_doc_unwarping=False,
use_common_ocr=True,
use_seal_recognition=True,
use_table_recognition=True)
visual_info_list = []
for res in visual_predict_res:
visual_info_list.append(res["visual_info"])
layout_parsing_result = res["layout_parsing_result"]
vector_info = pipeline.build_vector(visual_info_list, flag_save_bytes_vector=True)
chat_result = pipeline.chat(key_list=["印章名称"], visual_info=visual_info_list, vector_info=vector_info)
更多参数请参考 文档场景信息抽取v3产线使用教程。
-
此外,PaddleX 也提供了其他三种部署方式,详细说明如下:
-
高性能部署:在实际生产环境中,许多应用对部署策略的性能指标(尤其是响应速度)有着较严苛的标准,以确保系统的高效运行与用户体验的流畅性。为此,PaddleX 提供高性能推理插件,旨在对模型推理及前后处理进行深度性能优化,实现端到端流程的显著提速,详细的高性能部署流程请参考 PaddleX 高性能部署指南。
- 服务化部署:服务化部署是实际生产环境中常见的一种部署形式。通过将推理功能封装为服务,客户端可以通过网络请求来访问这些服务,以获取推理结果。PaddleX 支持用户以低成本实现产线的服务化部署,详细的服务化部署流程请参考 PaddleX 服务化部署指南。
- 端侧部署:端侧部署是一种将计算和数据处理功能放在用户设备本身上的方式,设备可以直接处理数据,而不需要依赖远程的服务器。PaddleX 支持将模型部署在 Android 等端侧设备上,详细的端侧部署流程请参考 PaddleX端侧部署指南。
您可以根据需要选择合适的方式部署模型产线,进而进行后续的 AI 应用集成。