Enhanced CTC Loss¶
In OCR recognition, CRNN is a text recognition algorithm widely applied in the industry. In the training phase, it uses CTCLoss to calculate the network loss. In the inference phase, it uses CTCDecode to obtain the decoding result. Although the CRNN algorithm has been proven to achieve reliable recognition results in actual business, users have endless requirements for recognition accuracy. So how to improve the accuracy of text recognition? Taking CTCLoss as the starting point, this paper explores the improved fusion scheme of CTCLoss from three different perspectives: Hard Example Mining, Multi-task Learning, and Metric Learning. Based on the exploration, we propose EnhancedCTCLoss, which includes the following 3 components: Focal-CTC Loss, A-CTC Loss, C-CTC Loss.
1. Focal-CTC Loss¶
Focal Loss was proposed by the paper, "Focal Loss for Dense Object Detection". When the loss was first proposed, it was mainly to solve the problem of a serious imbalance in the ratio of positive and negative samples in one-stage target detection. This loss function reduces the weight of a large number of simple negative samples in training and also can be understood as a kind of difficult sample mining. The form of the loss function is as follows:
Among them, y' is the output of the activation function, and the value is between 0-1. It adds a modulation factor (1-y’)^γ and a balance factor α on the basis of the original cross-entropy loss. When α = 1, y = 1, the comparison between the loss function and the cross-entropy loss is shown in the following figure:
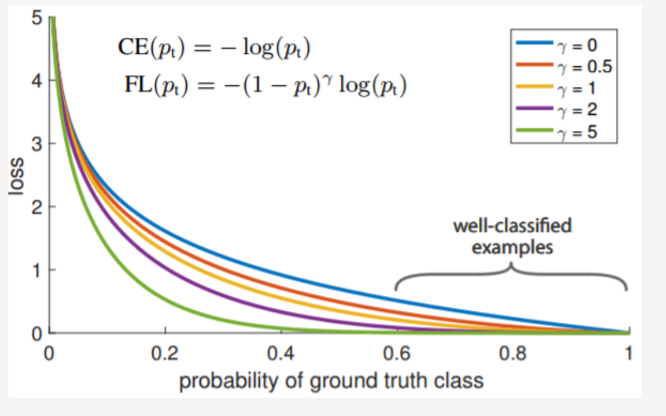
As can be seen from the above figure, when γ > 0, the adjustment coefficient (1-y’)^γ gives smaller weight to the easy-to-classify sample loss, making the network pay more attention to the difficult and misclassified samples. The adjustment factor γ is used to adjust the rate at which the weight of simple samples decreases. When γ = 0, it is the cross-entropy loss function. When γ increases, the influence of the adjustment factor will also increase. Experiments revealed that 2 is the optimal value of γ. The balance factor α is used to balance the uneven proportions of the positive and negative samples. In the text, α is taken as 0.25.
For the classic CTC algorithm, suppose a certain feature sequence (f1, f2, ......ft), after CTC decoding, the probability that the result is equal to label is y', then the probability that the CTC decoding result is not equal to label is (1-y'); it is not difficult to find that the CTCLoss value and y' have the following relationship:
Combining the idea of Focal Loss, assigning larger weights to difficult samples and smaller weights to simple samples can make the network focus more on the mining of difficult samples and further improve the accuracy of recognition. Therefore, we propose Focal-CTC Loss. Its definition is as follows:
In the experiment, the value of γ is 2, α = 1, see this for specific implementation: rec_ctc_loss.py
2. A-CTC Loss¶
A-CTC Loss is short for CTC Loss + ACE Loss. Among them, ACE Loss was proposed by the paper, “Aggregation Cross-Entropy for Sequence Recognition”. Compared with CTCLoss, ACE Loss has the following two advantages: + ACE Loss can solve the recognition problem of 2-D text, while CTCLoss can only process 1-D text + ACE Loss is better than CTC loss in time complexity and space complexity
The advantages and disadvantages of the OCR recognition algorithm summarized by the predecessors are shown in the following figure:
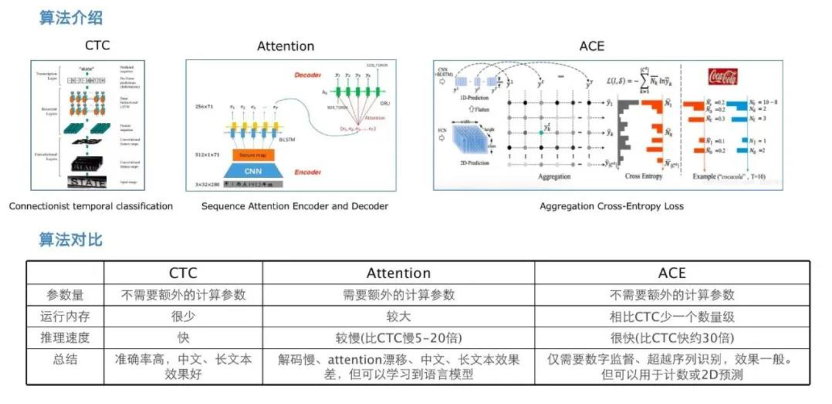
Although ACELoss does handle 2D predictions, as shown in the figure above, and has advantages in memory usage and inference speed, in practice, we found that using ACELoss alone, the recognition effect is not as good as CTCLoss. Consequently, we tried to combine CTCLoss and ACELoss, and CTCLoss is the mainstay while ACELoss acts as an auxiliary supervision loss. This attempt has achieved better results. On our internal experimental data set, compared to using CTCLoss alone, the recognition accuracy can be improved by about 1%. A_CTC Loss is defined as follows:
In the experiment, λ = 0.1. See the ACE loss implementation code: ace_loss.py
3. C-CTC Loss¶
C-CTC Loss is short for CTC Loss + Center Loss. Among them, Center Loss was proposed by the paper, “A Discriminative Feature Learning Approach for Deep Face Recognition“. It was first used in face recognition tasks to increase the distance between classes and reduce the distance within classes. It is an earlier and also widely used algorithm.
In the task of Chinese OCR recognition, through the analysis of bad cases, we found that a major difficulty in Chinese recognition is that there are many similar characters, which are easy to misunderstand. From this, we thought about whether we can learn from the idea of n to increase the class spacing of similar characters, to improve recognition accuracy. However, Metric Learning is mainly used in the field of image recognition, and the label of the training data is a fixed value; for OCR recognition, it is a sequence recognition task essentially, and there is no explicit alignment between features and labels. Therefore, how to combine the two is still a direction worth exploring.
By trying Arcmargin, Cosmargin and other methods, we finally found that Centerloss can help further improve the accuracy of recognition. C_CTC Loss is defined as follows:
In the experiment, we set λ=0.25. See the center_loss implementation code: center_loss.py
It is worth mentioning that in C-CTC Loss, choosing to initialize the Center randomly does not bring significant improvement. Our Center initialization method is as follows: + Based on the original CTCLoss, a network N is obtained by training + Select the training set, identify the completely correct part, and form the set G + Send each sample in G to the network, perform forward calculation, and extract the correspondence between the input of the last FC layer (ie feature) and the result of argmax calculation (ie index) + Aggregate features with the same index, calculate the average, and get the initial center of each character.
Taking the configuration file configs/rec/ch_PP-OCRv2/ch_PP-OCRv2_rec.yml as an example, the center extraction command is as follows:
After running, train_center.pkl will be generated in the main directory of PaddleOCR.
4. Experiment¶
For the above three solutions, we conducted training and evaluation based on Baidu's internal data set. The experimental conditions are shown in the following table:
| algorithm | Focal_CTC | A_CTC | C-CTC |
|---|---|---|---|
| gain | +0.3% | +0.7% | +1.7% |
Based on the above experimental conclusions, we adopted the C-CTC strategy in PP-OCRv2. It is worth mentioning that, because PP-OCRv2 deals with the recognition task of 6625 Chinese characters, the character set is relatively large and there are many similar characters, so the C-CTC solution brings a significant improvement on this task. But if you switch to other OCR recognition tasks, the conclusion may be different. You can try Focal-CTC, A-CTC, C-CTC, and the combined solution EnhancedCTC. We believe it will bring different degrees of improvement.
The unified combined plan is shown in the following file: rec_enhanced_ctc_loss.py