PaddleX图像分类任务模块数据标注教程¶
本文档将介绍如何使用Labelme标注工具完成图像分类相关单模型的数据标注。 点击上述链接,参考⾸⻚⽂档即可安装数据标注⼯具并查看详细使⽤流程。
1. Labelme 标注¶
1.1 Labelme 标注工具介绍¶
Labelme 是一个 python 语言编写,带有图形界面的图像标注软件。可用于图像分类、目标检测、图像分割等任务,在实例分割的标注任务中,标签存储为 JSON 文件。
1.2 Labelme 安装¶
为避免环境冲突,建议在 conda 环境下安装。.
1.3 Labelme 标注过程¶
1.3.1 准备待标注数据¶
- 创建数据集根目录,如
pets。 - 在
pets中创建images目录(必须为images目录),并将待标注图片存储在images目录下,如下图所示:
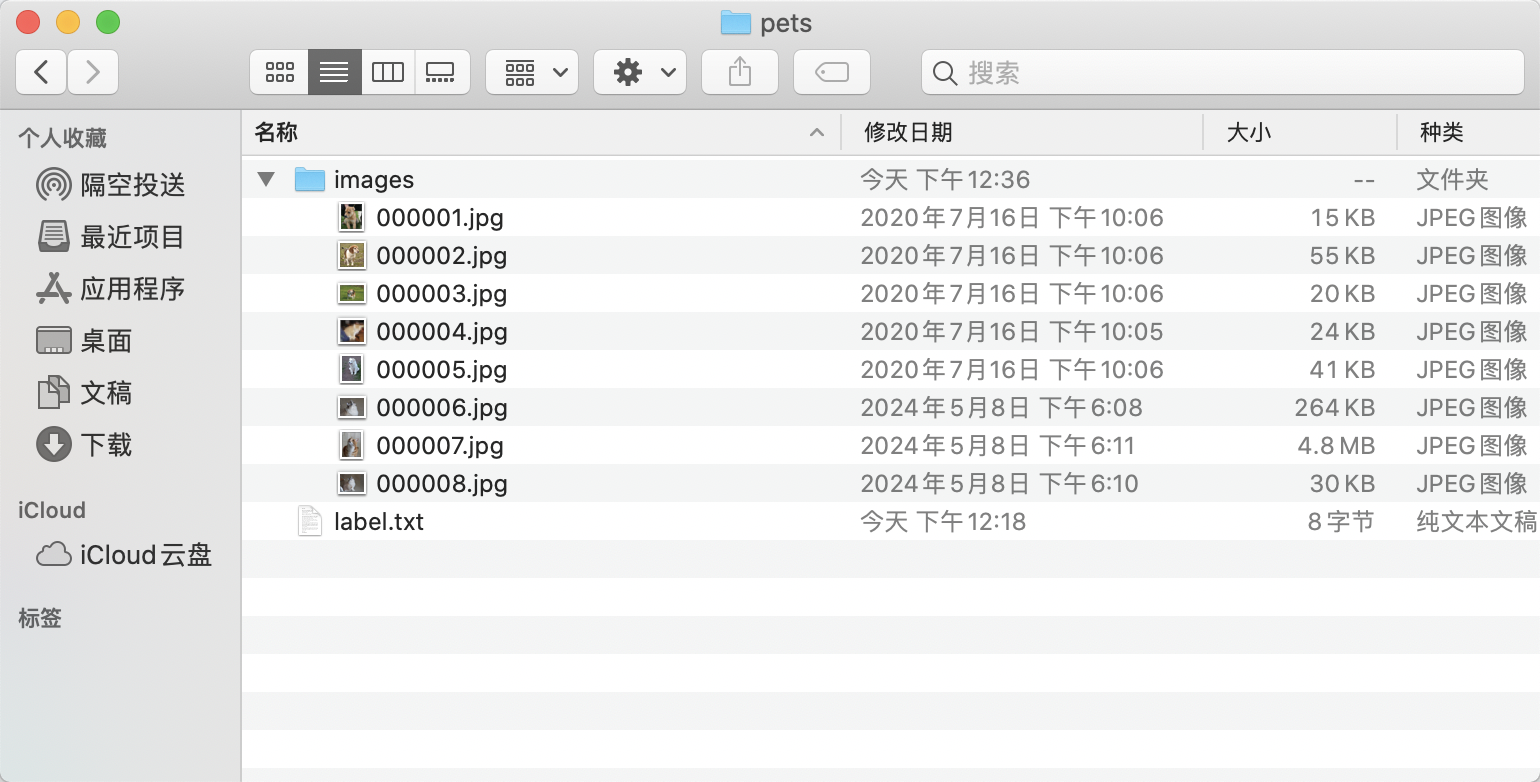
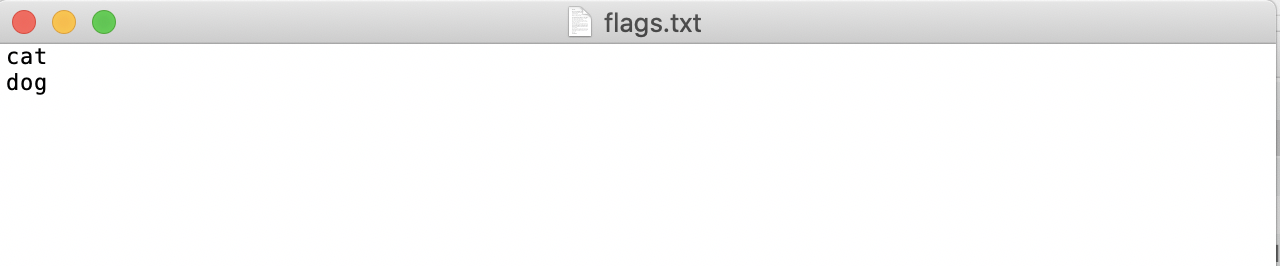
- 在
pets文件夹中创建待标注数据集的类别标签文件flags.txt,并在flags.txt中按行写入待标注数据集的类别。以猫狗分类数据集的flags.txt为例,如下图所示:
1.3.2 启动 Labelme¶
终端进入到待标注数据集根目录,并启动 labelme 标注工具。
flags 为图像创建分类标签,传入标签路径。
* nodata 停止将图像数据存储到 JSON 文件。
* autosave 自动存储。
* output 标签文件存储路径。
1.3.3 开始图片标注¶
- 启动
labelme后如图所示:
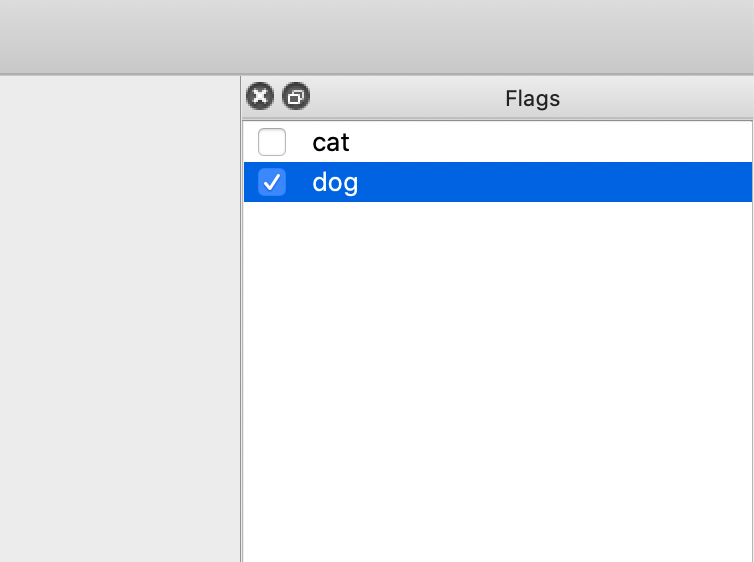
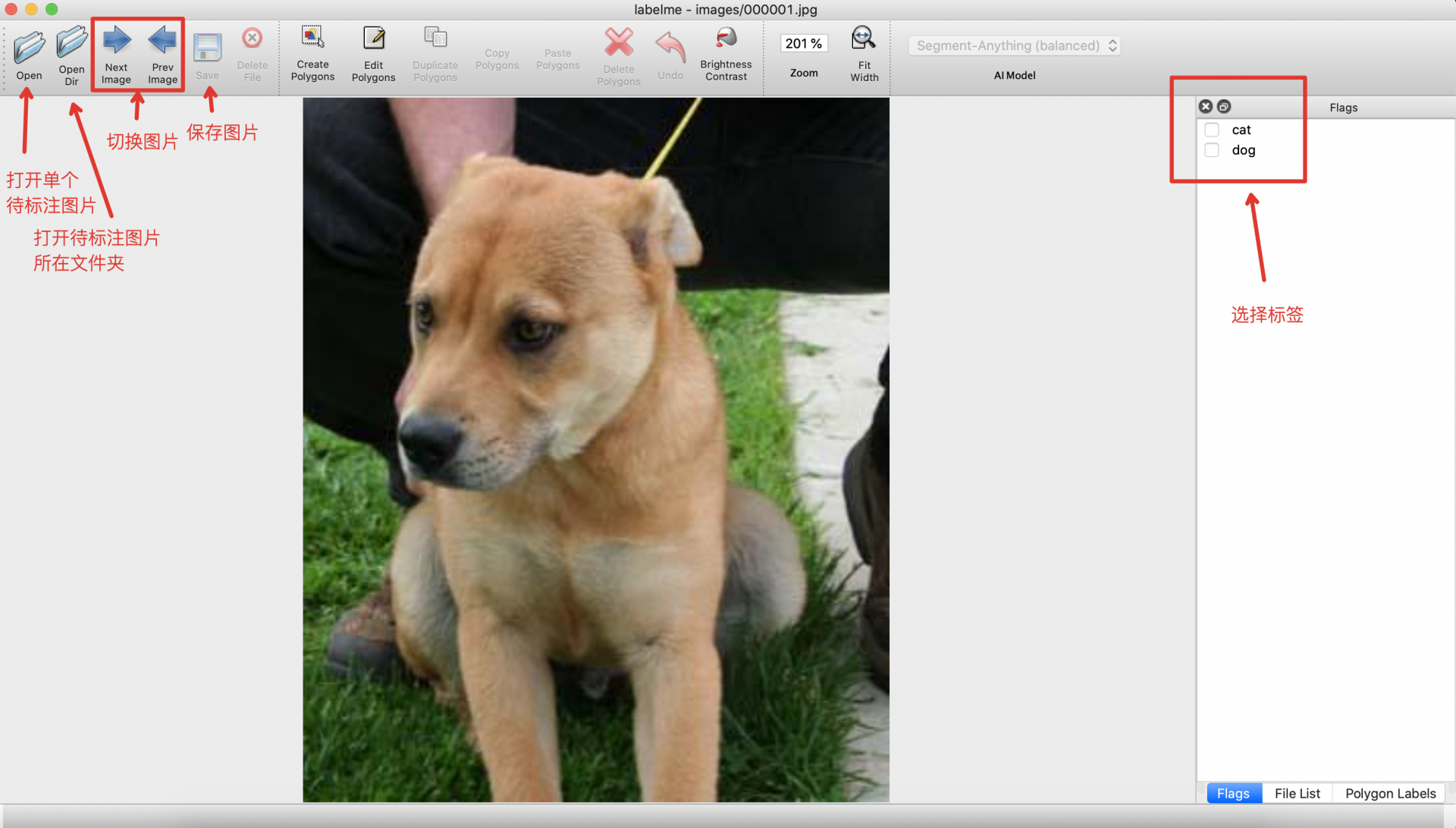 * 在
* 在 Flags 界面选择类别。
- 标注好后点击存储。(若在启动
labelme时未指定output字段,会在第一次存储时提示选择存储路径,若指定autosave字段使用自动保存,则无需点击存储按钮)。
 * 然后点击
* 然后点击 Next Image 进行下一张图片的标注。

- 完成全部图片的标注后,使用convert_to_imagenet.py脚本将标注好的数据集转换为
ImageNet-1k数据集格式,生成train.txt,val.txt和label.txt。
dataset_path为标注的 labelme 格式分类数据集。
- 经过整理得到的最终目录结构如下:
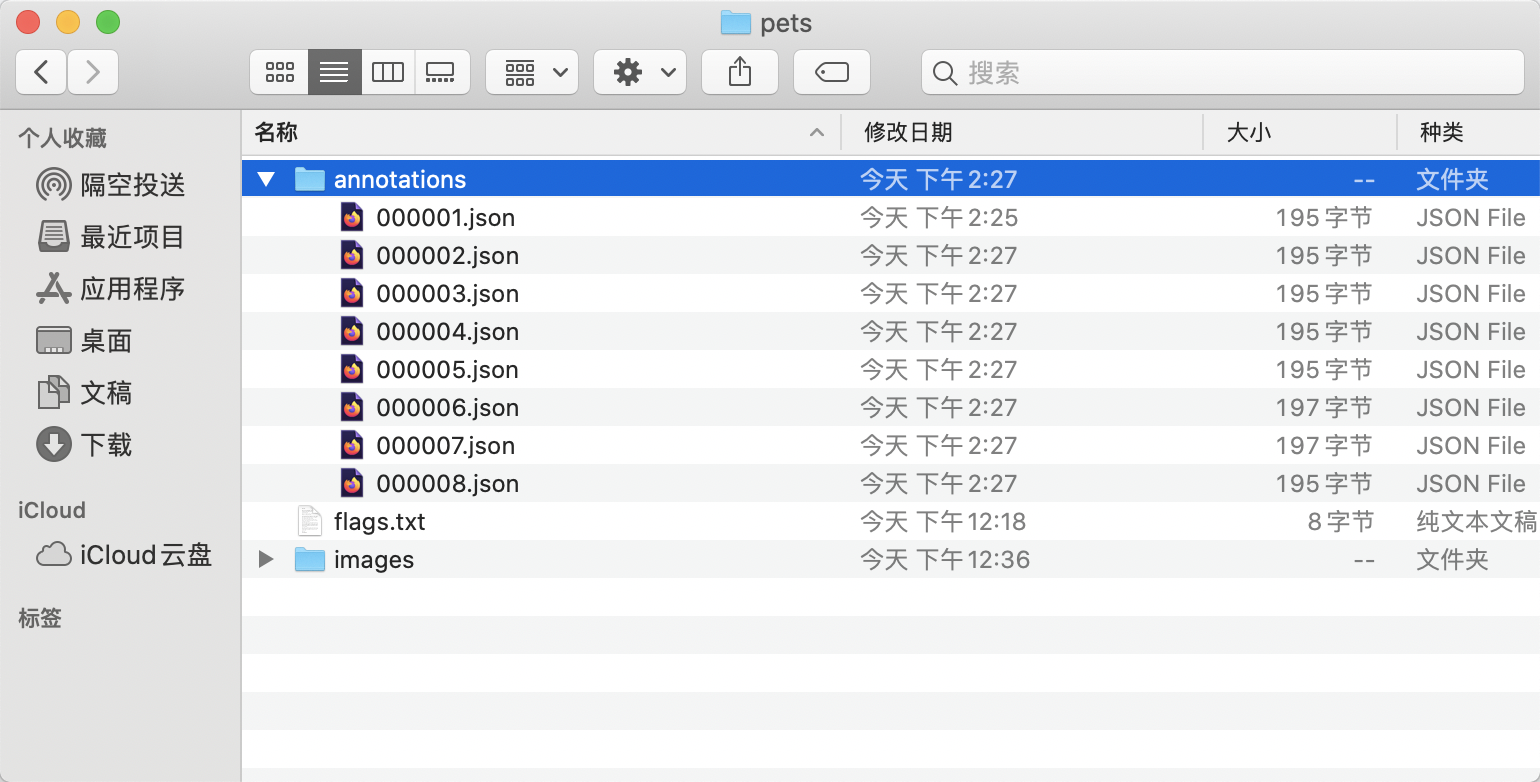
2. 数据格式¶
- PaddleX 针对图像分类任务定义的数据集,名称是 ClsDataset,组织结构和标注格式如下:
dataset_dir # 数据集根目录,目录名称可以改变
├── images # 图像的保存目录,目录名称可以改变,但要注意与train.txt、val.txt的内容对应
├── label.txt # 标注id和类别名称的对应关系,文件名称不可改变。每行给出类别id和类别名称,内容举例:45 wallflower
├── train.txt # 训练集标注文件,文件名称不可改变。每行给出图像路径和图像类别id,使用空格分隔,内容举例:images/image_06765.jpg 0
└── val.txt # 验证集标注文件,文件名称不可改变。每行给出图像路径和图像类别id,使用空格分隔,内容举例:images/image_06767.jpg 10
dataset_dir # 数据集根目录,目录名称可以改变
├── images # 图像的保存目录,目录名称可以改变
├── train # 训练集目录,目录名称可以改变
├── class0 # 类名字,最好是有意义的名字,否则生成的类别映射文件label.txt无意义
├── xxx.jpg # 图片,此处支持层级嵌套
├── xxx.jpg # 图片,此处支持层级嵌套
...
├── class1 # 类名字,最好是有意义的名字,否则生成的类别映射文件label.txt无意义
...
├── val # 验证集目录,目录名称可以改变
train_list.txt、val_list.txt、test_list.txt修改为train.txt、val.txt、test.txt,并且按照规则修改 label.txt 即可。
原版label.txt:
label.txt: