PaddleX 3.0 Pipeline Deployment Tutorial¶
Before using this tutorial, you need to install PaddleX. For installation instructions, please refer to the PaddleX Installation guide.
The three deployment methods of PaddleX are detailed below:
- High-Performance Inference: In actual production environments, many applications have stringent performance standards for deployment strategies, especially in terms of response speed, to ensure efficient system operation and smooth user experience. To this end, PaddleX provides a high-performance inference plugin aimed at deeply optimizing model inference and pre/post-processing for significant end-to-end speedups. For detailed high-performance inference procedures, please refer to the PaddleX High-Performance Inference Guide.
- Serving Deployment: Serving Deployment is a common deployment form in actual production environments. By encapsulating inference functionality as services, clients can access these services through network requests to obtain inference results. PaddleX supports users in achieving low-cost serving deployment in pipelines. For detailed serving deployment procedures, please refer to the PaddleX Serving Deployment Guide.
- Edge Deployment: Edge deployment is a method where computing and data processing functions are placed on the user's device itself, allowing the device to directly process data without relying on remote servers. PaddleX supports deploying models on edge devices such as Android. For detailed edge deployment procedures, please refer to the PaddleX Edge Deployment Guide.
This tutorial will introduce the three deployment methods of PaddleX through three practical application examples.
1 High-Performance Inference Example¶
1.1 Obtain Serial Number and Activation¶
On the Baidu AIStudio Community - AI Learning and Training Community page, select "Get Now" in the "Consultation and Acquisition of Serial Numbers for Open Source Pipeline Deployment" section, as shown in the figure below:

Select the pipeline you need to deploy and click "Get". Afterward, you can find the obtained serial number in the "Serial Number Management for Open Source Pipeline Deployment SDK" section below:
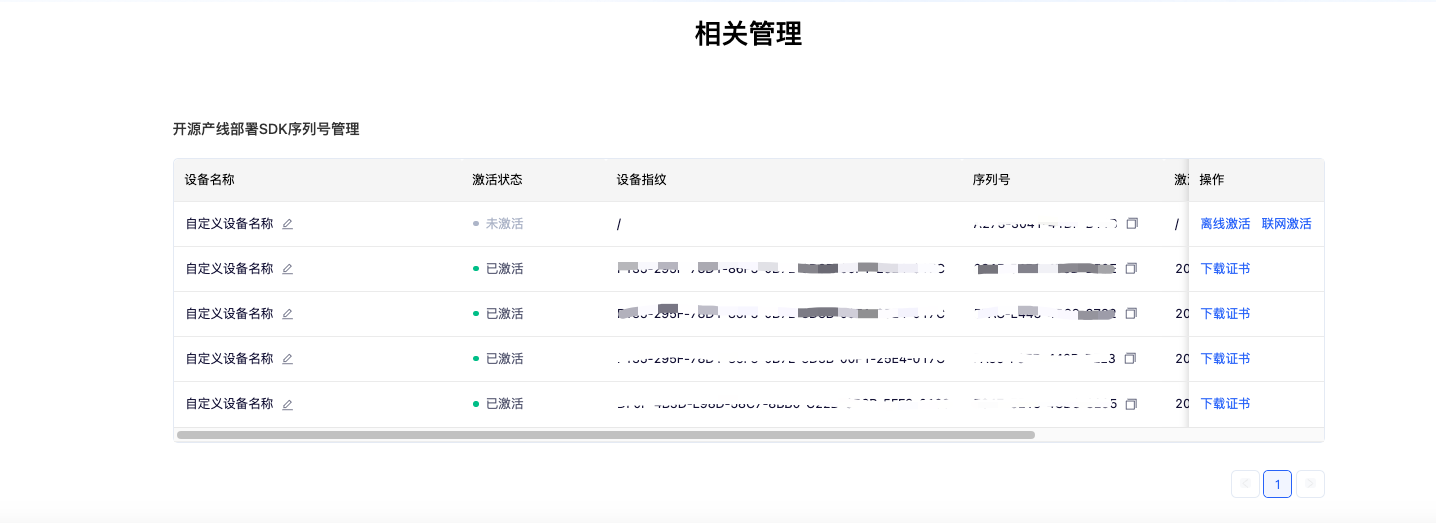
After using the serial number to complete activation, you can use the high-performance inference plugin. PaddleX provides both offline and online activation methods (both only support Linux systems):
- Online Activation: When using the inference API or CLI, specify the serial number and activate online, allowing the program to complete activation automatically.
- Offline Activation: Follow the instructions on the serial number management interface (click "Offline Activation" in "Operations") to obtain the device fingerprint of the machine and bind the serial number with the device fingerprint to obtain a certificate for activation. To use this activation method, you need to manually store the certificate in the
${HOME}/.baidu/paddlex/licensesdirectory on the machine (create the directory if it does not exist) and specify the serial number when using the inference API or CLI. Please note: Each serial number can only be bound to a unique device fingerprint and can only be bound once. This means that if users deploy models on different machines, they must prepare separate serial numbers for each machine.
1.2 Install High-Performance Inference Plugin¶
Find the corresponding installation command in the table below based on processor architecture, operating system, device type, Python version, and other information, and execute it in the deployment environment:
| Processor Architecture | Operating System | Device Type | Python Version | Installation Command |
|---|---|---|---|---|
| x86-64 | Linux | CPU | ||
| 3.8 | curl -s https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/deploy/paddlex_hpi/install_script/latest/install_paddlex_hpi.py | python3.8 - --arch x86_64 --os linux --device cpu --py 38 | |||
| 3.9 | curl -s https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/deploy/paddlex_hpi/install_script/latest/install_paddlex_hpi.py | python3.9 - --arch x86_64 --os linux --device cpu --py 39 | |||
| 3.10 | curl -s https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/deploy/paddlex_hpi/install_script/latest/install_paddlex_hpi.py | python3.10 - --arch x86_64 --os linux --device cpu --py 310 | |||
| GPU (CUDA 11.8 + cuDNN 8.6) | 3.8 | curl -s https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/deploy/paddlex_hpi/install_script/latest/install_paddlex_hpi.py | python3.8 - --arch x86_64 --os linux --device gpu_cuda118_cudnn86 --py 38 | ||
| 3.9 | curl -s https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/deploy/paddlex_hpi/install_script/latest/install_paddlex_hpi.py | python3.9 - --arch x86_64 --os linux --device gpu_cuda118_cudnn86 --py 39 | |||
| 3.10 | curl -s https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/deploy/paddlex_hpi/install_script/latest/install_paddlex_hpi.py | python3.10 - --arch x86_64 --os linux --device gpu_cuda118_cudnn86 --py 310 |
- When the device type is GPU, please use the installation command corresponding to the CUDA and cuDNN versions that match your environment; otherwise, the high-performance inference plugin will not function properly.
- For Linux systems, use Bash to execute the installation command.
- When the device type is CPU, the installed high-performance inference plugin only supports inference using the CPU; for other device types, the installed high-performance inference plugin supports inference using the CPU or other devices.
1.3 Enabling High-Performance Inference Plugins¶
Before enabling high-performance plugins, ensure that the LD_LIBRARY_PATH in the current environment does not specify the shared library directory of TensorRT, as the plugins already integrate TensorRT to avoid conflicts caused by different TensorRT versions that may prevent the plugins from functioning properly.
For PaddleX CLI, specify --use_hpip and set the serial number to enable the high-performance inference plugin. If you wish to activate online, specify --update_license when using the serial number for the first time, taking the General OCR pipeline as an example:
paddlex \
--pipeline OCR \
--input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png \
--device gpu:0 \
--use_hpip \
--serial_number {serial_number}
# If you wish to activate online
paddlex \
--pipeline OCR \
--input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png \
--device gpu:0 \
--use_hpip \
--update_license \
--serial_number {serial_number}
For the PaddleX Python API, the method to enable the high-performance inference plugin is similar. Again, taking the General OCR pipeline as an example:
from paddlex import create_pipeline
pipeline = create_pipeline(
pipeline="OCR",
use_hpip=True,
hpi_params={"serial_number": xxx}
)
output = pipeline.predict("https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png ")
The inference results obtained with the high-performance inference plugin are consistent with those without the plugin enabled. For some models, enabling the high-performance inference plugin for the first time may take a longer time to complete the construction of the inference engine. PaddleX will cache relevant information in the model directory after the first construction of the inference engine and reuse the cached content in subsequent initializations to improve speed.
1.4 Inference Steps¶
This inference process is based on PaddleX CLI, online activation of serial numbers, Python 3.10.0, and using a CPU device with the high-performance inference plugin. For other usage methods (such as different Python versions, device types, or PaddleX Python API), refer to the PaddleX High-Performance Inference Guide to replace the corresponding commands.
# Install the high-performance inference plugin
curl -s https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/deploy/paddlex_hpi/install_script/latest/install_paddlex_hpi.py | python3.10 - --arch x86_64 --os linux --device cpu --py 310
# Ensure that the `LD_LIBRARY_PATH` in the current environment does not specify the shared library directory of TensorRT. You can use the following command to remove it or manually remove it.
export LD_LIBRARY_PATH=$(echo $LD_LIBRARY_PATH | tr ':' '\n' | grep -v TensorRT | tr '\n' ':' | sed 's/:*$//')
# Perform inference
paddlex --pipeline OCR --input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png --device gpu:0 --use_hpip --serial_number {serial_number} --update_license True --save_path ./output
Output:


1.5 Changing Pipelines or Models¶
- Changing Pipelines:
If you want to use a different pipeline with the high-performance inference plugin, simply replace the value passed to --pipeline. Here is an example using the General Object Detection pipeline:
paddlex --pipeline object_detection --input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_object_detection_002.png --device gpu:0 --use_hpip --serial_number {serial_number} --update_license True --save_path ./output
- Changing Models:
The OCR pipeline defaults to using the PP-OCRv4_mobile_det and PP-OCRv4_mobile_rec models. If you want to use other models, such as PP-OCRv4_server_det and PP-OCRv4_server_rec, refer to the General OCR Pipeline Tutorial. The specific operations are as follows:
# 1. Obtain the OCR pipeline configuration file and save it to ./OCR.yaml
paddlex --get_pipeline_config OCR --save_path ./OCR.yaml
# 2. Modify the ./OCR.yaml configuration file
# Change the value of Pipeline.text_det_model to the path of the PP-OCRv4_server_det model
# Change the value of Pipeline.text_rec_model to the path of the PP-OCRv4_server_rec model
# 3. Use the modified configuration file when performing inference
paddlex --pipeline ./OCR.yaml --input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png --device gpu:0 --use_hpip --serial_number {serial_number} --update_license True --save_path ./output
The General Object Detection pipeline defaults to using the PicoDet-S model. If you want to use another model, such as RT-DETR, refer to the General Object Detection Pipeline Tutorial. The specific operations are as follows:
# 1. Obtain the OCR pipeline configuration file and save it to ./object_detection.yaml
paddlex --get_pipeline_config object_detection --save_path ./object_detection.yaml
# 2. Modify the ./object_detection.yaml configuration file
# Change the value of Pipeline.model to the path of the RT-DETR model
# 3. Use the modified configuration file when performing inference
paddlex --pipeline ./object_detection.yaml --input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png --device gpu:0 --use_hpip --serial_number {serial_number} --update_license True --save_path ./output
The operations for other pipelines are similar to those for the above two pipelines. For more details, refer to the pipeline usage tutorials.
2 Service Deployment Example¶
2.1 Installing the Service Deployment Plugin¶
Execute the following command to install the service deployment plugin:
2.2 Starting the Service¶
Start the service through the PaddleX CLI with the command format:
paddlex --serve --pipeline {Pipeline name or pipeline configuration file path} [{Other command-line options}]
Taking the General OCR pipeline as an example:
After the service starts successfully, you will see information similar to the following:
INFO: Started server process [63108]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
--pipeline can be specified as an official pipeline name or a local pipeline configuration file path. PaddleX constructs the pipeline based on this and deploys it as a service. To adjust configurations (such as model path, batch_size, deployment device), please refer to the "Model Application" section in the General OCR Pipeline Tutorial.
The command-line options related to service deployment are as follows:
| Name | Description |
|---|---|
--pipeline |
Pipeline name or pipeline configuration file path. |
--device |
Deployment device for the pipeline. Default is cpu (if GPU is not available) or gpu (if GPU is available). |
--host |
Hostname or IP address bound to the server. Default is 0.0.0.0. |
--port |
Port number listened to by the server. Default is 8080. |
--use_hpip |
Enables the high-performance inference plugin if specified. |
--serial_number |
Serial number used by the high-performance inference plugin. Only valid when the high-performance inference plugin is enabled. Please note that not all pipelines and models support the use of the high-performance inference plugin. For detailed support, please refer to the PaddleX High-Performance Inference Guide. |
--update_license |
Performs online activation if specified. Only valid when the high-performance inference plugin is enabled. |
2.3 Calling the Service¶
Here, only the Python calling example is shown. For API references and service calling examples in other languages, please refer to the "Calling the Service" section in the "Development Integration/Deployment" part of each pipeline usage tutorial in the PaddleX Serving Deployment Guide.
import base64
import requests
API_URL = "http://localhost:8080/ocr" # Service URL
image_path = "./demo.jpg"
output_image_path = "./out.jpg"
# Encode the local image in Base64
with open(image_path, "rb") as file:
image_bytes = file.read()
image_data = base64.b64encode(image_bytes).decode("ascii")
payload = {"image": image_data} # Base64-encoded file content or image URL
# Call the API
response = requests.post(API_URL, json=payload)
# Process the response data
assert response.status_code == 200
result = response.json()["result"]
with open(output_image_path, "wb") as file:
file.write(base64.b64decode(result["image"]))
print(f"Output image saved at {output_image_path}")
print("\nDetected texts:")
print(result["texts"])
2.4 Deployment Steps¶
# Install the service deployment plugin
paddlex --install serving
# Start the service
paddlex --serve --pipeline OCR
# Call the service | The code in fast_test.py is a Python calling example from the previous section
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png -O demo.jpg
python fast_test.py
Running Results:

2.5 Change Pipelines or Models¶
- Change Pipelines:
If you want to deploy another pipeline for service, simply replace the value passed to --pipeline. The following example uses the General Object Detection pipeline:
- Change Models:
The OCR pipeline defaults to using the PP-OCRv4_mobile_det and PP-OCRv4_mobile_rec models. If you want to switch to other models, such as PP-OCRv4_server_det and PP-OCRv4_server_rec, refer to the General OCR Pipeline Tutorial. The specific steps are as follows:
# 1. Obtain the OCR pipeline configuration file and save it as ./OCR.yaml
paddlex --get_pipeline_config OCR --save_path ./OCR.yaml
# 2. Modify the ./OCR.yaml configuration file
# Change the value of Pipeline.text_det_model to the path of the PP-OCRv4_server_det model
# Change the value of Pipeline.text_rec_model to the path of the PP-OCRv4_server_rec model
# 3. Start the service using the modified configuration file
paddlex --serve --pipeline ./OCR.yaml
# 4. Call the service
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png -O demo.jpg
python fast_test.py
The General Object Detection pipeline defaults to using the PicoDet-S model. If you want to switch to another model, such as RT-DETR, refer to the General Object Detection Pipeline Tutorial. The specific steps are as follows:
# 1. Obtain the object detection pipeline configuration file and save it as ./object_detection.yaml
paddlex --get_pipeline_config object_detection --save_path ./object_detection.yaml
# 2. Modify the ./object_detection.yaml configuration file
# Change the value of Pipeline.model to the path of the RT-DETR model
# 3. Start the service using the modified configuration file
paddlex --serve --pipeline ./object_detection.yaml
# 4. Call the service | fast_test.py needs to be replaced with the Python calling example from the General Object Detection Pipeline Tutorial
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png -O demo.jpg
python fast_test.py
The operations for other pipelines are similar to the above two. For more details, refer to the pipeline usage tutorials.
3 Edge Deployment Example¶
3.1 Environment Preparation¶
-
Install the CMake compilation tool locally and download the required version of the NDK software package from the Android NDK official website. For example, if developing on a Mac, download the NDK software package for the Mac platform from the Android NDK website.
Environment Requirements -
CMake >= 3.10(the minimum version is not verified, but 3.20 and above are recommended) -Android NDK >= r17c(the minimum version is not verified, but r20b and above are recommended)Testing Environment Used in This Guide: -
cmake == 3.20.0-android-ndk == r20b -
Prepare an Android phone and enable USB debugging mode. Enable method:
Phone Settings -> Find Developer Options -> Turn on Developer Options and USB Debugging Mode. -
Install the ADB tool on your computer for debugging. The ADB installation methods are as follows:
3.1. Install ADB on Mac
3.2. Install ADB on Linux
# Installation method for Debian-based Linux distributions sudo apt update sudo apt install -y wget adb # Installation method for Red Hat-based Linux distributions sudo yum install adb3.3. Install ADB on Windows
To install on Windows, go to Google's Android platform to download the ADB software package for installation: Link
Open the terminal, connect the phone to the computer, and enter in the terminal
If there is a device output, it indicates successful installation.
3.2 Material Preparation¶
-
Clone the
feature/paddle-xbranch of thePaddle-Lite-Demorepository into thePaddleX-Lite-Deploydirectory. -
Fill out the survey to download the compressed package, place the compressed package in the specified extraction directory, switch to the specified extraction directory, and execute the extraction command.
3.3 Deployment Steps¶
-
Switch the working directory to
PaddleX-Lite-Deploy/libs, run thedownload.shscript to download the required Paddle Lite prediction library. This step only needs to be executed once to support each demo. -
Switch the working directory to
PaddleX-Lite-Deploy/ocr/assets, run thedownload.shscript to download the model files optimized by the paddle_lite_opt tool. -
Switch the working directory to
PaddleX-Lite-Deploy/ocr/android/shell/cxx/ppocr_demo, run thebuild.shscript to complete the compilation of the executable file. -
Switch the working directory to
PaddleX-Lite-Deploy/ocr/android/shell/cxx/ppocr_demo, run therun.shscript to complete the inference on the edge side.
Notes:
- Before running the build.sh script, you need to change the path specified by NDK_ROOT to the actual installed NDK path.
- You can execute the deployment steps using Git Bash on a Windows system.
- If compiling on a Windows system, set CMAKE_SYSTEM_NAME in CMakeLists.txt to windows.
- If compiling on a Mac system, set CMAKE_SYSTEM_NAME in CMakeLists.txt to darwin.
- Maintain an ADB connection when running the run.sh script.
- The download.sh and run.sh scripts support passing parameters to specify models. If not specified, the PP-OCRv4_mobile model is used by default. Currently, two models are supported:
- PP-OCRv3_mobile
- PP-OCRv4_mobile
Here are examples of actual operations:
# 1. Download the required Paddle Lite prediction library
cd PaddleX-Lite-Deploy/libs
sh download.sh
# 2. Download the model files optimized by the paddle_lite_opt tool
cd ../ocr/assets
sh download.sh PP-OCRv4_mobile
# 3. Complete the compilation of the executable file
cd ../android/shell/ppocr_demo
sh build.sh
# 4. Inference
sh run.sh PP-OCRv4_mobile
Detection Results:

Recognition Results:
The detection visualized image saved in ./test_img_result.jpg
0 Pure Nutrition Hair Conditioner 0.993706
1 Product Information/Parameters 0.991224
2 (45 yuan/kg, minimum order 100 kg) 0.938893
3 Each bottle 22 yuan, minimum order 1000 bottles) 0.988353
4 [Brand]: OEM/ODM Manufacturing 0.97557
5 [Product Name]: Pure Nutrition Hair Conditioner 0.986914
6 OEM/ODM 0.929891
7 [Product Number]: YM-X-3011 0.964156
8 [Net Content]: 220ml 0.976404
9 [Suitable for]: All skin types 0.987942
10 [Main Ingredients]: Cetyl Stearyl Alcohol, Oat β-Glucan, 0.968315
11 Cocoamide Propyl Betaine, Panthenol 0.941537
12 (Finished Product Packaging) 0.974796
13 [Main Function]: Can tighten the hair鳞片, achieving 0.988799
14 immediate and lasting improvement in hair gloss, providing sufficient nourishment to dry hair 0.989547
15 [Main Function Continued]: Nourishment 0.998413