Table Recognition¶
1. pipeline¶
The table recognition mainly contains three models
- Single line text detection-DB
- Single line text recognition-CRNN
- Table structure and cell coordinate prediction-SLANet
The table recognition flow chart is as follows
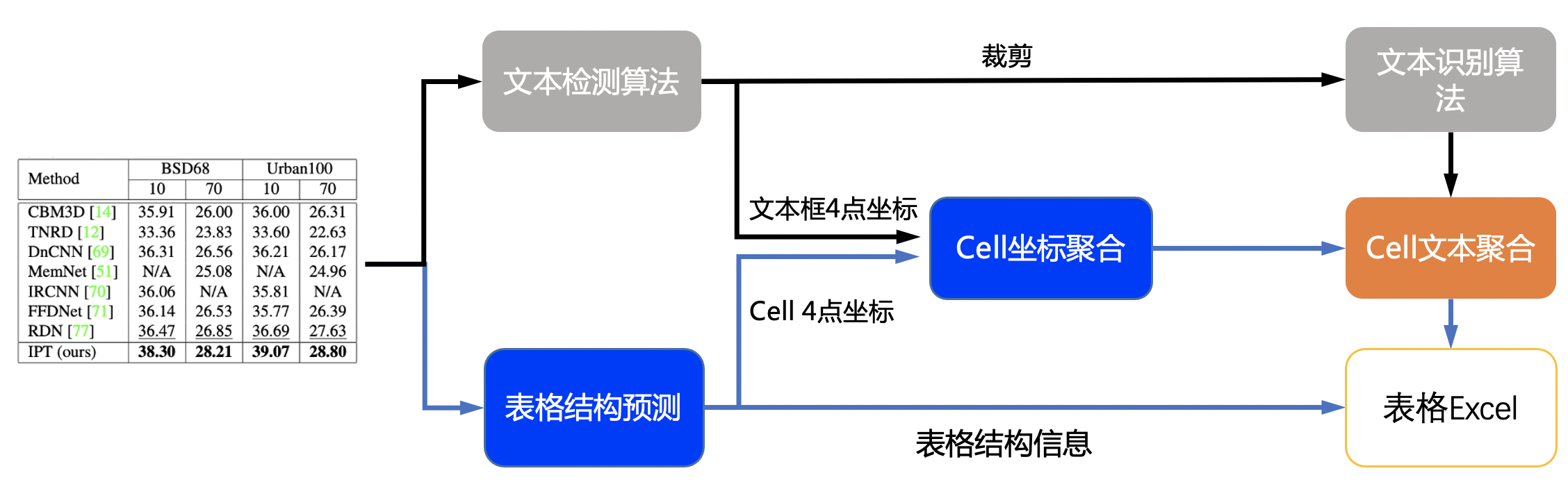
- The coordinates of single-line text is detected by DB model, and then sends it to the recognition model to get the recognition result.
- The table structure and cell coordinates is predicted by SLANet model.
- The recognition result of the cell is combined by the coordinates, recognition result of the single line and the coordinates of the cell.
- The cell recognition result and the table structure together construct the html string of the table.
2. Performance¶
We evaluated the algorithm on the PubTabNet[1] eval dataset, and the performance is as follows:
| Method | Acc | TEDS(Tree-Edit-Distance-based Similarity) | Speed |
|---|---|---|---|
| EDD[2] | x | 88.30% | x |
| TableRec-RARE(ours) | 71.73% | 93.88% | 779ms |
| SLANet(ours) | 76.31% | 95.89% | 766ms |
The performance indicators are explained as follows:
- Acc: The accuracy of the table structure in each image, a wrong token is considered an error.
- TEDS: The accuracy of the model's restoration of table information. This indicator evaluates not only the table structure, but also the text content in the table.
- Speed: The inference speed of a single image when the model runs on the CPU machine and MKL is enabled.
3. Result¶
4. How to use¶
4.1 Quick start¶
PP-Structure currently provides table recognition models in both Chinese and English. For the model link, see models_list. The whl package is also provided for quick use, see quickstart for details.
The following takes the Chinese table recognition model as an example to introduce how to recognize a table.
Use the following commands to quickly complete the identification of a table.
After the operation is completed, the excel table of each image will be saved to the directory specified by the output field, and an html file will be produced in the directory to visually view the cell coordinates and the recognized table.
NOTE
- If you want to use the English table recognition model, you need to download the English text detection and recognition model and the English table recognition model in models_list, and replace
table_structure_dict_ch.txtwithtable_structure_dict.txt. - To use the TableRec-RARE model, you need to replace
table_structure_dict_ch.txtwithtable_structure_dict.txt, and add parameter--merge_no_span_structure=False
4.2 Training, Evaluation and Inference¶
The training, evaluation and inference process of the text detection model can be referred to detection
The training, evaluation and inference process of the text recognition model can be referred to recognition
The training, evaluation and inference process of the table recognition model can be referred to table_recognition
4.3 Calculate TEDS¶
The table uses TEDS(Tree-Edit-Distance-based Similarity) as the evaluation metric of the model. Before the model evaluation, the three models in the pipeline need to be exported as inference models (we have provided them), and the gt for evaluation needs to be prepared. Examples of gt are as follows:
PMC5755158_010_01.png <html><body><table><thead><tr><td></td><td><b>Weaning</b></td><td><b>Week 15</b></td><td><b>Off-test</b></td></tr></thead><tbody><tr><td>Weaning</td><td>–</td><td>–</td><td>–</td></tr><tr><td>Week 15</td><td>–</td><td>0.17 ± 0.08</td><td>0.16 ± 0.03</td></tr><tr><td>Off-test</td><td>–</td><td>0.80 ± 0.24</td><td>0.19 ± 0.09</td></tr></tbody></table></body></html>
Each line in gt consists of the file name and the html string of the table. The file name and the html string of the table are separated by \t.
You can also use the following command to generate an evaluation gt file from the annotation file:
Use the following command to evaluate. After the evaluation is completed, the teds indicator will be output.
Evaluate on the PubLatNet dataset using the English model
output is