Introduction to PP-OCRv5¶
PP-OCRv5 is the new generation text recognition solution of PP-OCR, focusing on multi-scenario and multi-text type recognition. In terms of text types, PP-OCRv5 supports 5 major mainstream text types: Simplified Chinese, Chinese Pinyin, Traditional Chinese, English, and Japanese. For scenarios, PP-OCRv5 has upgraded recognition capabilities for challenging scenarios such as complex Chinese and English handwriting, vertical text, and uncommon characters. On internal complex evaluation sets across multiple scenarios, PP-OCRv5 achieved a 13 percentage point end-to-end improvement over PP-OCRv4.
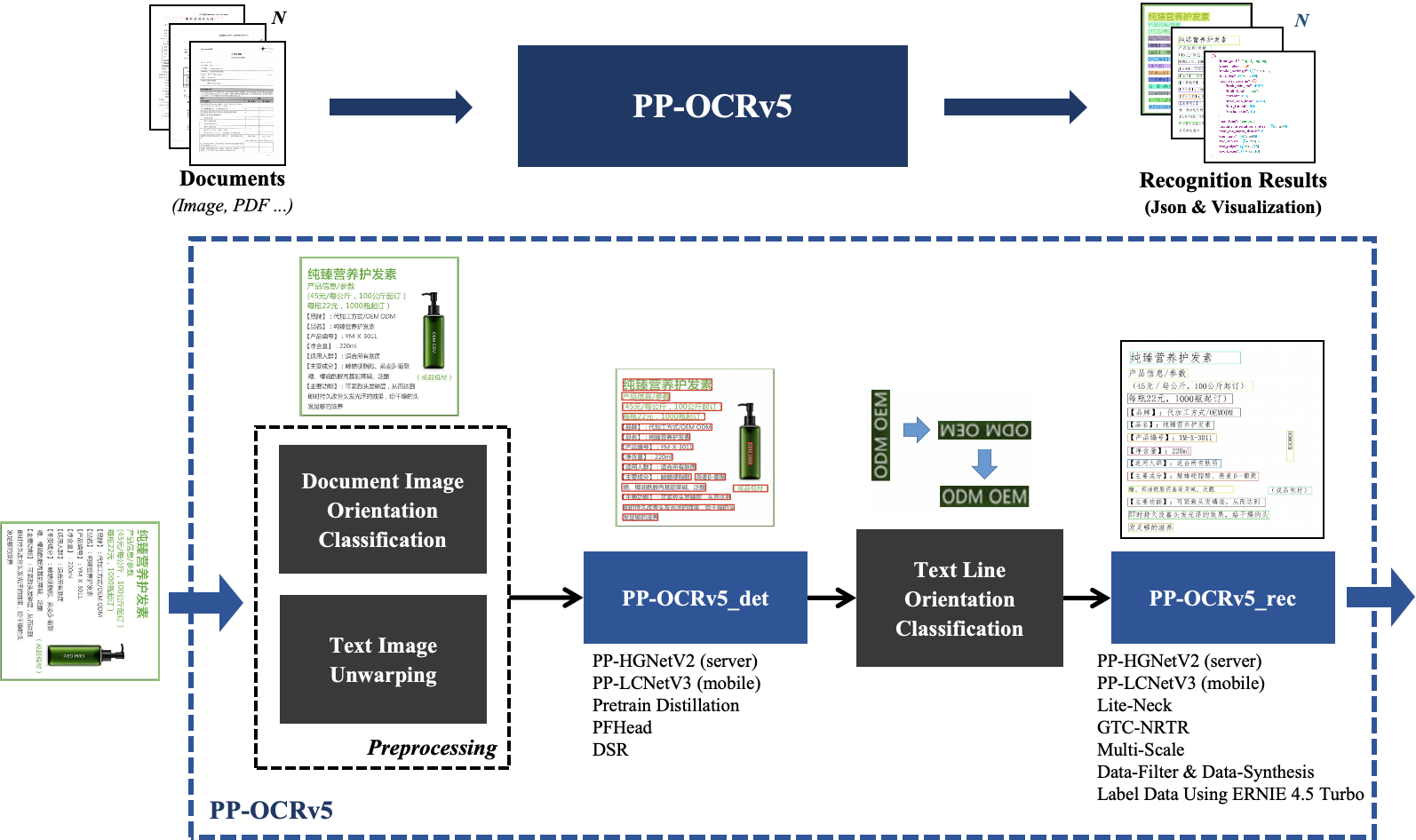
Key Metrics¶
1. Text Detection Metrics¶
| Model | Handwritten Chinese | Handwritten English | Printed Chinese | Printed English | Traditional Chinese | Ancient Text | Japanese | General Scenario | Pinyin | Rotation | Distortion | Artistic Text | Average |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PP-OCRv5_server_det | 0.803 | 0.841 | 0.945 | 0.917 | 0.815 | 0.676 | 0.772 | 0.797 | 0.671 | 0.8 | 0.876 | 0.673 | 0.827 |
| PP-OCRv4_server_det | 0.706 | 0.249 | 0.888 | 0.690 | 0.759 | 0.473 | 0.685 | 0.715 | 0.542 | 0.366 | 0.775 | 0.583 | 0.662 |
| PP-OCRv5_mobile_det | 0.744 | 0.777 | 0.905 | 0.910 | 0.823 | 0.581 | 0.727 | 0.721 | 0.575 | 0.647 | 0.827 | 0.525 | 0.770 |
| PP-OCRv4_mobile_det | 0.583 | 0.369 | 0.872 | 0.773 | 0.663 | 0.231 | 0.634 | 0.710 | 0.430 | 0.299 | 0.715 | 0.549 | 0.624 |
Compared to PP-OCRv4, PP-OCRv5 shows significant improvement in all detection scenarios, especially in handwriting, ancient texts, and Japanese detection capabilities.
2. Text Recognition Metrics¶
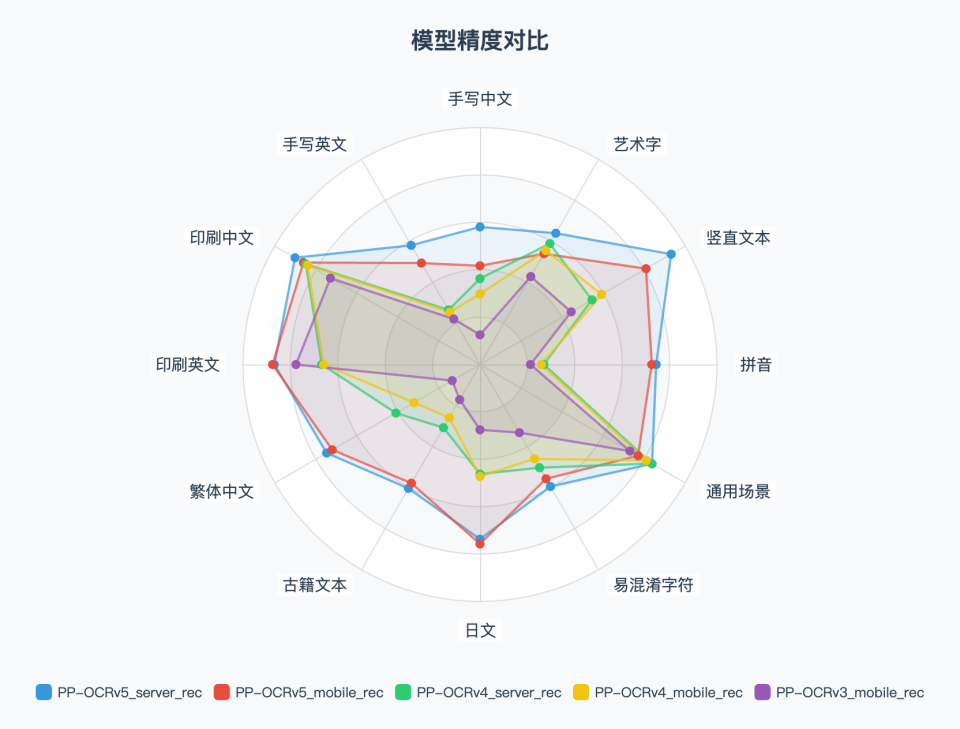
| Evaluation Set Category | Handwritten Chinese | Handwritten English | Printed Chinese | Printed English | Traditional Chinese | Ancient Text | Japanese | Confusable Characters | General Scenario | Pinyin | Vertical Text | Artistic Text | Weighted Average |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PP-OCRv5_server_rec | 0.5807 | 0.5806 | 0.9013 | 0.8679 | 0.7472 | 0.6039 | 0.7372 | 0.5946 | 0.8384 | 0.7435 | 0.9314 | 0.6397 | 0.8401 |
| PP-OCRv4_server_rec | 0.3626 | 0.2661 | 0.8486 | 0.6677 | 0.4097 | 0.3080 | 0.4623 | 0.5028 | 0.8362 | 0.2694 | 0.5455 | 0.5892 | 0.5735 |
| PP-OCRv5_mobile_rec | 0.4166 | 0.4944 | 0.8605 | 0.8753 | 0.7199 | 0.5786 | 0.7577 | 0.5570 | 0.7703 | 0.7248 | 0.8089 | 0.5398 | 0.8015 |
| PP-OCRv4_mobile_rec | 0.2980 | 0.2550 | 0.8398 | 0.6598 | 0.3218 | 0.2593 | 0.4724 | 0.4599 | 0.8106 | 0.2593 | 0.5924 | 0.5555 | 0.5301 |
A single model can cover multiple languages and text types, with recognition accuracy significantly ahead of previous generation products and mainstream open-source solutions.
PP-OCRv5 Demo Examples¶

Reference Data for Inference Performance¶
Test Environment:
- NVIDIA Tesla V100
- Intel Xeon Gold 6271C
- PaddlePaddle 3.0.0
Tested on 200 images (including both general and document images). During testing, images are read from disk, so the image reading time and other associated overhead are also included in the total time consumption. If the images are preloaded into memory, the average time per image can be further reduced by approximately 25 ms.
Unless otherwise specified:
- PP-OCRv4_mobile_det and PP-OCRv4_mobile_rec models are used.
- Document orientation classification, image correction, and text line orientation classification are not used.
text_det_limit_typeis set to"min"andtext_det_limit_side_lento736.
1. Comparison of Inference Performance Between PP-OCRv5 and PP-OCRv4¶
| Config | Description |
|---|---|
| v5_mobile | Uses PP-OCRv5_mobile_det and PP-OCRv5_mobile_rec models. |
| v4_mobile | Uses PP-OCRv4_mobile_det and PP-OCRv4_mobile_rec models. |
| v5_server | Uses PP-OCRv5_server_det and PP-OCRv5_server_rec models. |
| v4_server | Uses PP-OCRv4_server_det and PP-OCRv4_server_rec models. |
GPU
| Configuration | Avg. Time per Image (s) | Avg. Characters Predicted per Second | Avg. CPU Utilization (%) | Peak RAM Usage (MB) | Avg. RAM Usage (MB) | Avg. GPU Utilization (%) | Peak VRAM Usage (MB) | Avg. VRAM Usage (MB) |
|---|---|---|---|---|---|---|---|---|
| v5_mobile | 0.62 | 1054.23 | 106.35 | 1829.36 | 1521.92 | 17.42 | 4190.00 | 3114.02 |
| v4_mobile | 0.29 | 2062.53 | 112.21 | 1713.10 | 1456.14 | 26.53 | 1304.00 | 1166.68 |
| v5_server | 0.74 | 878.84 | 105.68 | 1899.80 | 1569.46 | 34.39 | 5402.00 | 4683.93 |
| v4_server | 0.47 | 1322.06 | 108.06 | 1773.10 | 1518.94 | 55.25 | 6760.67 | 5788.02 |
CPU
| Configuration | Avg. Time per Image (s) | Avg. Characters Predicted per Second | Avg. CPU Utilization (%) | Peak RAM Usage (MB) | Avg. RAM Usage (MB) |
|---|---|---|---|---|---|
| v5_mobile | 1.75 | 371.82 | 965.89 | 2219.98 | 1830.97 |
| v4_mobile | 1.37 | 444.27 | 1007.33 | 2090.53 | 1797.76 |
| v5_server | 4.34 | 149.98 | 990.24 | 4020.85 | 3137.20 |
| v4_server | 5.42 | 115.20 | 999.03 | 4018.35 | 3105.29 |
Note: PP-OCRv5 uses a larger dictionary in the recognition model, which increases inference time and causes slower performance compared to PP-OCRv4.
2. Impact of Auxiliary Features on PP-OCRv5 Inference Performance¶
| Config | Description |
|---|---|
| base | No document orientation classification, no image correction, no text line orientation classification. |
| with_textline | Includes text line orientation classification only. |
| with_all | Includes document orientation classification, image correction, and text line orientation classification. |
GPU
| Configuration | Avg. Time per Image (s) | Avg. Characters Predicted per Second | Avg. CPU Utilization (%) | Peak RAM Usage (MB) | Avg. RAM Usage (MB) | Avg. GPU Utilization (%) | Peak VRAM Usage (MB) | Avg. VRAM Usage (MB) |
|---|---|---|---|---|---|---|---|---|
| base | 0.62 | 1054.23 | 106.35 | 1829.36 | 1521.92 | 17.42 | 4190.00 | 3114.02 |
| with_textline | 0.64 | 1012.32 | 106.37 | 1867.69 | 1527.42 | 19.16 | 4198.00 | 3115.05 |
| with_all | 1.09 | 562.99 | 105.67 | 2381.53 | 1792.48 | 10.77 | 2480.00 | 2065.54 |
CPU
| Configuration | Avg. Time per Image (s) | Avg. Characters Predicted per Second | Avg. CPU Utilization (%) | Peak RAM Usage (MB) | Avg. RAM Usage (MB) |
|---|---|---|---|---|---|
| base | 1.75 | 371.82 | 965.89 | 2219.98 | 1830.97 |
| with_textline | 1.87 | 347.61 | 972.08 | 2232.38 | 1822.13 |
| with_all | 3.13 | 195.25 | 828.37 | 2751.47 | 2179.70 |
Note: Auxiliary features such as image unwarping can impact inference accuracy. More features do not necessarily yield better results and may increase resource usage.
3. Impact of Input Scaling Strategy in Text Detection Module on PP-OCRv5 Inference Performance¶
| Config | Description |
|---|---|
| mobile_min_1280 | Uses min limit type and text_det_limit_side_len=1280 with PP-OCRv5_mobile models. |
| mobile_min_736 | Same as default, min, side_len=736. |
| mobile_max_960 | Uses max limit type and side_len=960. |
| mobile_max_640 | Uses max limit type and side_len=640. |
| server_min_1280 | Uses min, side_len=1280 with PP-OCRv5_server models. |
| server_min_736 | Same as default, min, side_len=736. |
| server_max_960 | Uses max, side_len=960. |
| server_max_640 | Uses max, side_len=640. |
GPU
| Configuration | Avg. Time per Image (s) | Avg. Characters Predicted per Second | Avg. CPU Utilization (%) | Peak RAM Usage (MB) | Avg. RAM Usage (MB) | Avg. GPU Utilization (%) | Peak VRAM Usage (MB) | Avg. VRAM Usage (MB) |
|---|---|---|---|---|---|---|---|---|
| mobile_min_1280 | 0.66 | 985.77 | 109.52 | 1878.74 | 1536.43 | 18.01 | 4050.00 | 3407.33 |
| mobile_min_736 | 0.62 | 1054.23 | 106.35 | 1829.36 | 1521.92 | 17.42 | 4190.00 | 3114.02 |
| mobile_max_960 | 0.52 | 1206.68 | 104.01 | 1795.27 | 1484.73 | 18.66 | 2490.00 | 2173.91 |
| mobile_max_640 | 0.45 | 1353.49 | 103.32 | 1728.91 | 1470.64 | 18.55 | 2378.00 | 1998.62 |
| server_min_1280 | 0.86 | 759.10 | 107.81 | 1876.31 | 1572.20 | 37.33 | 10368.00 | 8287.41 |
| server_min_736 | 0.74 | 878.84 | 105.68 | 1899.80 | 1569.46 | 34.39 | 5402.00 | 4683.93 |
| server_max_960 | 0.64 | 988.85 | 103.61 | 1831.31 | 1544.26 | 30.29 | 2929.33 | 2079.90 |
| server_max_640 | 0.57 | 1036.90 | 102.89 | 1838.36 | 1532.50 | 28.91 | 3153.33 | 2743.40 |
CPU
| Configuration | Avg. Time per Image (s) | Avg. Characters Predicted per Second | Avg. CPU Utilization (%) | Peak RAM Usage (MB) | Avg. RAM Usage (MB) |
|---|---|---|---|---|---|
| mobile_min_1280 | 2.00 | 326.44 | 976.83 | 2233.16 | 1867.94 |
| mobile_min_736 | 1.75 | 371.82 | 965.89 | 2219.98 | 1830.97 |
| mobile_max_960 | 1.49 | 422.62 | 969.11 | 2048.67 | 1677.82 |
| mobile_max_640 | 1.31 | 459.11 | 978.41 | 2023.25 | 1616.42 |
| server_min_1280 | 5.57 | 117.08 | 991.34 | 4452.39 | 3286.19 |
| server_min_736 | 4.34 | 149.98 | 990.24 | 4020.85 | 3137.20 |
| server_max_960 | 3.39 | 186.59 | 984.67 | 3492.62 | 2977.13 |
| server_max_640 | 2.95 | 201.00 | 980.59 | 3342.38 | 2935.24 |
Deployment and Secondary Development¶
- Multiple System Support: Compatible with mainstream operating systems including Windows, Linux, and Mac.
- Multiple Hardware Support: Besides NVIDIA GPUs, it also supports inference and deployment on Intel CPU, Kunlun chips, Ascend, and other new hardware.
- High-Performance Inference Plugin: Recommended to combine with high-performance inference plugins to further improve inference speed. See High-Performance Inference Guide for details.
- Service Deployment: Supports highly stable service deployment solutions. See Service Deployment Guide for details.
- Secondary Development Capability: Supports custom dataset training, dictionary extension, and model fine-tuning. Example: To add Korean recognition, you can extend the dictionary and fine-tune the model, seamlessly integrating into existing pipelines. See Text Detection Module Usage Tutorial and Text Recognition Module Usage Tutorial for details.