Time Series Anomaly Detection Pipeline Tutorial¶
1. Introduction to the General Time Series Anomaly Detection Pipeline¶
Time series anomaly detection is a technique for identifying abnormal patterns or behaviors in time series data. It is widely applied in fields such as network security, equipment monitoring, and financial fraud detection. By analyzing normal trends and patterns in historical data, it discovers events that significantly deviate from expected behaviors, such as sudden spikes in network traffic or unusual transaction activities. Time series anomaly detection enable automatic identification of anomalies in data. This technology provides real-time alerts for enterprises and organizations, helping them promptly address potential risks and issues. It plays a crucial role in ensuring system stability and security.
The General Time Series Anomaly Detection Pipeline includes a time series anomaly detection module. If you prioritize model accuracy, choose a model with higher precision. If you prioritize inference speed, select a model with faster inference. If you prioritize model storage size, choose a model with a smaller storage footprint.
| Model Name | Model Download Link | Precision | Recall | F1-Score | Model Storage Size (M) |
|---|---|---|---|---|---|
| AutoEncoder_ad | Inference Model/Training Model | 99.36 | 84.36 | 91.25 | 52K |
| DLinear_ad | Inference Model/Training Model | 98.98 | 93.96 | 96.41 | 112K |
| Nonstationary_ad | Inference Model/Training Model | 98.55 | 88.95 | 93.51 | 1.8M |
| PatchTST_ad | Inference Model/Training Model | 98.78 | 90.70 | 94.57 | 320K |
| TimesNet_ad | Inference Model/Training Model | 98.37 | 94.80 | 96.56 | 1.3M |
Test Environment Description:
- Performance Test Environment
- Test Dataset:PSM dataset.
- Hardware Configuration:
- GPU: NVIDIA Tesla T4
- CPU: Intel Xeon Gold 6271C @ 2.60GHz
- Other Environments: Ubuntu 20.04 / cuDNN 8.6 / TensorRT 8.5.2.2
- Inference Mode Description
| Mode | GPU Configuration | CPU Configuration | Acceleration Technology Combination |
|---|---|---|---|
| Normal Mode | FP32 Precision / No TRT Acceleration | FP32 Precision / 8 Threads | PaddleInference |
| High-Performance Mode | Optimal combination of pre-selected precision types and acceleration strategies | FP32 Precision / 8 Threads | Pre-selected optimal backend (Paddle/OpenVINO/TRT, etc.) |
2. Quick Start¶
The pre-trained model pipelines provided by PaddleX allow for quick experience of their effects. You can experience the effects of the General Time Series Anomaly Detection Pipeline online or locally using command line or Python.
2.1 Online Experience¶
You can experience online the effects of the General Time Series Anomaly Detection Pipeline using the official demo for recognition, for example:
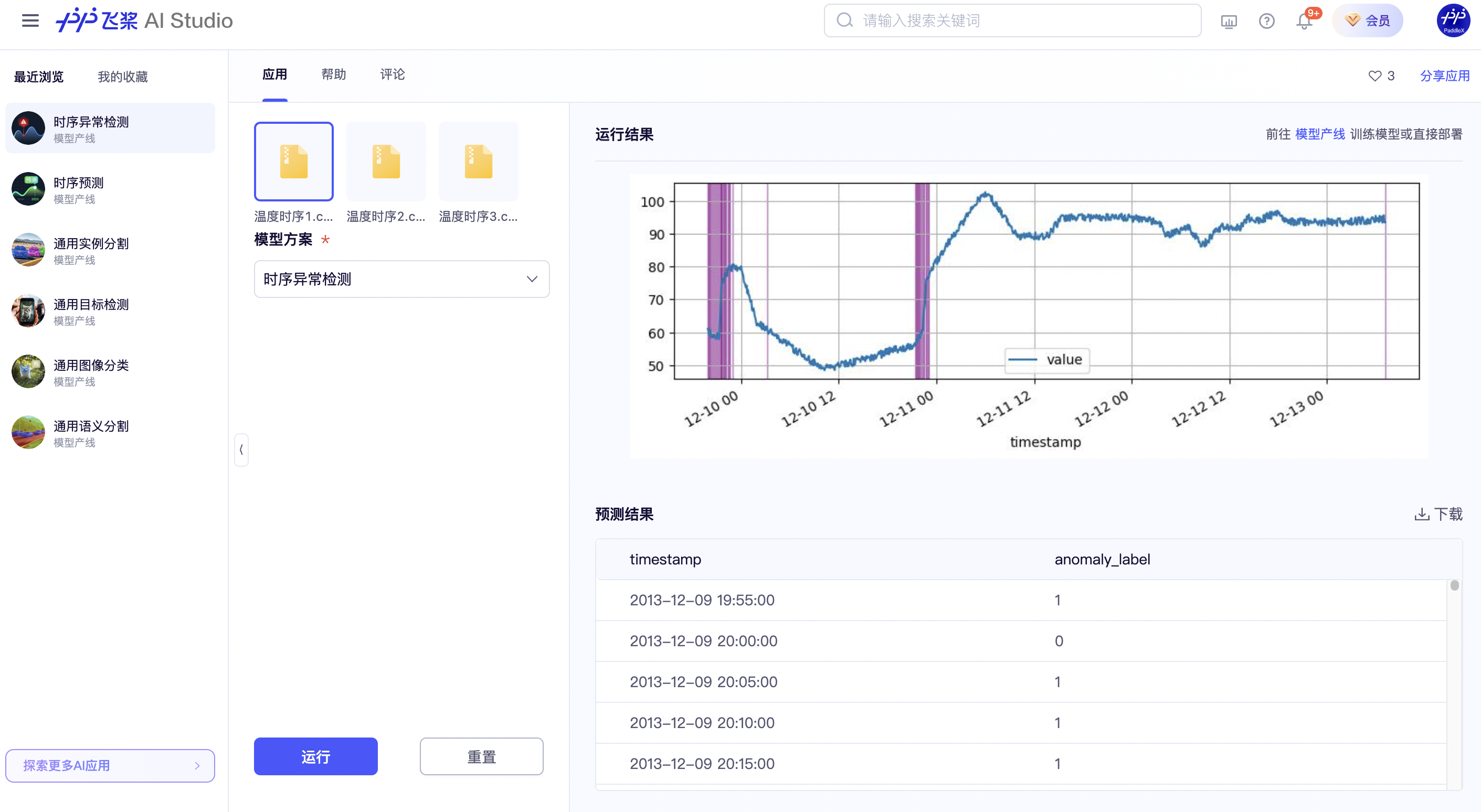
If you are satisfied with the pipeline's performance, you can directly integrate and deploy it. If not, you can also use your private data to fine-tune the model within the pipeline online.
Note: Due to the close relationship between time series data and scenarios, the official built-in models for online experience of time series tasks are only model solutions for a specific scenario and are not universal. They are not applicable to other scenarios. Therefore, the experience mode does not support using arbitrary files to experience the effects of the official model solutions. However, after training a model for your own scenario data, you can select your trained model solution and use data from the corresponding scenario for online experience.
2.2 Local Experience¶
Before using the general time-series anomaly detection pipeline locally, please ensure that you have completed the installation of the PaddleX wheel package according to the PaddleX Local Installation Guide.
2.2.1 Command Line Experience¶
You can quickly experience the time-series anomaly detection pipeline with a single command. Use the test file and replace --input with the local path for prediction.
For the explanation of the parameters, you can refer to the parameter description in Section 2.2.2 Integration via Python Script.
After running the command, the results will be printed to the terminal as follows:
{'input_path': 'ts_ad.csv', 'anomaly': label
timestamp
220226 0
220227 0
220228 0
220229 0
220230 0
... ...
220317 1
220318 1
220319 1
220320 1
220321 0
[96 rows x 1 columns]}
The result of the time series file is saved under save_path.
2.2.2 Integration via Python Script¶
The above command line is for a quick experience to view the results. Generally, in a project, it is often necessary to integrate through code. You can complete the fast inference of the pipeline with just a few lines of code. The inference code is as follows:
from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="ts_anomaly_detection")
output = pipeline.predict("ts_ad.csv")
for res in output:
res.print() ## 打印预测的结构化输出
res.save_to_csv(save_path="./output/") ## 保存csv格式结果
res.save_to_json(save_path="./output/") ## 保存json格式结果
In the above Python script, the following steps are performed:
(1) Instantiate the pipeline object through create_pipeline(): The specific parameter descriptions are as follows:
| Parameter | Description | Type | Default Value |
|---|---|---|---|
pipeline |
The name of the pipeline or the path to the pipeline configuration file. If it is the name of the pipeline, it must be a pipeline supported by PaddleX. | str |
None |
config |
Specific configuration information for the pipeline (if set simultaneously with pipeline, it takes precedence over pipeline, and the pipeline name must be consistent with pipeline). |
dict[str, Any] |
None |
device |
The inference device for the pipeline. It supports specifying the specific card number of the hardware, such as "gpu:0" for GPU, "npu:0" for NPU, or "cpu" for CPU. | str |
gpu:0 |
use_hpip |
Whether to enable high-performance inference. This is only available if the pipeline supports high-performance inference. | bool |
False |
(2) Call the predict() method of the ts_anomaly_detection pipeline object for inference prediction. This method returns a generator. The parameters and their descriptions for the predict() method are as follows:
| Parameter | Description | Type | Options | Default Value |
|---|---|---|---|---|
input |
The data to be predicted. It supports multiple input types and is required. | Python Var|str|list |
|
None |
device |
The inference device for the pipeline. | str|None |
|
None |
- In addition, it also supports obtaining prediction results in different formats through attributes, as follows:
| Attribute | Attribute Description |
|---|---|
json |
Obtain the prediction result in json format |
csv |
Obtain the prediction result in csv format |
- The prediction result obtained through the
jsonattribute is of dict type, and its content is consistent with the content saved by calling thesave_to_json()method. - The
csvattribute returns aPandas.DataFrametype data, which contains the time series anomaly detection results.
In addition, you can obtain the configuration file of the ts_anomaly_detection pipeline and load the configuration file for prediction. You can execute the following command to save the result in my_path:
If you have obtained the configuration file, you can customize the settings for the time series anomaly detection pipeline by simply modifying the pipeline parameter value in the create_pipeline method to the path of the pipeline configuration file.
For example, if your configuration file is saved at ./my_path/ts_anomaly_detection.yaml, you just need to execute:
from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="./my_path/ts_anomaly_detection.yaml")
output = pipeline.predict("ts_ad.csv")
for res in output:
res.print()
res.save_to_csv("./output/")
res.save_to_json("./output/")
3. Development Integration/Deployment¶
If the pipeline meets your requirements for inference speed and accuracy, you can proceed directly with development integration/deployment.
If you need to apply the pipeline directly in your Python project, you can refer to the example code in 2.2.2 Python Script Method.
In addition, PaddleX also provides three other deployment methods, which are detailed as follows:
🚀 High-Performance Inference: In actual production environments, many applications have strict performance requirements for deployment strategies, especially in terms of response speed, to ensure efficient system operation and smooth user experience. To this end, PaddleX provides a high-performance inference plugin, which aims to deeply optimize the performance of model inference and pre/post-processing to significantly speed up the end-to-end process. For details on high-performance inference, please refer to the PaddleX High-Performance Inference Guide.
☁️ Service-based Deployment: Service-based deployment is a common form of deployment in actual production environments. By encapsulating the inference function as a service, clients can access these services through network requests to obtain inference results. PaddleX supports various service-based deployment solutions for pipelines. For details on service-based deployment, please refer to the PaddleX Service-based Deployment Guide.
Below are the API references for basic service-based deployment and examples of multi-language service calls:
API Reference
For the main operations provided by the service:
- The HTTP request method is POST.
- Both the request body and response body are JSON data (JSON objects).
- When the request is processed successfully, the response status code is
200, and the attributes of the response body are as follows:
| Name | Type | Meaning |
|---|---|---|
logId |
string |
The UUID of the request. |
errorCode |
integer |
Error code. Fixed as 0. |
errorMsg |
string |
Error message. Fixed as "Success". |
result |
object |
The result of the operation. |
- When the request is not processed successfully, the attributes of the response body are as follows:
| Name | Type | Meaning |
|---|---|---|
logId |
string |
The UUID of the request. |
errorCode |
integer |
Error code. Same as the response status code. |
errorMsg |
string |
Error message. |
The main operations provided by the service are as follows:
infer
Perform time-series anomaly detection.
POST /time-series-anomaly-detection
- The attributes of the request body are as follows:
| Name | Type | Meaning | Required |
|---|---|---|---|
csv |
string |
The URL of a CSV file accessible by the server or the Base64-encoded content of a CSV file. The CSV file must be encoded in UTF-8. | Yes |
- When the request is processed successfully, the
resultof the response body has the following attributes:
| Name | Type | Meaning |
|---|---|---|
image |
string | null |
The image of time series anomaly detection result. The image is in JPEG format and encoded in Base64. |
csv |
string |
The result of time-series anomaly detection in CSV format. Encoded in UTF-8+Base64. |
An example of result is as follows:
{
"csv": "xxxxxx",
"image": "xxxxxx"
}
Multi-language Service Invocation Example
Python
import base64
import requests
API_URL = "http://localhost:8080/time-series-anomaly-detection" # Service URL
csv_path = "./test.csv"
output_image_path = "./out.jpg"
output_csv_path = "./out.csv"
# Encode the local CSV file using Base64
with open(csv_path, "rb") as file:
csv_bytes = file.read()
csv_data = base64.b64encode(csv_bytes).decode("ascii")
payload = {"csv": csv_data}
# Call the API
response = requests.post(API_URL, json=payload)
# Process the response data
assert response.status_code == 200
result = response.json()["result"]
with open(output_image_path, "wb") as f:
f.write(base64.b64decode(result["image"]))
print(f"Output image saved at {output_image_path}")
with open(output_csv_path, "wb") as f:
f.write(base64.b64decode(result["csv"]))
print(f"Output time-series data saved at {output_csv_path}")
C++
#include
#include "cpp-httplib/httplib.h" // https://github.com/Huiyicc/cpp-httplib
#include "nlohmann/json.hpp" // https://github.com/nlohmann/json
#include "base64.hpp" // https://github.com/tobiaslocker/base64
int main() {
httplib::Client client("localhost:8080");
const std::string csvPath = "./test.csv";
const std::string outputImagePath = "./out.jpg";
const std::string outputCsvPath = "./out.csv";
httplib::Headers headers = {
{"Content-Type", "application/json"}
};
// Perform Base64 encoding
std::ifstream file(csvPath, std::ios::binary | std::ios::ate);
std::streamsize size = file.tellg();
file.seekg(0, std::ios::beg);
std::vector buffer(size);
if (!file.read(buffer.data(), size)) {
std::cerr << "Error reading file." << std::endl;
return 1;
}
std::string bufferStr(reinterpret_cast(buffer.data()), buffer.size());
std::string encodedCsv = base64::to_base64(bufferStr);
nlohmann::json jsonObj;
jsonObj["csv"] = encodedCsv;
std::string body = jsonObj.dump();
// Call the API
auto response = client.Post("/time-series-anomaly-detection", headers, body, "application/json");
// Process the response data
if (response && response->status == 200) {
nlohmann::json jsonResponse = nlohmann::json::parse(response->body);
auto result = jsonResponse["result"];
// Save the data
std::string encodedImage = result["image"];
std::string decodedString = base64::from_base64(encodedImage);
std::vector decodedImage(decodedString.begin(), decodedString.end());
std::ofstream outputImage(outputImagePath, std::ios::binary | std::ios::out);
if (outputImage.is_open()) {
outputImage.write(reinterpret_cast(decodedImage.data()), decodedImage.size());
outputImage.close();
std::cout << "Output image data saved at " << outputImagePath << std::endl;
} else {
std::cerr << "Unable to open file for writing: " << outputImagePath << std::endl;
}
encodedCsv = result["csv"];
decodedString = base64::from_base64(encodedCsv);
std::vector decodedCsv(decodedString.begin(), decodedString.end());
std::ofstream outputCsv(outputCsvPath, std::ios::binary | std::ios::out);
if (outputCsv.is_open()) {
outputCsv.write(reinterpret_cast(decodedCsv.data()), decodedCsv.size());
outputCsv.close();
std::cout << "Output time-series data saved at " << outputCsvPath << std::endl;
} else {
std::cerr << "Unable to open file for writing: " << outputCsvPath << std::endl;
}
} else {
std::cout << "Failed to send HTTP request." << std::endl;
std::cout << response->body << std::endl;
return 1;
}
return 0;
}
Java
import okhttp3.*;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.node.ObjectNode;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Base64;
public class Main {
public static void main(String[] args) throws IOException {
String API_URL = "http://localhost:8080/time-series-anomaly-detection";
String csvPath = "./test.csv";
String outputImagePath = "./out.jpg";
String outputCsvPath = "./out.csv";
// Base64 encode the local CSV file
File file = new File(csvPath);
byte[] fileContent = java.nio.file.Files.readAllBytes(file.toPath());
String csvData = Base64.getEncoder().encodeToString(fileContent);
ObjectMapper objectMapper = new ObjectMapper();
ObjectNode params = objectMapper.createObjectNode();
params.put("csv", csvData);
// Create an instance of OkHttpClient
OkHttpClient client = new OkHttpClient();
MediaType JSON = MediaType.Companion.get("application/json; charset=utf-8");
RequestBody body = RequestBody.Companion.create(params.toString(), JSON);
Request request = new Request.Builder()
.url(API_URL)
.post(body)
.build();
// Call the API and handle the response data
try (Response response = client.newCall(request).execute()) {
if (response.isSuccessful()) {
String responseBody = response.body().string();
JsonNode resultNode = objectMapper.readTree(responseBody);
JsonNode result = resultNode.get("result");
// Save the returned data
String base64Image = result.get("image").asText();
byte[] imageBytes = Base64.getDecoder().decode(base64Image);
try (FileOutputStream fos = new FileOutputStream(outputImagePath)) {
fos.write(imageBytes);
}
System.out.println("Output image data saved at " + outputImagePath);
String base64Csv = result.get("csv").asText();
byte[] csvBytes = Base64.getDecoder().decode(base64Csv);
try (FileOutputStream fos = new FileOutputStream(outputCsvPath)) {
fos.write(csvBytes);
}
System.out.println("Output time-series data saved at " + outputCsvPath);
} else {
System.err.println("Request failed with code: " + response.code());
}
}
}
}
Go
package main
import (
"bytes"
"encoding/base64"
"encoding/json"
"fmt"
"io/ioutil"
"net/http"
)
func main() {
API_URL := "http://localhost:8080/time-series-anomaly-detection"
csvPath := "./test.csv";
outputImagePath := "./out.jpg";
outputCsvPath := "./out.csv";
// Read the CSV file and encode it with Base64
csvBytes, err := ioutil.ReadFile(csvPath)
if err != nil {
fmt.Println("Error reading CSV file:", err)
return
}
csvData := base64.StdEncoding.EncodeToString(csvBytes)
payload := map[string]string{"csv": csvData} // Base64-encoded file content
payloadBytes, err := json.Marshal(payload)
if err != nil {
fmt.Println("Error marshaling payload:", err)
return
}
// Call the API
client := &http.Client{}
req, err := http.NewRequest("POST", API_URL, bytes.NewBuffer(payloadBytes))
if err != nil {
fmt.Println("Error creating request:", err)
return
}
res, err := client.Do(req)
if err != nil {
fmt.Println("Error sending request:", err)
return
}
defer res.Body.Close()
// Process the response data
body, err := ioutil.ReadAll(res.Body)
if err != nil {
fmt.Println("Error reading response body:", err)
return
}
type Response struct {
Result struct {
Csv string `json:"csv"`
Image string `json:"image"`
} `json:"result"`
}
var respData Response
err = json.Unmarshal([]byte(string(body)), &respData)
if err != nil {
fmt.Println("Error unmarshaling response body:", err)
return
}
// Decode the Base64-encoded image data and save it as a file
outputImageData, err := base64.StdEncoding.DecodeString(respData.Result.Image)
if err != nil {
fmt.Println("Error decoding Base64 image data:", err)
return
}
err = ioutil.WriteFile(outputImagePath, outputImageData, 0644)
if err != nil {
fmt.Println("Error writing image to file:", err)
return
}
fmt.Printf("Output image data saved at %s.jpg", outputImagePath)
// Decode the Base64-encoded CSV data and save it as a file
outputCsvData, err := base64.StdEncoding.DecodeString(respData.Result.Csv)
if err != nil {
fmt.Println("Error decoding Base64 CSV data:", err)
return
}
err = ioutil.WriteFile(outputCsvPath, outputCsvData, 0644)
if err != nil {
fmt.Println("Error writing CSV to file:", err)
return
}
fmt.Printf("Output time-series data saved at %s.csv", outputCsvPath)
}
C#
using System;
using System.IO;
using System.Net.Http;
using System.Net.Http.Headers;
using System.Text;
using System.Threading.Tasks;
using Newtonsoft.Json.Linq;
class Program
{
static readonly string API_URL = "http://localhost:8080/time-series-anomaly-detection";
static readonly string csvPath = "./test.csv";
static readonly string outputImagePath = "./out.jpg";
static readonly string outputCsvPath = "./out.csv";
static async Task Main(string[] args)
{
var httpClient = new HttpClient();
// Encode the local CSV file using Base64
byte[] csvBytes = File.ReadAllBytes(csvPath);
string csvData = Convert.ToBase64String(csvBytes);
var payload = new JObject{ { "csv", csvData } }; // Base64 encoded file content
var content = new StringContent(payload.ToString(), Encoding.UTF8, "application/json");
// Call the API
HttpResponseMessage response = await httpClient.PostAsync(API_URL, content);
response.EnsureSuccessStatusCode();
// Process the response data
string responseBody = await response.Content.ReadAsStringAsync();
JObject jsonResponse = JObject.Parse(responseBody);
// Save the image file
string base64Image = jsonResponse["result"]["image"].ToString();
byte[] outputImageBytes = Convert.FromBase64String(base64Image);
File.WriteAllBytes(outputImagePath, outputImageBytes);
Console.WriteLine($"Output image data saved at {outputImagePath}");
// Save the CSV file
string base64Csv = jsonResponse["result"]["csv"].ToString();
byte[] outputCsvBytes = Convert.FromBase64String(base64Csv);
File.WriteAllBytes(outputCsvPath, outputCsvBytes);
Console.WriteLine($"Output time-series data saved at {outputCsvPath}");
}
}
Node.js
const axios = require('axios');
const fs = require('fs');
const API_URL = 'http://localhost:8080/time-series-anomaly-detection';
const csvPath = "./test.csv";
const outputImagePath = "./out.jpg";
const outputCsvPath = "./out.csv";
let config = {
method: 'POST',
maxBodyLength: Infinity,
url: API_URL,
data: JSON.stringify({
'csv': encodeFileToBase64(csvPath) // Base64 encoded file content
})
};
// Read the csv file and convert it to Base64
function encodeFileToBase64(filePath) {
const bitmap = fs.readFileSync(filePath);
return Buffer.from(bitmap).toString('base64');
}
axios.request(config)
.then((response) => {
const result = response.data["result"];
// Save the image file
const imageBuffer = Buffer.from(result["image"], 'base64');
fs.writeFile(outputImagePath, imageBuffer, (err) => {
if (err) throw err;
console.log(`Output image data saved at ${outputImagePath}`);
});
// Save the csv file
const csvBuffer = Buffer.from(result["csv"], 'base64');
fs.writeFile(outputCsvPath, csvBuffer, (err) => {
if (err) throw err;
console.log(`Output time-series data saved at ${outputCsvPath}`);
});
})
.catch((error) => {
console.log(error);
});
PHP
<?php
$API_URL = "http://localhost:8080/time-series-anomaly-detection"; // Service URL
$csv_path = "./test.csv";
$output_image_path = "./out.jpg";
$output_csv_path = "./out.csv";
// Base64 encode the local CSV file
$csv_data = base64_encode(file_get_contents($csv_path));
$payload = array("csv" => $csv_data); // Base64 encoded file content
// Call the API
$ch = curl_init($API_URL);
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_POSTFIELDS, json_encode($payload));
curl_setopt($ch, CURLOPT_HTTPHEADER, array('Content-Type: application/json'));
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$response = curl_exec($ch);
curl_close($ch);
// Handle the response data
$result = json_decode($response, true)["result"];
file_put_contents($output_image_path, base64_decode($result["image"]));
echo "Output image data saved at " . $output_image_path . "\n";
file_put_contents($output_csv_path, base64_decode($result["csv"]));
echo "Output time-series data saved at " . $output_csv_path . "\n";
?>
📱 Edge Deployment: Edge deployment is a method of placing computing and data processing capabilities on the user's device itself, allowing the device to process data directly without relying on remote servers. PaddleX supports deploying models on edge devices such as Android. For detailed edge deployment procedures, please refer to the PaddleX Edge Deployment Guide. You can choose the appropriate method to deploy the model pipeline according to your needs, and then proceed with subsequent AI application integration.
4. Custom Development¶
If the default model weights provided by the general time-series anomaly detection pipeline do not meet your accuracy or speed requirements in your scenario, you can try to further fine-tune the existing model using your own specific domain or application scenario data to improve the recognition effect of the general time-series anomaly detection pipeline in your scenario.
4.1 Model Fine-Tuning¶
Since the general time-series anomaly detection pipeline includes a time-series anomaly detection module, if the effect of the model pipeline is not as expected, you need to refer to the Custom Development section in the Time Series Anomaly Detection Module Tutorial to fine-tune the time-series anomaly detection model using your private dataset.
4.2 Model Application¶
After you complete the fine-tuning training with your private dataset, you can obtain the local model weight file.
If you need to use the fine-tuned model weights, simply modify the pipeline configuration file by filling in the local path of the fine-tuned model weights in the model_dir of the pipeline configuration file:
pipeline_name: ts_anomaly_detection
SubModules:
TSAnomalyDetection:
module_name: ts_anomaly_detection
model_name: DLinear_ad
model_dir: null # Can be modified to the local path of the fine-tuned model
batch_size: 1
Then, you can load the modified pipeline configuration file by referring to the command-line method or the Python script method in the local experience.
5. Multi-Hardware Support¶
PaddleX supports a variety of mainstream hardware devices, including NVIDIA GPU, Kunlunxin XPU, Ascend NPU, and Cambricon MLU. You can seamlessly switch between different hardware devices by simply modifying the --device parameter.
For example, if you are using Ascend NPU for inference in the time-series anomaly detection pipeline, the Python command you would use is:
If you want to use the universal time-series anomaly detection pipeline on more types of hardware, please refer to the PaddleX Multi-Hardware Usage Guide.