Formula Recognition Module Tutorial¶
I. Overview¶
The formula recognition module is a key component of an OCR (Optical Character Recognition) system, responsible for converting mathematical formulas in images into editable text or computer-readable formats. The performance of this module directly affects the accuracy and efficiency of the entire OCR system. The formula recognition module typically outputs LaTeX or MathML code of the mathematical formulas, which will be passed as input to the text understanding module for further processing.
II. Supported Model List¶
| Model | Model Download Link | En-BLEU(%) | Zh-BLEU(%) | GPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
CPU Inference Time (ms) [Normal Mode / High-Performance Mode] |
Model Storage Size (MB) | Introduction |
|---|---|---|---|---|---|---|---|
| UniMERNet | Inference Model/Training Model | 85.91 | 43.50 | 1311.84 / 1311.84 | - / 8288.07 | 1530 | UniMERNet is a formula recognition model developed by Shanghai AI Lab. It uses Donut Swin as the encoder and MBartDecoder as the decoder. The model is trained on a dataset of one million samples, including simple formulas, complex formulas, scanned formulas, and handwritten formulas, significantly improving the recognition accuracy of real-world formulas. | PP-FormulaNet-S | Inference Model/Training Model | 87.00 | 45.71 | 182.25 / 182.25 | - / 254.39 | 224 | PP-FormulaNet is an advanced formula recognition model developed by the Baidu PaddlePaddle Vision Team. The PP-FormulaNet-S version uses PP-HGNetV2-B4 as its backbone network. Through parallel masking and model distillation techniques, it significantly improves inference speed while maintaining high recognition accuracy, making it suitable for applications requiring fast inference. The PP-FormulaNet-L version, on the other hand, uses Vary_VIT_B as its backbone network and is trained on a large-scale formula dataset, showing significant improvements in recognizing complex formulas compared to PP-FormulaNet-S. | PP-FormulaNet-L | Inference Model/Training Model | 90.36 | 45.78 | 1482.03 / 1482.03 | - / 3131.54 | 695 | PP-FormulaNet_plus-S | Inference Model/Training Model | 88.71 | 53.32 | 179.20 / 179.20 | - / 260.99 | 248 | PP-FormulaNet_plus is an enhanced version of the formula recognition model developed by the Baidu PaddlePaddle Vision Team, building upon the original PP-FormulaNet. Compared to the original version, PP-FormulaNet_plus utilizes a more diverse formula dataset during training, including sources such as Chinese dissertations, professional books, textbooks, exam papers, and mathematics journals. This expansion significantly improves the model’s recognition capabilities. Among the models, PP-FormulaNet_plus-M and PP-FormulaNet_plus-L have added support for Chinese formulas and increased the maximum number of predicted tokens for formulas from 1,024 to 2,560, greatly enhancing the recognition performance for complex formulas. Meanwhile, the PP-FormulaNet_plus-S model focuses on improving the recognition of English formulas. With these improvements, the PP-FormulaNet_plus series models perform exceptionally well in handling complex and diverse formula recognition tasks. |
| PP-FormulaNet_plus-M | Inference Model/Training Model | 91.45 | 89.76 | 1040.27 / 1040.27 | - / 1615.80 | 592 | |
| PP-FormulaNet_plus-L | Inference Model/Training Model | 92.22 | 90.64 | 1476.07 / 1476.07 | - / 3125.58 | 698 | |
| LaTeX_OCR_rec | Inference Model/Training Model | 74.55 | 39.96 | 1088.89 / 1088.89 | - / - | 99 | LaTeX-OCR is a formula recognition algorithm based on an autoregressive large model. It uses Hybrid ViT as the backbone network and a transformer as the decoder, significantly improving the accuracy of formula recognition. |
Test Environment Description:
- Performance Test Environment
- Test Dataset: PaddleOCR internal custom formula recognition test set
- Hardware Configuration:
- GPU: NVIDIA Tesla T4
- CPU: Intel Xeon Gold 6271C @ 2.60GHz
- Software Environment:
- Ubuntu 20.04 / CUDA 11.8 / cuDNN 8.9 / TensorRT 8.6.1.6
- paddlepaddle 3.0.0 / paddleocr 3.0.3
- Inference Mode Description
| Mode | GPU Configuration | CPU Configuration | Acceleration Technique Combination |
|---|---|---|---|
| Standard Mode | FP32 precision / No TRT acceleration | FP32 precision / 8 threads | PaddleInference |
| High-Performance Mode | Optimal combination of predefined precision type and acceleration strategy | FP32 precision / 8 threads | Optimal predefined backend (Paddle/OpenVINO/TRT, etc.) |
III. Quick Start¶
❗ Before getting started, please install the PaddleOCR wheel package. For details, refer to the Installation Guide.
You can quickly try it out with a single command:
paddleocr formula_recognition -i https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_formula_rec_001.png
Note: The official models would be download from HuggingFace by default. If can't access to HuggingFace, please set the environment variable PADDLE_PDX_MODEL_SOURCE="BOS" to change the model source to BOS. In the future, more model sources will be supported.
You can also integrate the model inference from the formula recognition module into your own project.Before running the code below, please download the example image locally.
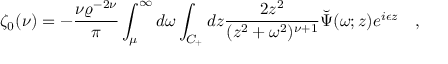{kind=link}
from paddleocr import FormulaRecognition
model = FormulaRecognition(model_name="PP-FormulaNet_plus-M")
output = model.predict(input="general_formula_rec_001.png", batch_size=1)
for res in output:
res.print()
res.save_to_img(save_path="./output/")
res.save_to_json(save_path="./output/res.json")
{'res': {'input_path': '/root/.paddlex/predict_input/general_formula_rec_001.png', 'page_index': None, 'rec_formula': '\\zeta_{0}(\\nu)=-\\frac{\\nu\\varrho^{-2\\nu}}{\\pi}\\int_{\\mu}^{\\infty}d\\omega\\int_{C_{+}}d z\\frac{2z^{2}}{(z^{2}+\\omega^{2})^{\\nu+1}}\\breve{\\Psi}(\\omega;z)e^{i\\epsilon z}\\quad,'}}
input_path: Indicates the path to the input formula image to be predictedpage_index: If the input is a PDF file, this represents the page number; otherwise, it is Nonerec_formula:Indicates the predicted LaTeX source code of the formula image The visualization image is as follows. The left side is the input formula image, and the right side is the rendered formula from the prediction:

Note: If you need to visualize the formula recognition module, you must install the LaTeX rendering environment by running the following command. Currently, visualization is only supported on Ubuntu. Other environments are not supported for now. For complex formulas, the LaTeX result may contain advanced representations that may not render successfully in Markdown or similar environments:
sudo apt-get update
sudo apt-get install texlive texlive-latex-base texlive-xetex latex-cjk-all texlive-latex-extra -y
Related methods and parameter descriptions are as follows:
FormulaRecognitioninstantiates the formula recognition model (here usingPP-FormulaNet_plus-Mas an example), with detailed description as follows:
| Parameter | Description | Type | Default |
|---|---|---|---|
model_name |
Model name. If set to None, PP-FormulaNet_plus-M will be used. |
str|None |
None |
model_dir |
Model storage path. | str|None |
None |
device |
Device for inference. For example: "cpu", "gpu", "npu", "gpu:0", "gpu:0,1".If multiple devices are specified, parallel inference will be performed. By default, GPU 0 is used if available; otherwise, CPU is used. |
str|None |
None |
enable_hpi |
Whether to enable high-performance inference. | bool |
False |
use_tensorrt |
Whether to use the Paddle Inference TensorRT subgraph engine. If the model does not support acceleration through TensorRT, setting this flag will not enable acceleration. For Paddle with CUDA version 11.8, the compatible TensorRT version is 8.x (x>=6), and it is recommended to install TensorRT 8.6.1.6. For Paddle with CUDA version 12.6, the compatible TensorRT version is 10.x (x>=5), and it is recommended to install TensorRT 10.5.0.18. |
bool |
False |
precision |
Computation precision when using the TensorRT subgraph engine in Paddle Inference. Options: "fp32", "fp16". |
str |
"fp32" |
enable_mkldnn |
Whether to enable MKL-DNN acceleration for inference. If MKL-DNN is unavailable or the model does not support it, acceleration will not be used even if this flag is set. | bool |
True |
mkldnn_cache_capacity |
MKL-DNN cache capacity. | int |
10 |
cpu_threads |
Number of threads to use for inference on CPUs. | int |
10 |
- Call the
predict()method of the formula recognition model to perform inference, which returns a result list.
Additionally, this module provides thepredict_iter()method. Both accept the same parameters and return the same result format.
The difference is thatpredict_iter()returns agenerator, which can process and retrieve results step-by-step, suitable for large datasets or memory-efficient scenarios.
You can choose either method based on your actual needs. The predict() method takes parameters input and batch_size, described as follows:
| Parameter | Description | Type | Default |
|---|---|---|---|
input |
Input data to be predicted. Required. Supports multiple input types:
|
Python Var|str|list |
|
batch_size |
Batch size, positive integer. | int |
1 |
{kind=link}
- The prediction results can be processed. Each result corresponds to a
Resultobject, which supports printing, saving as an image, and saving as ajsonfile:
| Method | Description | Parameter | Type | Details | Default |
|---|---|---|---|---|---|
print() |
Print the result to the terminal | format_json |
bool |
Whether to format the output using JSON indentation |
True |
indent |
int |
Specify the indentation level to beautify the JSON output; only effective when format_json is True |
4 | ||
ensure_ascii |
bool |
Controls whether non-ASCII characters are escaped to Unicode. If set to True, all non-ASCII characters are escaped; if False, original characters are kept. Only effective when format_json is True |
False |
||
save_to_json() |
Save the result as a json-formatted file | save_path |
str |
Path to save the file. If it is a directory, the saved file name will match the input file type | None |
indent |
int |
Specify the indentation level to beautify the JSON output; only effective when format_json is True |
4 | ||
ensure_ascii |
bool |
Controls whether non-ASCII characters are escaped to Unicode. If set to True, all non-ASCII characters are escaped; if False, original characters are kept. Only effective when format_json is True |
False |
||
save_to_img() |
Save the result as an image file | save_path |
str |
Path to save the file. If it is a directory, the saved file name will match the input file type | None |
- In addition, you can also access the visualized image and prediction result via attributes, as follows:
| Attribute | Description |
|---|---|
json |
Get the prediction result in json format |
img |
Get the visualized image in dict format |
IV. Custom Development¶
If the models above do not perform well in your scenario, you can try the following steps for custom development.
Here we take training PP-FormulaNet_plus-M as an example. For other models, just replace the corresponding config file. First, you need to prepare a formula recognition dataset. You can follow the format of the formula recognition demo data. Once the data is ready, follow the steps below to train and export the model. After export, the model can be quickly integrated into the API described above. This example uses the demo dataset. Before training the model, please ensure you have installed all PaddleOCR dependencies as described in the installation documentation.
4.1 Environment Setup¶
To train the formula recognition model, you need to install additional Python and Linux dependencies. Run the following commands:
sudo apt-get update
sudo apt-get install libmagickwand-dev
pip install tokenizers==0.19.1 imagesize ftfy Wand
4.2 Dataset and Pretrained Model Preparation¶
4.2.1 Prepare the Dataset¶
# Download the demo dataset
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/data/ocr_rec_latexocr_dataset_example.tar
tar -xf ocr_rec_latexocr_dataset_example.tar
4.2.2 Download the Pretrained Model¶
# Download the PP-FormulaNet_plus-M pre-trained model
wget https://paddleocr.bj.bcebos.com/contribution/rec_ppformulanet_plus_m_train.tar
tar -xf rec_ppformulanet_plus_m_train.tar
4.3 Model Training¶
PaddleOCR is modularized. To train the PP-FormulaNet_plus-M model, you need to use its config file.
Training commands are as follows:
# Single GPU training (default)
python3 tools/train.py -c configs/rec/PP-FormuaNet/PP-FormulaNet_plus-M.yaml \
-o Global.pretrained_model=./rec_ppformulanet_plus_m_train/best_accuracy.pdparams
# Multi-GPU training, specify GPU IDs with --gpus
python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/rec/PP-FormuaNet/PP-FormulaNet_plus-M.yaml \
-o Global.pretrained_model=./rec_ppformulanet_plus_m_train/best_accuracy.pdparams
- By default, evaluation is performed every 1 epoch.If you change the batch size or dataset, modify the following accordingly:
4.4 Model Evaluation¶
You can evaluate trained weights, e.g., output/xxx/xxx.pdparams, or use the downloaded model with the following command:
# Make sure pretrained_model is set to the local path.
# For custom-trained models, modify the path and file name as {path/to/weights}/{model_name}
# Demo test set evaluation
python3 tools/eval.py -c configs/rec/PP-FormuaNet/PP-FormulaNet_plus-M.yaml -o \
Global.pretrained_model=./rec_ppformulanet_plus_m_train/best_accuracy.pdparams
4.5 Model Export¶
python3 tools/export_model.py -c configs/rec/PP-FormuaNet/PP-FormulaNet_plus-M.yaml -o \
Global.pretrained_model=./rec_ppformulanet_plus_m_train/best_accuracy.pdparams \
Global.save_inference_dir="./PP-FormulaNet_plus-M_infer/"
After exporting, the static graph model will be saved in ./PP-FormulaNet_plus-M_infer/, and you will see the following files:
V. FAQ¶
Q1: Which formula recognition model does PaddleOCR recommend?
A1: It is recommended to use the PP-FormulaNet series. If your scenario is mainly in English and inference speed is not a concern, use PP-FormulaNet-L or PP-FormulaNet_plus-L. For mainly Chinese use cases, use PP-FormulaNet_plus-L or PP-FormulaNet_plus-M. If your device has limited computing power and you are working with English formulas, use PP-FormulaNet-S.
Q2: Why does the inference report an error? A2: The formula recognition model depends heavily on Paddle 3.0 official release. Please ensure the correct version is installed.
Q3: Why is there no visualization image after prediction? A3: This may be due to LaTeX not being installed.You need to refer to Section III and install the LaTeX rendering tools.