通用目标检测产线使用教程¶
1. 通用目标检测产线介绍¶
目标检测旨在识别图像或视频中多个对象的类别及其位置,通过生成边界框来标记这些对象。与简单的图像分类不同,目标检测不仅需要识别出图像中有哪些物体,例如人、车和动物等,还需要准确地确定每个物体在图像中的具体位置,通常以矩形框的形式表示。该技术广泛应用于自动驾驶、监控系统和智能相册等领域,依赖于深度学习模型(如YOLO、Faster R-CNN等),这些模型能够高效地提取特征并进行实时检测,显著提升了计算机对图像内容理解的能力。
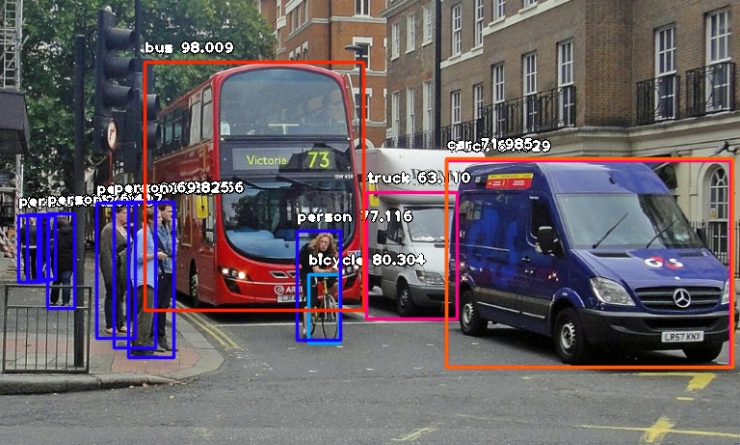 通用目标检测产线中包含了目标检测模块,如您更考虑模型精度,请选择精度较高的模型,如您更考虑模型推理速度,请选择推理速度较快的模型,如您更考虑模型存储大小,请选择存储大小较小的模型。
通用目标检测产线中包含了目标检测模块,如您更考虑模型精度,请选择精度较高的模型,如您更考虑模型推理速度,请选择推理速度较快的模型,如您更考虑模型存储大小,请选择存储大小较小的模型。
推理耗时仅包含模型推理耗时,不包含前后处理耗时。
| 模型 | 模型下载链接 | mAP(%) | GPU推理耗时(ms) [常规模式 / 高性能模式] |
CPU推理耗时(ms) [常规模式 / 高性能模式] |
模型存储大小(MB) | 介绍 |
|---|---|---|---|---|---|---|
| PicoDet-L | 推理模型/训练模型 | 42.6 | 14.31 / 11.06 | 45.95 / 25.06 | 20.9 | PP-PicoDet是一种全尺寸、棱视宽目标的轻量级目标检测算法,它考虑移动端设备运算量。与传统目标检测算法相比,PP-PicoDet具有更小的模型尺寸和更低的计算复杂度,并在保证检测精度的同时更高的速度和更低的延迟。 |
| PicoDet-S | 推理模型/训练模型 | 29.1 | 9.15 / 3.26 | 16.06 / 4.04 | 4.4 | |
| PP-YOLOE_plus-L | 推理模型/训练模型 | 52.9 | 32.06 / 28.00 | 185.32 / 116.21 | 185.3 | PP-YOLOE_plus 是一种是百度飞桨视觉团队自研的云边一体高精度模型PP-YOLOE迭代优化升级的版本,通过使用Objects365大规模数据集、优化预处理,大幅提升了模型端到端推理速度。 |
| PP-YOLOE_plus-S | 推理模型/训练模型 | 43.7 | 11.43 / 7.52 | 60.16 / 26.94 | 28.3 | |
| RT-DETR-H | 推理模型/训练模型 | 56.3 | 114.57 / 101.56 | 938.20 / 938.20 | 435.8 | RT-DETR是第一个实时端到端目标检测器。该模型设计了一个高效的混合编码器,满足模型效果与吞吐率的双需求,高效处理多尺度特征,并提出了加速和优化的查询选择机制,以优化解码器查询的动态化。RT-DETR支持通过使用不同的解码器来实现灵活端到端推理速度。 |
| RT-DETR-L | 推理模型/训练模型 | 53.0 | 34.76 / 27.60 | 495.39 / 247.68 | 113.7 |
❗ 以上列出的是目标检测模块重点支持的6个核心模型,该模块总共支持37个模型,完整的模型列表如下:
👉模型列表详情
| 模型 | 模型下载链接 | mAP(%) | GPU推理耗时(ms) [常规模式 / 高性能模式] |
CPU推理耗时(ms) [常规模式 / 高性能模式] |
模型存储大小(MB) | 介绍 |
|---|---|---|---|---|---|---|
| Cascade-FasterRCNN-ResNet50-FPN | 推理模型/训练模型 | 41.1 | 120.28 / 120.28 | - / 6514.61 | 245.4 | Cascade-FasterRCNN 是一种改进的Faster R-CNN目标检测模型,通过耦联多个检测器,利用不同IoU阈值优化检测结果,解决训练和预测阶段的mismatch问题,提高目标检测的准确性。 |
| Cascade-FasterRCNN-ResNet50-vd-SSLDv2-FPN | 推理模型/训练模型 | 45.0 | 124.10 / 124.10 | - / 6709.52 | 246.2 | |
| CenterNet-DLA-34 | 推理模型/训练模型 | 37.6 | 67.19 / 67.19 | 6622.61 / 6622.61 | 75.4 | CenterNet是一种anchor-free目标检测模型,把待检测物体的关键点视为单一点-即其边界框的中心点,并通过关键点进行回归。 |
| CenterNet-ResNet50 | 推理模型/训练模型 | 38.9 | 216.06 / 216.06 | 2545.79 / 2545.79 | 319.7 | |
| DETR-R50 | 推理模型/训练模型 | 42.3 | 58.80 / 26.90 | 370.96 / 208.77 | 159.3 | DETR 是Facebook提出的一种transformer目标检测模型,该模型在不需要预定义的先验框anchor和NMS的后处理策略的情况下,就可以实现端到端的目标检测。 |
| FasterRCNN-ResNet34-FPN | 推理模型/训练模型 | 37.8 | 76.90 / 76.90 | - / 4136.79 | 137.5 | Faster R-CNN是典型的two-stage目标检测模型,即先生成区域建议(Region Proposal),然后在生成的Region Proposal上做分类和回归。相较于前代R-CNN和Fast R-CNN,Faster R-CNN的改进主要在于区域建议方面,使用区域建议网络(Region Proposal Network, RPN)提供区域建议,以取代传统选择性搜索。RPN是卷积神经网络,并与检测网络共享图像的卷积特征,减少了区域建议的计算开销。 |
| FasterRCNN-ResNet50-FPN | 推理模型/训练模型 | 38.4 | 95.48 / 95.48 | - / 3693.90 | 148.1 | |
| FasterRCNN-ResNet50-vd-FPN | 推理模型/训练模型 | 39.5 | 98.03 / 98.03 | - / 4278.36 | 148.1 | |
| FasterRCNN-ResNet50-vd-SSLDv2-FPN | 推理模型/训练模型 | 41.4 | 99.23 / 99.23 | - / 4415.68 | 148.1 | |
| FasterRCNN-ResNet50 | 推理模型/训练模型 | 36.7 | 129.10 / 129.10 | - / 3868.44 | 120.2 | |
| FasterRCNN-ResNet101-FPN | 推理模型/训练模型 | 41.4 | 131.48 / 131.48 | - / 4380.00 | 216.3 | |
| FasterRCNN-ResNet101 | 推理模型/训练模型 | 39.0 | 216.71 / 216.71 | - / 5376.45 | 188.1 | |
| FasterRCNN-ResNeXt101-vd-FPN | 推理模型/训练模型 | 43.4 | 234.38 / 234.38 | - / 6154.61 | 360.6 | |
| FasterRCNN-Swin-Tiny-FPN | 推理模型/训练模型 | 42.6 | 65.92 / 65.92 | - / 2468.98 | 159.8 | |
| FCOS-ResNet50 | 推理模型/训练模型 | 39.6 | 101.02 / 34.42 | 752.15 / 752.15 | 124.2 | FCOS是一种密集预测的anchor-free目标检测模型,使用RetinaNet的骨架,直接在feature map上回归目标物体的长宽,并预测物体的类别以及centerness(feature map上像素点离物体中心的偏移程度),centerness最终会作为权重来调整物体得分。 |
| PicoDet-L | 推理模型/训练模型 | 42.6 | 14.31 / 11.06 | 45.95 / 25.06 | 20.9 | PP-PicoDet是一种全尺寸、棱视宽目标的轻量级目标检测算法,它考虑移动端设备运算量。与传统目标检测算法相比,PP-PicoDet具有更小的模型尺寸和更低的计算复杂度,并在保证检测精度的同时更高的速度和更低的延迟。 |
| PicoDet-M | 推理模型/训练模型 | 37.5 | 10.48 / 5.00 | 22.88 / 9.03 | 16.8 | |
| PicoDet-S | 推理模型/训练模型 | 29.1 | 9.15 / 3.26 | 16.06 / 4.04 | 4.4 | |
| PicoDet-XS | 推理模型/训练模型 | 26.2 | 9.54 / 3.52 | 17.96 / 5.38 | 5.7 | |
| PP-YOLOE_plus-L | 推理模型/训练模型 | 52.9 | 32.06 / 28.00 | 185.32 / 116.21 | 185.3 | PP-YOLOE_plus 是一种是百度飞桨视觉团队自研的云边一体高精度模型PP-YOLOE迭代优化升级的版本,通过使用Objects365大规模数据集、优化预处理,大幅提升了模型端到端推理速度。 |
| PP-YOLOE_plus-M | 推理模型/训练模型 | 49.8 | 18.37 / 15.04 | 108.77 / 63.48 | 82.3 | |
| PP-YOLOE_plus-S | 推理模型/训练模型 | 43.7 | 11.43 / 7.52 | 60.16 / 26.94 | 28.3 | |
| PP-YOLOE_plus-X | 推理模型/训练模型 | 54.7 | 56.28 / 50.60 | 292.08 / 212.24 | 349.4 | |
| RT-DETR-H | 推理模型/训练模型 | 56.3 | 114.57 / 101.56 | 938.20 / 938.20 | 435.8 | RT-DETR是第一个实时端到端目标检测器。该模型设计了一个高效的混合编码器,满足模型效果与吞吐率的双需求,高效处理多尺度特征,并提出了加速和优化的查询选择机制,以优化解码器查询的动态化。RT-DETR支持通过使用不同的解码器来实现灵活端到端推理速度。 |
| RT-DETR-L | 推理模型/训练模型 | 53.0 | 34.76 / 27.60 | 495.39 / 247.68 | 113.7 | |
| RT-DETR-R18 | 推理模型/训练模型 | 46.5 | 19.11 / 14.82 | 263.13 / 143.05 | 70.7 | |
| RT-DETR-R50 | 推理模型/训练模型 | 53.1 | 41.11 / 10.12 | 536.20 / 482.86 | 149.1 | |
| RT-DETR-X | 推理模型/训练模型 | 54.8 | 61.91 / 51.41 | 639.79 / 639.79 | 232.9 | |
| YOLOv3-DarkNet53 | 推理模型/训练模型 | 39.1 | 39.62 / 35.54 | 166.57 / 136.34 | 219.7 | YOLOv3是一种实时的端到端目标检测器。它使用一个独特的单个卷积神经网络,将目标检测问题分解为一个回归问题,从而实现实时的检测。该模型采用了多个尺度的检测,提高了不同尺度目标物体的检测性能。 |
| YOLOv3-MobileNetV3 | 推理模型/训练模型 | 31.4 | 16.54 / 6.21 | 64.37 / 45.55 | 83.8 | |
| YOLOv3-ResNet50_vd_DCN | 推理模型/训练模型 | 40.6 | 31.64 / 26.72 | 226.75 / 226.75 | 163.0 | |
| YOLOX-L | 推理模型/训练模型 | 50.1 | 49.68 / 45.03 | 232.52 / 156.24 | 192.5 | YOLOX模型以YOLOv3作为目标检测网络的框架,通过设计Decoupled Head、Data Aug、Anchor Free以及SimOTA组件,显著提升了模型在各种复杂场景下的检测性能。 |
| YOLOX-M | 推理模型/训练模型 | 46.9 | 43.46 / 29.52 | 147.64 / 80.06 | 90.0 | |
| YOLOX-N | 推理模型/训练模型 | 26.1 | 42.94 / 17.79 | 64.15 / 7.19 | 3.4 | |
| YOLOX-S | 推理模型/训练模型 | 40.4 | 46.53 / 29.34 | 98.37 / 35.02 | 32.0 | |
| YOLOX-T | 推理模型/训练模型 | 32.9 | 31.81 / 18.91 | 55.34 / 11.63 | 18.1 | |
| YOLOX-X | 推理模型/训练模型 | 51.8 | 84.06 / 77.28 | 390.38 / 272.88 | 351.5 | |
| Co-Deformable-DETR-R50 | 推理模型/训练模型 | 49.7 | 259.62 / 259.62 | 32413.76 / 32413.76 | 184 | Co-DETR是一种先进的端到端目标检测器。它基于DETR架构,通过引入协同混合分配训练策略,将目标检测任务中的传统一对多标签分配与一对一匹配相结合,从而显著提高了检测性能和训练效率 |
| Co-Deformable-DETR-Swin-T | 推理模型/训练模型 | 48.0(640x640 输入尺寸下) | 120.17 / 120.17 | - / 15620.29 | 187 | |
| Co-DINO-R50 | 推理模型/训练模型 | 52.0 | 1123.23 / 1123.23 | - / - | 186 | |
| Co-DINO-Swin-L | 推理模型/训练模型 | 55.9 (640x640 输入尺寸下) | - / - | - / - | 840 |
- 性能测试环境
- 测试数据集: COCO2017验证集。
- 硬件配置:
- GPU:NVIDIA Tesla T4
- CPU:Intel Xeon Gold 6271C @ 2.60GHz
- 软件环境:
- Ubuntu 20.04 / CUDA 11.8 / cuDNN 8.9 / TensorRT 8.6.1.6
- paddlepaddle 3.0.0 / paddlex 3.0.3
- 推理模式说明
| 模式 | GPU配置 | CPU配置 | 加速技术组合 |
|---|---|---|---|
| 常规模式 | FP32精度 / 无TRT加速 | FP32精度 / 8线程 | PaddleInference |
| 高性能模式 | 选择先验精度类型和加速策略的最优组合 | FP32精度 / 8线程 | 选择先验最优后端(Paddle/OpenVINO/TRT等) |
2. 快速开始¶
PaddleX 所提供的预训练的模型产线均可以快速体验效果,你可以在线体验通用目标检测产线的效果,也可以在本地使用命令行或 Python 体验通用目标检测产线的效果。
2.1 在线体验¶
您可以在线体验通用目标检测产线的效果,用官方提供的 demo 图片进行识别,例如:

如果您对产线运行的效果满意,可以直接对产线进行集成部署,如果不满意,您也可以利用私有数据对产线中的模型进行在线微调。
2.2 本地体验¶
在本地使用通用目标检测产线前,请确保您已经按照PaddleX本地安装教程完成了PaddleX的wheel包安装。如果您希望选择性安装依赖,请参考安装教程中的相关说明。该产线对应的依赖分组为 cv。
2.2.1 命令行方式体验¶
一行命令即可快速体验目标检测产线效果,使用 测试文件,并将 --input 替换为本地路径,进行预测
{kind=link}
paddlex --pipeline object_detection \
--input general_object_detection_002.png \
--threshold 0.5 \
--save_path ./output/ \
--device gpu:0
可视化结果保存至save_path,如下所示:

2.2.2 Python脚本方式集成¶
通过上述命令行方式可快速体验查看效果,在项目中往往需要代码集成,您可以通过如下几行代码完成产线的快速推理:
from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="object_detection")
output = pipeline.predict("general_object_detection_002.png", threshold=0.5)
for res in output:
res.print()
res.save_to_img("./output/")
res.save_to_json("./output/")
在上述 Python 脚本中,执行了如下几个步骤:
(1)调用 create_pipeline 实例化产线对象:具体参数说明如下:
| 参数 | 参数说明 | 参数类型 | 默认值 | |
|---|---|---|---|---|
pipeline |
产线名称或是产线配置文件路径。如为产线名称,则必须为 PaddleX 所支持的产线。 | str |
None |
|
config |
产线具体的配置信息(如果和pipeline同时设置,优先级高于pipeline,且要求产线名和pipeline一致)。 |
dict[str, Any] |
None |
device |
产线推理设备。支持指定GPU具体卡号,如“gpu:0”,其他硬件具体卡号,如“npu:0”,CPU如“cpu”。支持同时指定多个设备以进行并行推理,详情请参考产线并行推理文档。 | str |
gpu:0 |
use_hpip |
是否启用高性能推理插件。如果为 None,则使用配置文件或 config 中的配置。 |
bool | None |
无 | None |
hpi_config |
高性能推理配置 | dict | None |
无 | None |
2)调用通用目标检测产线对象的 predict() 方法进行推理预测。该方法将返回一个 generator。以下是 predict() 方法的参数及其说明:
| 参数 | 参数说明 | 参数类型 | 可选项 | 默认值 |
|---|---|---|---|---|
input |
待预测数据,支持多种输入类型,必填 | Python Var|str|list |
|
无 |
threshold |
用于过滤掉低置信度预测结果的阈值;如果不指定,则默认使用PaddleX官方模型配置 | float/dict/None |
|
None |
{kind=link}
(3)对预测结果进行处理,每个样本的预测结果均为对应的Result对象,且支持打印、保存为图片、保存为json文件的操作:
| 方法 | 方法说明 | 参数 | 参数类型 | 参数说明 | 默认值 |
|---|---|---|---|---|---|
print() |
打印结果到终端 | format_json |
bool |
是否对输出内容进行使用 JSON 缩进格式化 |
True |
indent |
int |
指定缩进级别,以美化输出的 JSON 数据,使其更具可读性,仅当 format_json 为 True 时有效 |
4 | ||
ensure_ascii |
bool |
控制是否将非 ASCII 字符转义为 Unicode。设置为 True 时,所有非 ASCII 字符将被转义;False 则保留原始字符,仅当format_json为True时有效 |
False |
||
save_to_json() |
将结果保存为json格式的文件 | save_path |
str |
保存的文件路径,当为目录时,保存文件命名与输入文件类型命名一致 | 无 |
indent |
int |
指定缩进级别,以美化输出的 JSON 数据,使其更具可读性,仅当 format_json 为 True 时有效 |
4 | ||
ensure_ascii |
bool |
控制是否将非 ASCII 字符转义为 Unicode。设置为 True 时,所有非 ASCII 字符将被转义;False 则保留原始字符,仅当format_json为True时有效 |
False |
||
save_to_img() |
将结果保存为图像格式的文件 | save_path |
str |
保存的文件路径,支持目录或文件路径 | 无 |
- 调用
print()方法会将如下结果打印到终端:
{'res': {'input_path': 'general_object_detection_002.png', 'page_index': None, 'boxes': [{'cls_id': 49, 'label': 'orange', 'score': 0.8188614249229431, 'coordinate': [661.3518, 93.05823, 870.75903, 305.93713]}, {'cls_id': 47, 'label': 'apple', 'score': 0.7745078206062317, 'coordinate': [76.80911, 274.74905, 330.5422, 520.0428]}, {'cls_id': 47, 'label': 'apple', 'score': 0.7271787524223328, 'coordinate': [285.32645, 94.3175, 469.73645, 297.40344]}, {'cls_id': 46, 'label': 'banana', 'score': 0.5576589703559875, 'coordinate': [310.8041, 361.43625, 685.1869, 712.59155]}, {'cls_id': 47, 'label': 'apple', 'score': 0.5490103363990784, 'coordinate': [764.6252, 285.76096, 924.8153, 440.92892]}, {'cls_id': 47, 'label': 'apple', 'score': 0.515821635723114, 'coordinate': [853.9831, 169.41423, 987.803, 303.58615]}, {'cls_id': 60, 'label': 'dining table', 'score': 0.514293372631073, 'coordinate': [0.53089714, 0.32445717, 1072.9534, 720]}, {'cls_id': 47, 'label': 'apple', 'score': 0.510750949382782, 'coordinate': [57.368027, 23.455347, 213.39601, 176.45612]}]}}
-
输出结果参数含义如下:
input_path:表示输入图像的路径page_index:如果输入是PDF文件,则表示当前是PDF的第几页,否则为Noneboxes:预测的目标框信息,一个字典列表。每个字典代表一个检出的目标,包含以下信息:cls_id:类别ID,一个整数label:类别标签,一个字符串score:目标框置信度,一个浮点数coordinate:目标框坐标,一个浮点数列表,格式为[xmin, ymin, xmax, ymax]
-
调用
save_to_json()方法会将上述内容保存到指定的save_path中,如果指定为目录,则保存的路径为save_path/{your_img_basename}_res.json,如果指定为文件,则直接保存到该文件中。由于json文件不支持保存numpy数组,因此会将其中的numpy.array类型转换为列表形式。 -
调用
save_to_img()方法会将可视化结果保存到指定的save_path中,如果指定为目录,则保存的路径为save_path/{your_img_basename}_res.{your_img_extension},如果指定为文件,则直接保存到该文件中。(产线通常包含较多结果图片,不建议直接指定为具体的文件路径,否则多张图会被覆盖,仅保留最后一张图) -
此外,也支持通过属性获取带结果的可视化图像和预测结果,具体如下:
| 属性 | 属性说明 |
|---|---|
json |
获取预测的 json 格式的结果 |
img |
获取格式为 dict 的可视化图像 |
json属性获取的预测结果为dict类型的数据,相关内容与调用save_to_json()方法保存的内容一致。img属性返回的预测结果是一个字典类型的数据。键为res,对应的值是一个用于可视化目标检测结果的Image.Image对象。
上述Python脚本集成方式默认使用 PaddleX 官方配置文件中的参数设置,若您需要自定义配置文件,可先执行如下命令获取官方配置文件,并保存在 my_path 中:
若您获取了配置文件,即可对目标检测产线各项配置进行自定义。只需要修改 create_pipeline 方法中的 pipeline 参数值为自定义产线配置文件路径即可。
例如,若您的自定义配置文件保存在 ./my_path/object_detection.yaml ,则只需执行:
from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="./my_path/object_detection.yaml")
output = pipeline.predict("general_object_detection_002.png")
for res in output:
res.print()
res.save_to_img("./output/")
res.save_to_json("./output/")
3. 开发集成/部署¶
如果产线可以达到您对产线推理速度和精度的要求,您可以直接进行开发集成/部署。
若您需要将产线直接应用在您的Python项目中,可以参考 2.2.2 Python脚本方式中的示例代码。
此外,PaddleX 也提供了其他三种部署方式,详细说明如下:
🚀 高性能推理:在实际生产环境中,许多应用对部署策略的性能指标(尤其是响应速度)有着较严苛的标准,以确保系统的高效运行与用户体验的流畅性。为此,PaddleX 提供高性能推理插件,旨在对模型推理及前后处理进行深度性能优化,实现端到端流程的显著提速,详细的高性能推理流程请参考PaddleX高性能推理指南。
☁️ 服务化部署:服务化部署是实际生产环境中常见的一种部署形式。通过将推理功能封装为服务,客户端可以通过网络请求来访问这些服务,以获取推理结果。PaddleX 支持多种产线服务化部署方案,详细的产线服务化部署流程请参考PaddleX服务化部署指南。
以下是基础服务化部署的API参考与多语言服务调用示例:
API参考
对于服务提供的主要操作:
- HTTP请求方法为POST。
- 请求体和响应体均为JSON数据(JSON对象)。
- 当请求处理成功时,响应状态码为
200,响应体的属性如下:
| 名称 | 类型 | 含义 |
|---|---|---|
logId |
string |
请求的UUID。 |
errorCode |
integer |
错误码。固定为0。 |
errorMsg |
string |
错误说明。固定为"Success"。 |
result |
object |
操作结果。 |
- 当请求处理未成功时,响应体的属性如下:
| 名称 | 类型 | 含义 |
|---|---|---|
logId |
string |
请求的UUID。 |
errorCode |
integer |
错误码。与响应状态码相同。 |
errorMsg |
string |
错误说明。 |
服务提供的主要操作如下:
infer
对图像进行目标检测。
POST /object-detection
- 请求体的属性如下:
| 名称 | 类型 | 含义 | 是否必填 |
|---|---|---|---|
image |
string |
服务器可访问的图像文件的URL或图像文件内容的Base64编码结果。 | 是 |
threshold |
number | object | null |
请参阅产线对象中 predict 方法的 threshold 参数相关说明。 |
否 |
visualize |
boolean | null |
是否返回可视化结果图以及处理过程中的中间图像等。
例如,在产线配置文件中添加如下字段: visualize参数可以覆盖默认行为。如果请求体和配置文件中均未设置(或请求体传入null、配置文件中未设置),则默认返回图像。
|
否 |
- 请求处理成功时,响应体的
result具有如下属性:
| 名称 | 类型 | 含义 |
|---|---|---|
detectedObjects |
array |
目标的位置、类别等信息。 |
image |
string | null |
目标检测结果图。图像为JPEG格式,使用Base64编码。 |
detectedObjects中的每个元素为一个object,具有如下属性:
| 名称 | 类型 | 含义 |
|---|---|---|
bbox |
array |
目标位置。数组中元素依次为边界框左上角x坐标、左上角y坐标、右下角x坐标以及右下角y坐标。 |
categoryId |
integer |
目标类别ID。 |
categoryName |
string |
目标类别名称。 |
score |
number |
目标得分。 |
result示例如下:
{
"detectedObjects": [
{
"bbox": [
404.4967956542969,
90.15770721435547,
506.2465515136719,
285.4187316894531
],
"categoryId": 0,
"categoryName": "oranage",
"score": 0.7418514490127563
},
{
"bbox": [
155.33145141601562,
81.10954284667969,
199.71136474609375,
167.4235382080078
],
"categoryId": 1,
"categoryName": "banana",
"score": 0.7328268885612488
}
],
"image": "xxxxxx"
}
多语言调用服务示例
Python
import base64
import requests
API_URL = "http://localhost:8080/object-detection" # 服务URL
image_path = "./demo.jpg"
output_image_path = "./out.jpg"
# 对本地图像进行Base64编码
with open(image_path, "rb") as file:
image_bytes = file.read()
image_data = base64.b64encode(image_bytes).decode("ascii")
payload = {"image": image_data} # Base64编码的文件内容或者图像URL
# 调用API
response = requests.post(API_URL, json=payload)
# 处理接口返回数据
assert response.status_code == 200
result = response.json()["result"]
with open(output_image_path, "wb") as file:
file.write(base64.b64decode(result["image"]))
print(f"Output image saved at {output_image_path}")
print("\nDetected objects:")
print(result["detectedObjects"])
C++
#include <iostream>
#include "cpp-httplib/httplib.h" // https://github.com/Huiyicc/cpp-httplib
#include "nlohmann/json.hpp" // https://github.com/nlohmann/json
#include "base64.hpp" // https://github.com/tobiaslocker/base64
int main() {
httplib::Client client("localhost:8080");
const std::string imagePath = "./demo.jpg";
const std::string outputImagePath = "./out.jpg";
httplib::Headers headers = {
{"Content-Type", "application/json"}
};
// 对本地图像进行Base64编码
std::ifstream file(imagePath, std::ios::binary | std::ios::ate);
std::streamsize size = file.tellg();
file.seekg(0, std::ios::beg);
std::vector<char> buffer(size);
if (!file.read(buffer.data(), size)) {
std::cerr << "Error reading file." << std::endl;
return 1;
}
std::string bufferStr(reinterpret_cast<const char*>(buffer.data()), buffer.size());
std::string encodedImage = base64::to_base64(bufferStr);
nlohmann::json jsonObj;
jsonObj["image"] = encodedImage;
std::string body = jsonObj.dump();
// 调用API
auto response = client.Post("/object-detection", headers, body, "application/json");
// 处理接口返回数据
if (response && response->status == 200) {
nlohmann::json jsonResponse = nlohmann::json::parse(response->body);
auto result = jsonResponse["result"];
encodedImage = result["image"];
std::string decodedString = base64::from_base64(encodedImage);
std::vector<unsigned char> decodedImage(decodedString.begin(), decodedString.end());
std::ofstream outputImage(outPutImagePath, std::ios::binary | std::ios::out);
if (outputImage.is_open()) {
outputImage.write(reinterpret_cast<char*>(decodedImage.data()), decodedImage.size());
outputImage.close();
std::cout << "Output image saved at " << outPutImagePath << std::endl;
} else {
std::cerr << "Unable to open file for writing: " << outPutImagePath << std::endl;
}
auto detectedObjects = result["detectedObjects"];
std::cout << "\nDetected objects:" << std::endl;
for (const auto& obj : detectedObjects) {
std::cout << obj << std::endl;
}
} else {
std::cout << "Failed to send HTTP request." << std::endl;
return 1;
}
return 0;
}
Java
import okhttp3.*;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.node.ObjectNode;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Base64;
public class Main {
public static void main(String[] args) throws IOException {
String API_URL = "http://localhost:8080/object-detection"; // 服务URL
String imagePath = "./demo.jpg"; // 本地图像
String outputImagePath = "./out.jpg"; // 输出图像
// 对本地图像进行Base64编码
File file = new File(imagePath);
byte[] fileContent = java.nio.file.Files.readAllBytes(file.toPath());
String imageData = Base64.getEncoder().encodeToString(fileContent);
ObjectMapper objectMapper = new ObjectMapper();
ObjectNode params = objectMapper.createObjectNode();
params.put("image", imageData); // Base64编码的文件内容或者图像URL
// 创建 OkHttpClient 实例
OkHttpClient client = new OkHttpClient();
MediaType JSON = MediaType.Companion.get("application/json; charset=utf-8");
RequestBody body = RequestBody.Companion.create(params.toString(), JSON);
Request request = new Request.Builder()
.url(API_URL)
.post(body)
.build();
// 调用API并处理接口返回数据
try (Response response = client.newCall(request).execute()) {
if (response.isSuccessful()) {
String responseBody = response.body().string();
JsonNode resultNode = objectMapper.readTree(responseBody);
JsonNode result = resultNode.get("result");
String base64Image = result.get("image").asText();
JsonNode detectedObjects = result.get("detectedObjects");
byte[] imageBytes = Base64.getDecoder().decode(base64Image);
try (FileOutputStream fos = new FileOutputStream(outputImagePath)) {
fos.write(imageBytes);
}
System.out.println("Output image saved at " + outputImagePath);
System.out.println("\nDetected objects: " + detectedObjects.toString());
} else {
System.err.println("Request failed with code: " + response.code());
}
}
}
}
Go
package main
import (
"bytes"
"encoding/base64"
"encoding/json"
"fmt"
"io/ioutil"
"net/http"
)
func main() {
API_URL := "http://localhost:8080/object-detection"
imagePath := "./demo.jpg"
outputImagePath := "./out.jpg"
// 对本地图像进行Base64编码
imageBytes, err := ioutil.ReadFile(imagePath)
if err != nil {
fmt.Println("Error reading image file:", err)
return
}
imageData := base64.StdEncoding.EncodeToString(imageBytes)
payload := map[string]string{"image": imageData} // Base64编码的文件内容或者图像URL
payloadBytes, err := json.Marshal(payload)
if err != nil {
fmt.Println("Error marshaling payload:", err)
return
}
// 调用API
client := &http.Client{}
req, err := http.NewRequest("POST", API_URL, bytes.NewBuffer(payloadBytes))
if err != nil {
fmt.Println("Error creating request:", err)
return
}
res, err := client.Do(req)
if err != nil {
fmt.Println("Error sending request:", err)
return
}
defer res.Body.Close()
// 处理接口返回数据
body, err := ioutil.ReadAll(res.Body)
if err != nil {
fmt.Println("Error reading response body:", err)
return
}
type Response struct {
Result struct {
Image string `json:"image"`
DetectedObjects []map[string]interface{} `json:"detectedObjects"`
} `json:"result"`
}
var respData Response
err = json.Unmarshal([]byte(string(body)), &respData)
if err != nil {
fmt.Println("Error unmarshaling response body:", err)
return
}
outputImageData, err := base64.StdEncoding.DecodeString(respData.Result.Image)
if err != nil {
fmt.Println("Error decoding base64 image data:", err)
return
}
err = ioutil.WriteFile(outputImagePath, outputImageData, 0644)
if err != nil {
fmt.Println("Error writing image to file:", err)
return
}
fmt.Printf("Image saved at %s.jpg\n", outputImagePath)
fmt.Println("\nDetected objects:")
for _, obj := range respData.Result.DetectedObjects {
fmt.Println(obj)
}
}
C#
using System;
using System.IO;
using System.Net.Http;
using System.Net.Http.Headers;
using System.Text;
using System.Threading.Tasks;
using Newtonsoft.Json.Linq;
class Program
{
static readonly string API_URL = "http://localhost:8080/object-detection";
static readonly string imagePath = "./demo.jpg";
static readonly string outputImagePath = "./out.jpg";
static async Task Main(string[] args)
{
var httpClient = new HttpClient();
// 对本地图像进行Base64编码
byte[] imageBytes = File.ReadAllBytes(imagePath);
string image_data = Convert.ToBase64String(imageBytes);
var payload = new JObject{ { "image", image_data } }; // Base64编码的文件内容或者图像URL
var content = new StringContent(payload.ToString(), Encoding.UTF8, "application/json");
// 调用API
HttpResponseMessage response = await httpClient.PostAsync(API_URL, content);
response.EnsureSuccessStatusCode();
// 处理接口返回数据
string responseBody = await response.Content.ReadAsStringAsync();
JObject jsonResponse = JObject.Parse(responseBody);
string base64Image = jsonResponse["result"]["image"].ToString();
byte[] outputImageBytes = Convert.FromBase64String(base64Image);
File.WriteAllBytes(outputImagePath, outputImageBytes);
Console.WriteLine($"Output image saved at {outputImagePath}");
Console.WriteLine("\nDetected objects:");
Console.WriteLine(jsonResponse["result"]["detectedObjects"].ToString());
}
}
Node.js
const axios = require('axios');
const fs = require('fs');
const API_URL = 'http://localhost:8080/object-detection'
const imagePath = './demo.jpg'
const outputImagePath = "./out.jpg";
let config = {
method: 'POST',
maxBodyLength: Infinity,
url: API_URL,
data: JSON.stringify({
'image': encodeImageToBase64(imagePath) // Base64编码的文件内容或者图像URL
})
};
// 对本地图像进行Base64编码
function encodeImageToBase64(filePath) {
const bitmap = fs.readFileSync(filePath);
return Buffer.from(bitmap).toString('base64');
}
// 调用API
axios.request(config)
.then((response) => {
// 处理接口返回数据
const result = response.data["result"];
const imageBuffer = Buffer.from(result["image"], 'base64');
fs.writeFile(outputImagePath, imageBuffer, (err) => {
if (err) throw err;
console.log(`Output image saved at ${outputImagePath}`);
});
console.log("\nDetected objects:");
console.log(result["detectedObjects"]);
})
.catch((error) => {
console.log(error);
});
PHP
<?php
$API_URL = "http://localhost:8080/object-detection"; // 服务URL
$image_path = "./demo.jpg";
$output_image_path = "./out.jpg";
// 对本地图像进行Base64编码
$image_data = base64_encode(file_get_contents($image_path));
$payload = array("image" => $image_data); // Base64编码的文件内容或者图像URL
// 调用API
$ch = curl_init($API_URL);
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_POSTFIELDS, json_encode($payload));
curl_setopt($ch, CURLOPT_HTTPHEADER, array('Content-Type: application/json'));
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$response = curl_exec($ch);
curl_close($ch);
// 处理接口返回数据
$result = json_decode($response, true)["result"];
file_put_contents($output_image_path, base64_decode($result["image"]));
echo "Output image saved at " . $output_image_path . "\n";
echo "\nDetected objects:\n";
print_r($result["detectedObjects"]);
?>
📱 端侧部署:端侧部署是一种将计算和数据处理功能放在用户设备本身上的方式,设备可以直接处理数据,而不需要依赖远程的服务器。PaddleX 支持将模型部署在 Android 等端侧设备上,详细的端侧部署流程请参考PaddleX端侧部署指南。 您可以根据需要选择合适的方式部署模型产线,进而进行后续的 AI 应用集成。
4. 二次开发¶
如果通用目标检测产线提供的默认模型权重在您的场景中,精度或速度不满意,您可以尝试利用您自己拥有的特定领域或应用场景的数据对现有模型进行进一步的微调,以提升通用目标检测产线的在您的场景中的识别效果。
4.1 模型微调¶
由于通用目标检测产线包含目标检测模块,如果模型产线的效果不及预期,那么您需要参考目标检测模块开发教程中的二次开发章节,使用您的私有数据集对目标检测模型进行微调。
4.2 模型应用¶
当您使用私有数据集完成微调训练后,可获得本地模型权重文件。
若您需要使用微调后的模型权重,只需对产线配置文件做修改,将微调后模型权重的本地路径替换至产线配置文件中的对应位置即可:
pipeline_name: object_detection
SubModules:
ObjectDetection:
module_name: object_detection
model_name: PicoDet-S
model_dir: null #可修改为微调后模型的本地路径
batch_size: 1
img_size: null
threshold: null
5. 多硬件支持¶
PaddleX 支持英伟达 GPU、昆仑芯 XPU、昇腾 NPU 和寒武纪 MLU 等多种主流硬件设备,仅需修改 --device 参数即可完成不同硬件之间的无缝切换。
例如,使用昇腾 NPU 进行目标检测产线快速推理:
paddlex --pipeline object_detection \
--input general_object_detection_002.png \
--threshold 0.5 \
--save_path ./output/ \
--device npu:0
当然,您也可以在 Python 脚本中 create_pipeline() 时或者 predict() 时指定硬件设备。
若您想在更多种类的硬件上使用通用目标检测产线,请参考PaddleX多硬件使用指南。