PaddleX 3.0 General Semantic Segmentation Pipeline — Lane Line Segmentation Tutorial¶
PaddleX offers a rich set of pipelines, each consisting of one or more models that can solve specific scenario tasks. All PaddleX pipelines support quick trials, and if the results do not meet expectations, fine-tuning the models with private data is also supported. PaddleX provides Python APIs for easy integration into personal projects. Before use, you need to install PaddleX. For installation instructions, refer to PaddleX Installation. This tutorial introduces the usage of the pipeline tool with an example of a lane line segmentation task.
1. Select a Pipeline¶
First, choose the corresponding PaddleX pipeline based on your task scenario. For lane line segmentation, this falls under the category of semantic segmentation tasks, corresponding to PaddleX's Universal Semantic Segmentation Pipeline. If you are unsure about the correspondence between tasks and pipelines, you can refer to the Pipeline List for an overview of pipeline capabilities.
2. Quick Start¶
PaddleX offers two ways to experience the pipeline: one is through the PaddleX wheel package locally, and the other is on the Baidu AIStudio Community.
-
Local Experience:
-
AIStudio Community Experience: Go to Baidu AIStudio Community, click "Create Pipeline", and create a Universal Semantic Segmentation pipeline for a quick trial.
Quick trial output example:

After experiencing the pipeline, determine if it meets your expectations (including accuracy, speed, etc.). If the model's speed or accuracy does not meet your requirements, you can select alternative models for further testing. If the final results are unsatisfactory, you may need to fine-tune the model. This tutorial aims to produce a model that segments lane lines, and the default weights (trained on the Cityscapes dataset) cannot meet this requirement. Therefore, you need to collect and annotate data for training and fine-tuning.
3. Choose a Model¶
PaddleX provides 18 end-to-end semantic segmentation models. For details, refer to the Model List. Some model benchmarks are as follows:
| Model List | mIoU (%) | GPU Inference Time (ms) | CPU Inference Time (ms) | Model Size (M) |
|---|---|---|---|---|
| OCRNet_HRNet-W48 | 82.15 | 87.97 | 2180.76 | 270 |
| PP-LiteSeg-T | 77.04 | 5.98 | 140.02 | 31 |
Note: The above accuracy metrics are measured on the Cityscapes dataset. GPU inference time is based on an NVIDIA Tesla T4 machine with FP32 precision. CPU inference speed is based on an Intel(R) Xeon(R) Gold 5117 CPU @ 2.00GHz with 8 threads and FP32 precision.
In short, models listed from top to bottom have faster inference speeds, while those from bottom to top have higher accuracy. This tutorial uses the PP-LiteSeg-T model as an example to complete the full model development process. You can choose a suitable model for training based on your actual usage scenario, evaluate the appropriate model weights within the pipeline, and finally use them in practical scenarios.
4. Data Preparation and Verification¶
4.1 Data Preparation¶
This tutorial uses the "Lane Line Segmentation Dataset" as an example dataset. You can obtain the example dataset using the following commands. If you use your own annotated dataset, you need to adjust it according to PaddleX's format requirements to meet PaddleX's data format specifications. For an introduction to data formats, you can refer to PaddleX Semantic Segmentation Task Module Data Annotation Tutorial.
Dataset acquisition commands:
cd /path/to/paddlex
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/data/semantic-segmentation-makassaridn-road-dataset.tar -P ./dataset
tar -xf ./dataset/semantic-segmentation-makassaridn-road-dataset.tar -C ./dataset/
4.2 Dataset Verification¶
To verify the dataset, simply use the following command:
python main.py -c paddlex/configs/semantic_segmentation/PP-LiteSeg-T.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/semantic-segmentation-makassaridn-road-dataset
After executing the above command, PaddleX will verify the dataset and collect basic information about it. Upon successful execution, the log will print "Check dataset passed !" information, and relevant outputs will be saved in the current directory's ./output/check_dataset directory, including visualized sample images and sample distribution histograms. The verification result file is saved in ./output/check_dataset_result.json, and the specific content of the verification result file is
{
"done_flag": true,
"check_pass": true,
"attributes": {
"num_classes": 4,
"train_samples": 300,
"train_sample_paths": [
"check_dataset/demo_img/20220311151733_0060_040.jpg",
"check_dataset/demo_img/20220311153115_0023_039.jpg"
],
"val_samples": 74,
"val_sample_paths": [
"check_dataset/demo_img/20220311152033_0060_007.jpg",
"check_dataset/demo_img/20220311144930_0060_026.jpg"
]
},
"analysis": {
"histogram": "check_dataset/histogram.png"
},
"dataset_path": "./dataset/semantic-segmentation-makassaridn-road-dataset",
"show_type": "image",
"dataset_type": "COCODetDataset"
}
In the verification results above, check_pass being True indicates that the dataset format meets the requirements. Explanations for other indicators are as follows:
attributes.num_classes: The number of classes in this dataset is 4, which is the number of classes that need to be passed for subsequent training;attributes.train_samples: The number of samples in the training set of this dataset is 300;attributes.val_samples: The number of samples in the validation set of this dataset is 74;attributes.train_sample_paths: A list of relative paths to the visualization images of samples in the training set of this dataset;attributes.val_sample_paths: A list of relative paths to the visualization images of samples in the validation set of this dataset;
Additionally, the dataset verification also analyzes the sample distribution across all classes and plots a histogram (histogram.png):
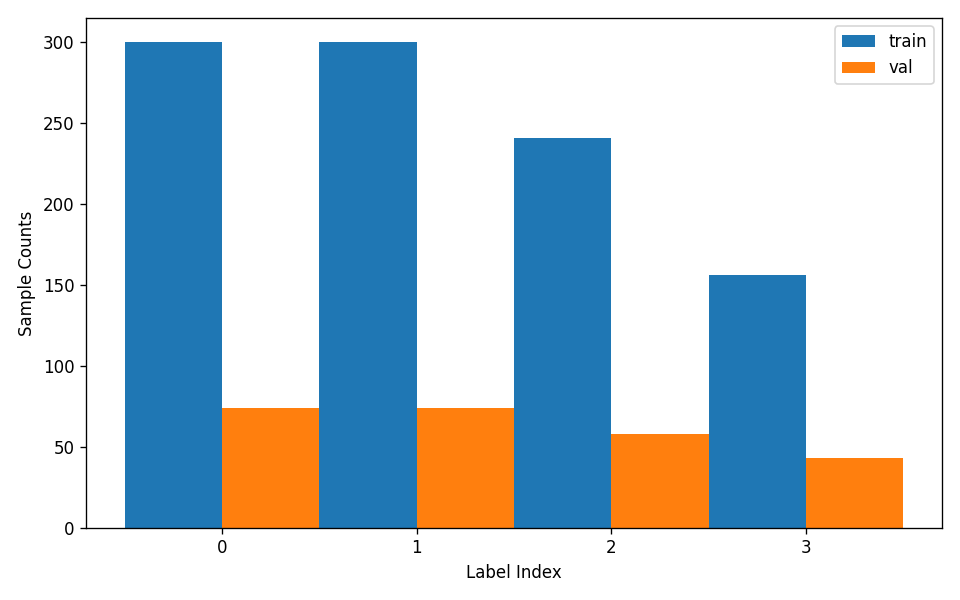
Note: Only data that passes verification can be used for training and evaluation.
4.3 Dataset Format Conversion / Dataset Splitting (Optional)¶
If you need to convert the dataset format or re-split the dataset, you can set it by modifying the configuration file or appending hyperparameters.
Parameters related to dataset verification can be set by modifying the fields under CheckDataset in the configuration file. Examples of some parameters in the configuration file are as follows:
CheckDataset:convert:enable: Whether to convert the dataset format. Set toTrueto enable dataset format conversion, default isFalse;src_dataset_type: If dataset format conversion is enabled, the source dataset format must be set. Available source formats areLabelMeandVOC;
split:enable: Whether to re-split the dataset. Set toTrueto enable dataset splitting, default isFalse;train_percent: If dataset splitting is enabled, the percentage of the training set must be set. The type is any integer between 0-100, and the sum withval_percentmust be 100;val_percent: If dataset splitting is enabled, the percentage of the validation set must be set. The type is any integer between 0-100, and the sum withtrain_percentmust be 100;
Data conversion and splitting can be enabled simultaneously. For data splitting, the original annotation files will be renamed to xxx.bak in their original paths. These parameters also support being set by appending command-line arguments, for example, to re-split the dataset and set the training and validation set ratios: -o CheckDataset.split.enable=True -o CheckDataset.split.train_percent=80 -o CheckDataset.split.val_percent=20.
5. Model Training and Evaluation¶
5.1 Model Training¶
Before training, ensure that you have validated your dataset. To complete the training of a PaddleX model, simply use the following command:
python main.py -c paddlex/configs/semantic_segmentation/PP-LiteSeg-T.yaml \
-o Global.mode=train \
-o Global.dataset_dir=./dataset/semantic-segmentation-makassaridn-road-dataset \
-o Train.num_classes=4
PaddleX supports modifying training hyperparameters, single/multi-GPU training, and more, simply by modifying the configuration file or appending command line arguments.
Each model in PaddleX provides a configuration file for model development, which is used to set relevant parameters. Model training-related parameters can be set by modifying the Train fields in the configuration file. Some example parameter descriptions in the configuration file are as follows:
Global:mode: Mode, supports dataset validation (check_dataset), model training (train), and model evaluation (evaluate);device: Training device, options includecpu,gpu,xpu,npu,mlu. For multi-GPU training, specify card numbers, e.g.,gpu:0,1,2,3;
Train: Training hyperparameter settings;epochs_iters: Number of training iterations;learning_rate: Training learning rate;
For more hyperparameter introductions, refer to PaddleX General Model Configuration File Parameter Explanation.
Note:
- The above parameters can be set by appending command line arguments, e.g., specifying the mode as model training: -o Global.mode=train; specifying the first two GPUs for training: -o Global.device=gpu:0,1; setting the number of training iterations to 5000: -o Train.epochs_iters=5000.
- During model training, PaddleX automatically saves model weight files, with the default being output. To specify a save path, use the -o Global.output field in the configuration file.
- PaddleX shields you from the concepts of dynamic graph weights and static graph weights. During model training, both dynamic and static graph weights are produced, and static graph weights are selected by default for model inference.
Training Outputs Explanation:
After completing model training, all outputs are saved in the specified output directory (default is ./output/), typically including the following:
- train_result.json: Training result record file, recording whether the training task completed normally, as well as the output weight metrics, relevant file paths, etc.;
- train.log: Training log file, recording changes in model metrics, loss, etc. during training;
- config.yaml: Training configuration file, recording the hyperparameter configuration for this training session;
- .pdparams, .pdema, .pdopt.pdstate, .pdiparams, .pdmodel: Model weight-related files, including network parameters, optimizer, EMA, static graph network parameters, static graph network structure, etc.;
5.2 Model Evaluation¶
After completing model training, you can evaluate the specified model weight file on the validation set to verify the model's accuracy. To evaluate a model using PaddleX, simply use the following command:
python main.py -c paddlex/configs/semantic_segmentation/PP-LiteSeg-T.yaml \
-o Global.mode=evaluate \
-o Global.dataset_dir=./dataset/semantic-segmentation-makassaridn-road-dataset
Similar to model training, model evaluation supports setting parameters by modifying the configuration file or appending command line arguments.
Note: When evaluating a model, you need to specify the model weight file path. Each configuration file has a default weight save path. If you need to change it, simply set it by appending a command line argument, e.g., -o Evaluate.weight_path=./output/best_model/model.pdparams.
5.3 Model Optimization¶
After learning about model training and evaluation, we can enhance model accuracy by adjusting hyperparameters. By carefully tuning the number of training epochs, you can control the depth of model training, avoiding overfitting or underfitting. Meanwhile, the setting of the learning rate is crucial to the speed and stability of model convergence. Therefore, when optimizing model performance, it is essential to consider the values of these two parameters prudently and adjust them flexibly based on actual conditions to achieve the best training results.
It is recommended to follow the method of controlled variables when debugging parameters:
- First, fix the number of training iterations at 5000 and the batch size at 2.
- Initiate three experiments based on the PP-LiteSeg-T model, with learning rates of: 0.006, 0.008, and 0.01.
- It can be observed that the configuration with the highest accuracy in Experiment 2 is a learning rate of 0.008. Based on this training hyperparameter, change the number of training epochs and observe the accuracy results of different iterations, finding that the optimal accuracy is basically achieved at 80000 iterations.
Learning Rate Exploration Results:
| Experiment | Iterations | Learning Rate | batch_size | Training Environment | mIoU |
|---|---|---|---|---|---|
| Experiment 1 | 5000 | 0.006 | 2 | 4 GPUs | 0.623 |
| Experiment 2 | 5000 | 0.008 | 2 | 4 GPUs | 0.629 |
| Experiment 3 | 5000 | 0.01 | 2 | 4 GPUs | 0.619 |
Changing Epoch Results:
| Experiment | Iterations | Learning Rate | batch_size | Training Environment | mIoU |
|---|---|---|---|---|---|
| Experiment 2 | 5000 | 0.008 | 2 | 4 GPUs | 0.629 |
| Experiment 2 with fewer epochs | 10000 | 0.008 | 2 | 4 GPUs | 0.773 |
| Experiment 2 with more epochs | 40000 | 0.008 | 2 | 4 GPUs | 0.855 |
| Experiment 2 with more epochs | 80000 | 0.008 | 2 | 4 GPUs | 0.863 |
Note: This tutorial is designed for 4 GPUs. If you have only 1 GPU, you can adjust the number of training GPUs to complete the experiment, but the final metrics may not align with the above indicators, which is normal.
6. Production Line Testing¶
Replace the model in the production line with the fine-tuned model for testing, for example:
python main.py -c paddlex/configs/semantic_segmentation/PP-LiteSeg-T.yaml \
-o Global.mode=predict \
-o Predict.model_dir="output/best_model/inference" \
-o Predict.input="https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/application/semantic_segmentation/makassaridn-road_demo.png"
The prediction results will be generated under ./output, where the prediction result for makassaridn-road_demo.png is shown below:

7. Development Integration/Deployment¶
If the general semantic segmentation pipeline meets your requirements for inference speed and accuracy in the production line, you can proceed directly with development integration/deployment.
1. Directly apply the trained model in your Python project by referring to the following sample code, and modify the Pipeline.model in the paddlex/pipelines/semantic_segmentation.yaml configuration file to your own model path:
from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="paddlex/pipelines/semantic_segmentation.yaml")
output = pipeline.predict("https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/application/semantic_segmentation/makassaridn-road_demo.png")
for res in output:
res.print() # Print the structured output of the prediction
res.save_to_img("./output/") # Save the visualized image of the result
res.save_to_json("./output/") # Save the structured output of the prediction
-
Additionally, PaddleX offers three other deployment methods, detailed as follows:
-
high-performance inference: In actual production environments, many applications have stringent standards for deployment strategy performance metrics (especially response speed) to ensure efficient system operation and smooth user experience. To this end, PaddleX provides high-performance inference plugins aimed at deeply optimizing model inference and pre/post-processing for significant end-to-end process acceleration. For detailed high-performance inference procedures, please refer to the PaddleX High-Performance Inference Guide.
- Service-Oriented Deployment: Service-oriented deployment is a common deployment form in actual production environments. By encapsulating inference functions as services, clients can access these services through network requests to obtain inference results. PaddleX supports users in achieving cost-effective service-oriented deployment of production lines. For detailed service-oriented deployment procedures, please refer to the PaddleX Service-Oriented Deployment Guide.
- Edge Deployment: Edge deployment is a method that places computing and data processing capabilities directly on user devices, allowing devices to process data without relying on remote servers. PaddleX supports deploying models on edge devices such as Android. For detailed edge deployment procedures, please refer to the PaddleX Edge Deployment Guide.
You can select the appropriate deployment method for your model pipeline according to your needs, and proceed with subsequent AI application integration.