OCR datasets¶
Here is a list of public datasets commonly used in OCR, which are being continuously updated. Welcome to contribute datasets!
1. Text detection¶
1.1 PaddleOCR text detection format annotation¶
The annotation file formats supported by the PaddleOCR text detection algorithm are as follows, separated by "\t":
The image annotation after json.dumps() encoding is a list containing multiple dictionaries.
The points in the dictionary represent the coordinates (x, y) of the four points of the text box, arranged clockwise from the point at the upper left corner.
transcription represents the text of the current text box. When its content is "###" it means that the text box is invalid and will be skipped during training.
If you want to train PaddleOCR on other datasets, please build the annotation file according to the above format.
1.2 Public dataset¶
| dataset | Image download link | PaddleOCR format annotation download link |
|---|---|---|
| ICDAR 2015 | https://rrc.cvc.uab.es/?ch=4&com=downloads | train / test |
| ctw1500 | https://paddleocr.bj.bcebos.com/dataset/ctw1500.zip | Included in the downloaded image zip |
| total text | https://paddleocr.bj.bcebos.com/dataset/total_text.tar | Included in the downloaded image zip |
1.2.1 ICDAR 2015¶
The icdar2015 dataset contains train set which has 1000 images obtained with wearable cameras and test set which has 500 images obtained with wearable cameras. The icdar2015 dataset can be downloaded from the link in the table above. Registration is required for downloading.
After registering and logging in, download the part marked in the red box in the figure below. And, the content downloaded by Training Set Images should be saved as the folder icdar_c4_train_imgs, and the content downloaded by Test Set Images is saved as the folder ch4_test_images
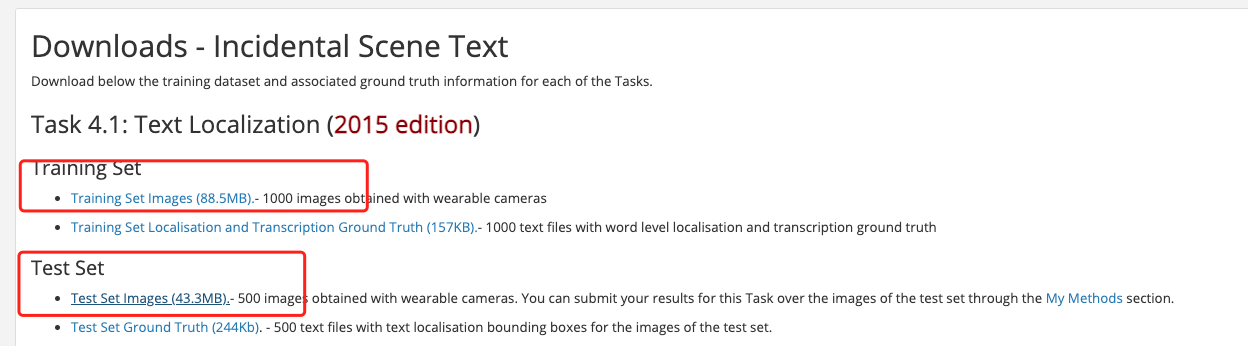
Decompress the downloaded dataset to the working directory, assuming it is decompressed under PaddleOCR/train_data/. Then download the PaddleOCR format annotation file from the table above.
PaddleOCR also provides a data format conversion script, which can convert the official website label to the PaddleOCR format. The data conversion tool is in ppocr/utils/gen_label.py, here is the training set as an example:
After decompressing the data set and downloading the annotation file, PaddleOCR/train_data/ has two folders and two files, which are:
2. Text recognition¶
2.1 PaddleOCR text recognition format annotation¶
The text recognition algorithm in PaddleOCR supports two data formats:
lmdbis used to train data sets stored in lmdb format, use lmdb_dataset.py to load;common datasetis used to train data sets stored in text files, use simple_dataset.py to load.
If you want to use your own data for training, please refer to the following to organize your data.
Training set¶
It is recommended to put the training images in the same folder, and use a txt file (rec_gt_train.txt) to store the image path and label. The contents of the txt file are as follows:
- Note: by default, the image path and image label are split with \t, if you use other methods to split, it will cause training error
The final training set should have the following file structure:
Test set¶
Similar to the training set, the test set also needs to be provided a folder containing all images (test) and a rec_gt_test.txt. The structure of the test set is as follows:
2.2 Public dataset¶
| dataset | Image download link | PaddleOCR format annotation download link |
|---|---|---|
| en benchmark(MJ, SJ, IIIT, SVT, IC03, IC13, IC15, SVTP, and CUTE.) | DTRB | LMDB format, which can be loaded directly with lmdb_dataset.py |
| ICDAR 2015 | http://rrc.cvc.uab.es/?ch=4&com=downloads | train/ test |
| Multilingual datasets | Baidu network disk Extraction code: frgi google drive |
Included in the downloaded image zip |
2.1 ICDAR 2015¶
The ICDAR 2015 dataset can be downloaded from the link in the table above for quick validation. The lmdb format dataset required by en benchmark can also be downloaded from the table above.
Then download the PaddleOCR format annotation file from the table above.
PaddleOCR also provides a data format conversion script, which can convert the ICDAR official website label to the data format supported by PaddleOCR. The data conversion tool is in ppocr/utils/gen_label.py, here is the training set as an example:
The data format is as follows, (a) is the original picture, (b) is the Ground Truth text file corresponding to each picture:

3. Data storage path¶
The default storage path for PaddleOCR training data is PaddleOCR/train_data, if you already have a dataset on your disk, just create a soft link to the dataset directory: