PaddleOCR MCP 服务器¶
本项目提供轻量级的 Model Context Protocol(MCP) 服务器,旨在将 PaddleOCR 的能力集成到各种大模型应用中。
主要功能如下:¶
- 当前支持的工具
- OCR:对图像和 PDF 文件进行文本检测与识别。
- PP-StructureV3:从图像或 PDF 文件中识别和提取文本块、标题、段落、图片、表格以及其他版面元素,将输入转换为 Markdown 文档。
- 支持运行在如下工作模式
- 本地 Python 库:在本机直接运行 PaddleOCR 产线。此模式对本地环境与计算机性能有一定要求,适用于需要离线使用、对数据隐私有严格要求的场景。
- 星河社区服务:调用托管在 飞桨星河社区 的服务。此模式适合快速体验功能、快速验证方案等,也适用于零代码开发场景。
- 自托管服务:调用用户自托管的 PaddleOCR 服务。此模式具备服务化部署优势及高度灵活性,适用于需要自定义服务配置的场景,同时也适用于对数据隐私有严格要求的场景。目前暂时只支持基础服务化部署方案。
示例:¶
以下展示了使用 PaddleOCR MCP 服务器结合其他工具搭建的创意案例:
Demo 1¶
在 Claude for Desktop 中,提取图像中的手写内容,并存到笔记软件 Notion。PaddleOCR MCP 服务器从图像中提取了文字、公式等信息,并保留了文档的结构。

- 注: 除 PaddleOCR MCP 服务器外,此 demo 还使用 Notion MCP 服务器。
Demo 2¶
在 VSCode 中,根据手写思路或伪代码一键转换为可运行并符合项目代码风格规范的 Python 脚本,并将其上传到 GitHub 仓库中。PaddleOCR MCP 服务器从图像中准确提取手写代码供后续步骤使用。
- 除 PaddleOCR MCP 服务器外,此 demo 还使用 filesystem MCP 服务器。
Demo 3¶
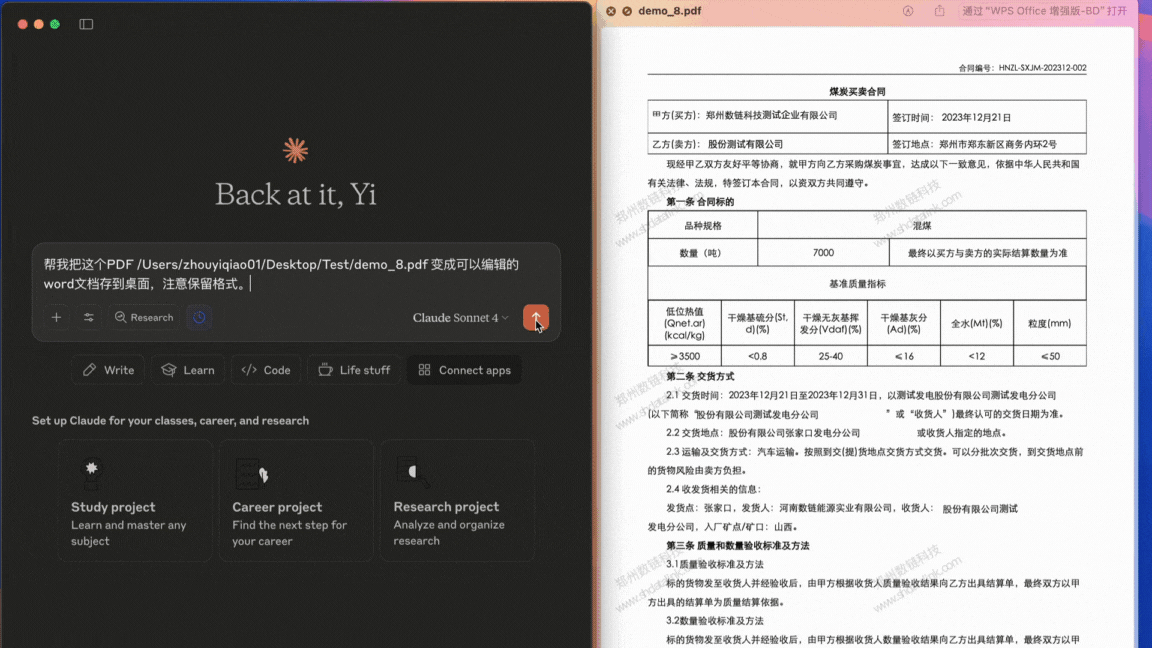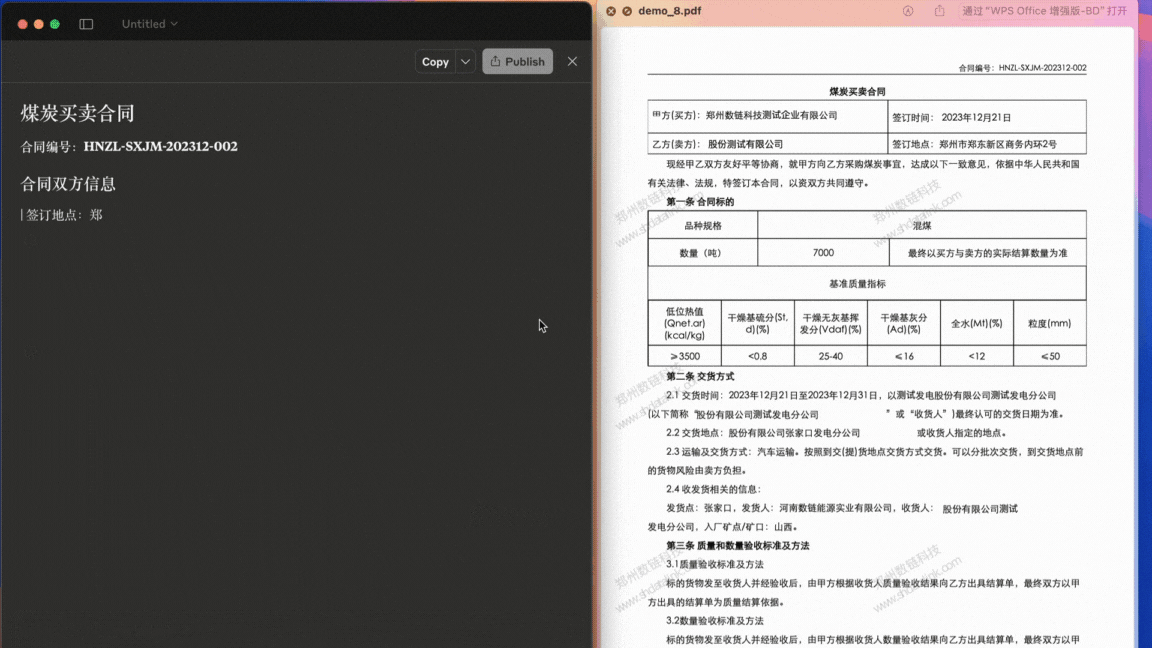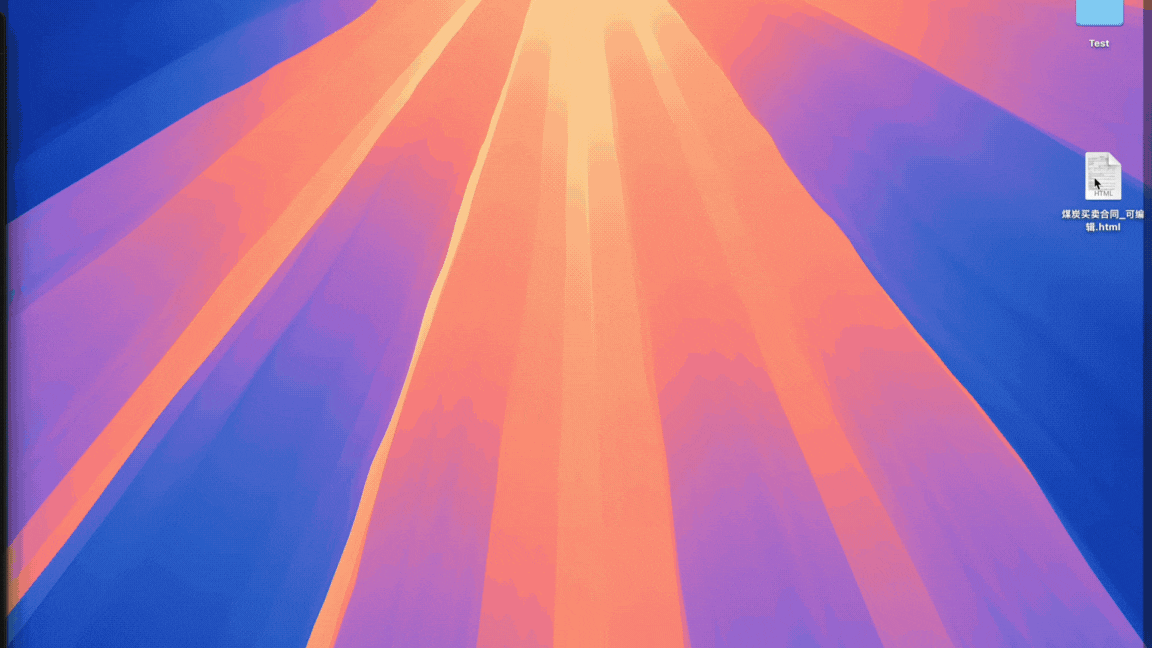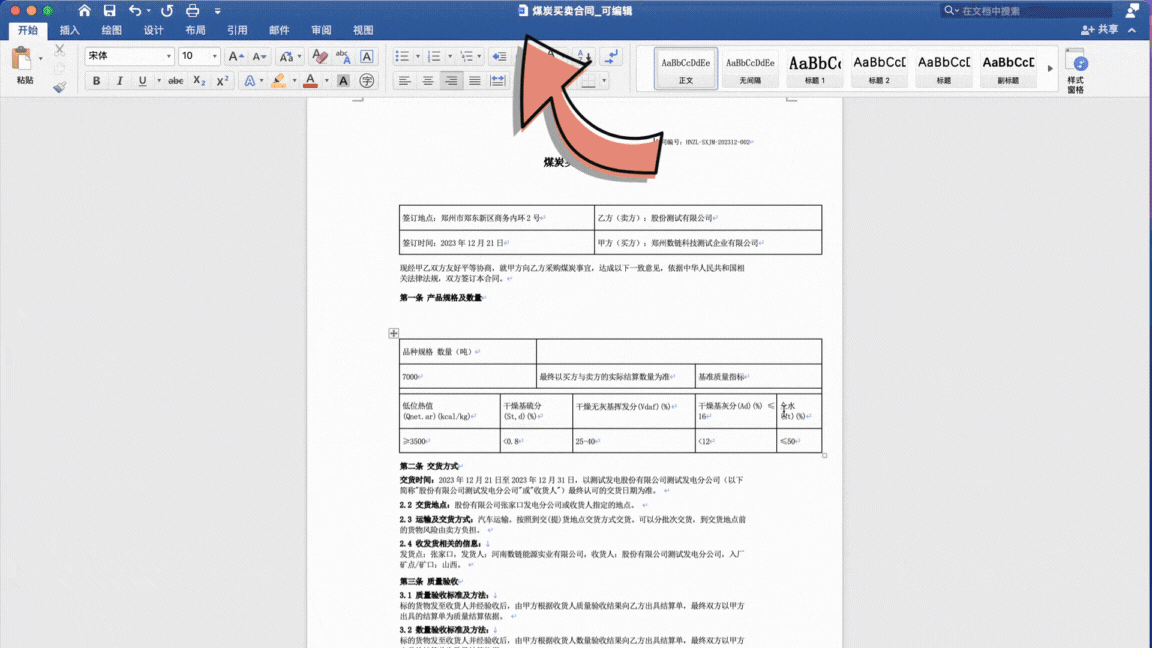
在 Claude for Desktop 中,将含有复杂表格、公式、手写文字等内容的 PDF 文档或图片转存为本地可编辑文件。
Demo 3.1¶
含表格水印复杂文档PDF 转为 doc/Word 可编辑格式:
Demo 3.2¶
含公式表格图片转为 csv/Excel 可编辑格式:
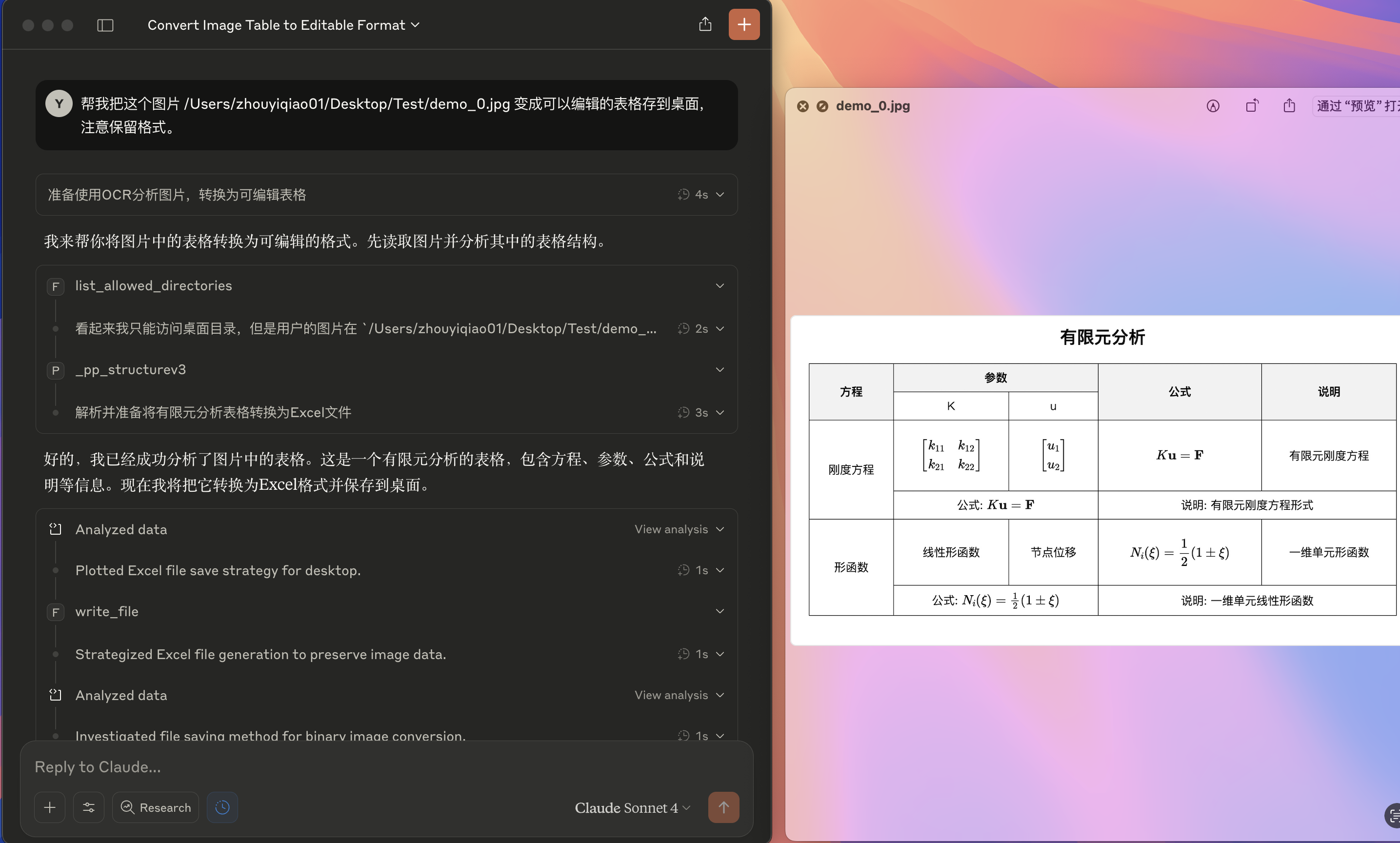
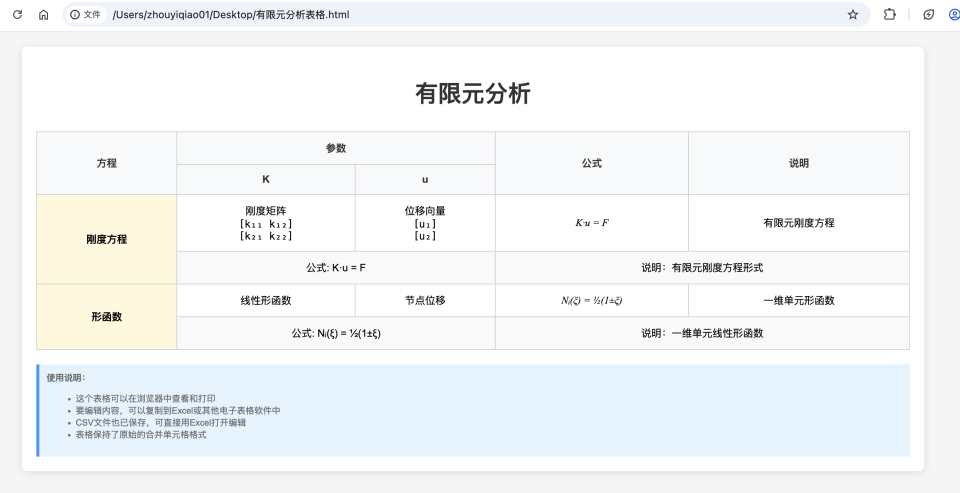
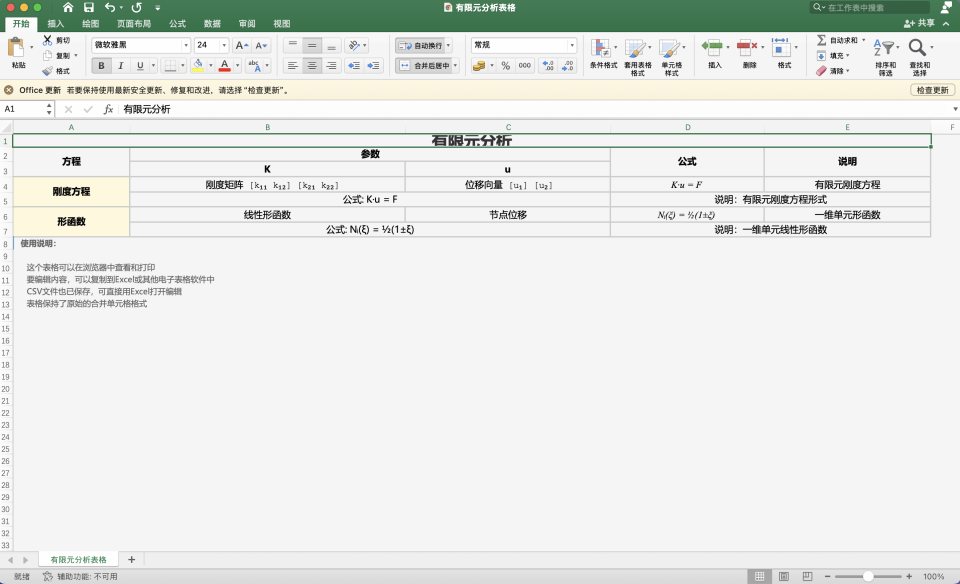
- 除 PaddleOCR MCP 服务器外,此 demo 还使用 filesystem MCP 服务器。
目录¶
1. 安装¶
本节将介绍如何通过 pip 安装 paddleocr-mcp 库。
- 对于本地 Python 库模式,除了安装
paddleocr-mcp外,还需要参考 PaddleOCR 安装文档 安装飞桨框架和 PaddleOCR。 - 对于星河社区服务和自托管服务模式,如果希望在 Claude for Desktop 等 MCP 主机中使用,也支持通过
uvx等方式免安装运行服务器。详情请参考 2. 在 Claude for Desktop 中使用 中的说明。
使用 pip 安装 paddleocr-mcp 库的命令如下:
# 安装 wheel 包
pip install https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/mcp/paddleocr_mcp/releases/v0.2.0/paddleocr_mcp-0.2.0-py3-none-any.whl
# 或者,从项目源码安装
# git clone https://github.com/PaddlePaddle/PaddleOCR.git
# pip install -e mcp_server
可通过以下命令检查是否安装成功:
如果执行上述命令后打印出了帮助信息,则说明安装成功。
2. 在 Claude for Desktop 中使用¶
本节将介绍如何在 Claude for Desktop 中使用 PaddleOCR MCP 服务器。对于其他 MCP 主机,也可参照本节的步骤,并根据实际情况进行相应调整。
2.1 快速开始¶
接下来以 星河社区服务 工作模式为例,引导您快速上手。此模式无需在本地安装复杂的依赖,因此比较适合用于快速体验。
-
安装
paddleocr-mcp请参考 1. 安装。
-
准备星河社区服务
-
添加 MCP 服务器配置
在以下位置之一找到 Claude for Desktop 配置文件:
- macOS:
~/Library/Application Support/Claude/claude_desktop_config.json - Windows:
%APPDATA%\Claude\claude_desktop_config.json - Linux:
~/.config/Claude/claude_desktop_config.json
打开
claude_desktop_config.json文件,参考如下示例调整配置,填充到claude_desktop_config.json中。{ "mcpServers": { "paddleocr-ocr": { "command": "paddleocr_mcp", "args": [], "env": { "PADDLEOCR_MCP_PIPELINE": "OCR", "PADDLEOCR_MCP_PPOCR_SOURCE": "aistudio", "PADDLEOCR_MCP_SERVER_URL": "<your-server-url>", "PADDLEOCR_MCP_AISTUDIO_ACCESS_TOKEN": "<your-access-token>" } } } }说明:
- 将
<your-server-url>替换为您的星河社区服务的基础 URL,例如https://xxxxx.aistudio-hub.baidu.com,注意不要带有端点路径(如/ocr)。 - 将
<your-access-token>替换为您的访问令牌。
注意:
- 请勿泄漏您的 访问令牌。
- 如果
paddleocr_mcp无法在系统PATH中找到,请将command设置为可执行文件的绝对路径。
- macOS:
-
重启 MCP 主机
重启 Claude for Desktop。新的
paddleocr-ocr工具现在应该可以在应用中使用了。
2.2 MCP 主机配置说明¶
在 Claude for Desktop 的配置文件中,您需要定义 MCP 服务器的启动方式。关键字段如下:
command:paddleocr_mcp(如果可执行文件可在PATH中找到)或绝对路径。args:可配置命令行参数,如["--verbose"]。详见 4. 参数说明。env:可配置环境变量。详见 4. 参数说明。
2.3 工作模式说明¶
您可以根据需求配置 MCP 服务器,使其运行在不同的工作模式。不同工作模式需要的操作流程有所不同,下面将详细介绍。
模式一:本地 Python 库¶
- 安装
paddleocr-mcp。 - 安装飞桨框架和 PaddleOCR。为避免依赖冲突,强烈建议在独立的虚拟环境中安装。
- 参考下方的配置示例更改
claude_desktop_config.json文件内容。 - 重启 MCP 主机。
配置示例:
{
"mcpServers": {
"paddleocr-ocr": {
"command": "paddleocr_mcp",
"args": [],
"env": {
"PADDLEOCR_MCP_PIPELINE": "OCR",
"PADDLEOCR_MCP_PPOCR_SOURCE": "local"
}
}
}
}
说明:
PADDLEOCR_MCP_PIPELINE_CONFIG为可选项,不设置时使用产线默认配置。如需调整配置,例如更换模型,请参考 PaddleOCR 文档 导出产线配置文件,并将PADDLEOCR_MCP_PIPELINE_CONFIG设置为配置文件的绝对路径。-
推理性能提示:
如果使用过程中出现推理耗时过长、内存不足等问题,可考虑参考如下建议调整产线配置:
- OCR 产线:建议更换
mobile系列模型。例如,您可以在产线配置文件中将检测和识别模型分别修改为PP-OCRv5_mobile_det和PP-OCRv5_mobile_rec。 -
PP-StructureV3 产线:
- 关闭不需要用到的功能,例如设置
use_formula_recognition为False以禁用公式识别。 - 使用轻量级的模型,例如将 OCR 模型替换为
mobile版本、换用轻量的公式识别模型 PP-FormulaNet-S 等。
以下示例代码可用于获取产线配置文件,其中关闭了 PP-StructureV3 产线的大部分可选功能,同时将部分关键模型更换为轻量级版本。
from paddleocr import PPStructureV3 pipeline = PPStructureV3( use_doc_orientation_classify=False, # 禁用文档图像方向分类 use_doc_unwarping=False, # 禁用文本图像矫正 use_textline_orientation=False, # 禁用文本行方向分类 use_formula_recognition=False, # 禁用公式识别 use_seal_recognition=False, # 禁用印章文本识别 use_table_recognition=False, # 禁用表格识别 use_chart_recognition=False, # 禁用图表解析 # 使用轻量级模型 text_detection_model_name="PP-OCRv5_mobile_det", text_recognition_model_name="PP-OCRv5_mobile_rec", layout_detection_model_name="PP-DocLayout-S", ) # 配置文件保存到 `PP-StructureV3.yaml` 中 pipeline.export_paddlex_config_to_yaml("PP-StructureV3.yaml") - 关闭不需要用到的功能,例如设置
- OCR 产线:建议更换
模式二:星河社区服务¶
请参考 2.1 快速开始。
除了使用平台预设的模型方案,您也可以在平台上自行训练并部署自定义模型。
模式三:自托管服务¶
- 在需要运行 PaddleOCR 推理服务器的环境中,参考 PaddleOCR 服务化部署文档 运行推理服务器。
- 在需要运行 MCP 服务器的环境中安装
paddleocr-mcp。 - 参考下方的配置示例更改
claude_desktop_config.json文件内容。 - 将您的服务地址填入
PADDLEOCR_MCP_SERVER_URL(例如:"http://127.0.0.1:8000")。 - 重启 MCP 主机。
配置示例:
{
"mcpServers": {
"paddleocr-ocr": {
"command": "paddleocr_mcp",
"args": [],
"env": {
"PADDLEOCR_MCP_PIPELINE": "OCR",
"PADDLEOCR_MCP_PPOCR_SOURCE": "self_hosted",
"PADDLEOCR_MCP_SERVER_URL": "<your-server-url>"
}
}
}
}
说明:
- 将
<your-server-url>替换为底层服务的基础 URL(如:http://127.0.0.1:8000)。
2.4 使用 uvx¶
对于星河社区服务和自托管服务模式,目前也支持通过 uvx 启动 MCP 服务器。这种方式不需要手动安装 paddleocr-mcp。主要步骤如下:
- 安装 uv。
-
修改
claude_desktop_config.json文件的内容。以自托管服务模式为例:{ "mcpServers": { "paddleocr-ocr": { "command": "uvx", "args": [ "--from", "paddleocr-mcp@https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/mcp/paddleocr_mcp/releases/v0.2.0/paddleocr_mcp-0.2.0-py3-none-any.whl", "paddleocr_mcp" ], "env": { "PADDLEOCR_MCP_PIPELINE": "OCR", "PADDLEOCR_MCP_PPOCR_SOURCE": "self_hosted", "PADDLEOCR_MCP_SERVER_URL": "<your-server-url>" } } } }由于使用了不一样的启动方式,配置文件中
command和args的设置都与 2.1 快速开始 介绍的方式存在显著不同,但 MCP 服务本身支持的命令行参数与环境变量(如PADDLEOCR_MCP_SERVER_URL)仍然可以以相同的方式设置。
3. 运行服务器¶
除了在 Claude for Desktop 等 MCP 主机中使用外,您也可以通过 CLI 运行 PaddleOCR MCP 服务器。
执行以下命令可以打印帮助信息:
示例命令如下:
# OCR + 星河社区服务 + stdio
PADDLEOCR_MCP_AISTUDIO_ACCESS_TOKEN=xxxxxx paddleocr_mcp --pipeline OCR --ppocr_source aistudio --server_url https://xxxxxx.aistudio-hub.baidu.com
# PP-StructureV3 + 本地 Python 库 + stdio
paddleocr_mcp --pipeline PP-StructureV3 --ppocr_source local
# OCR + 本地服务 + Streamable HTTP
paddleocr_mcp --pipeline OCR --ppocr_source self_hosted --server_url http://127.0.0.1:8080 --http
在 4. 参数说明 中可以了解 PaddleOCR MCP 服务器支持的全部参数。
4. 参数说明¶
您可以通过环境变量或命令行参数来控制 MCP 服务器的行为。
| 环境变量 | 命令行参数 | 类型 | 描述 | 可选值 | 默认值 |
|---|---|---|---|---|---|
PADDLEOCR_MCP_PIPELINE |
--pipeline |
str |
要运行的产线。 | "OCR","PP-StructureV3" |
"OCR" |
PADDLEOCR_MCP_PPOCR_SOURCE |
--ppocr_source |
str |
PaddleOCR 能力来源。 | "local"(本地 Python 库),"aistudio"(星河社区服务),"self_hosted"(自托管服务) |
"local" |
PADDLEOCR_MCP_SERVER_URL |
--server_url |
str |
底层服务基础 URL(aistudio 或 self_hosted 模式下必需)。 |
- | None |
PADDLEOCR_MCP_AISTUDIO_ACCESS_TOKEN |
--aistudio_access_token |
str |
AI Studio 访问令牌(aistudio 模式下必需)。 |
- | None |
PADDLEOCR_MCP_TIMEOUT |
--timeout |
int |
底层服务请求的读取超时时间(秒)。 | - | 60 |
PADDLEOCR_MCP_DEVICE |
--device |
str |
指定运行推理的设备(仅在 local 模式下生效)。 |
- | None |
PADDLEOCR_MCP_PIPELINE_CONFIG |
--pipeline_config |
str |
PaddleOCR 产线配置文件路径(仅在 local 模式下生效)。 |
- | None |
| - | --http |
bool |
使用 Streamable HTTP 传输而非 stdio(适用于远程部署和多客户端)。 | - | False |
| - | --host |
str |
Streamable HTTP 模式的主机地址。 | - | "127.0.0.1" |
| - | --port |
int |
Streamable HTTP 模式的端口。 | - | 8000 |
| - | --verbose |
bool |
启用详细日志记录,便于调试。 | - | False |
5. 已知局限性¶
- 在本地 Python 库模式下,当前提供的工具无法处理 Base64 编码的 PDF 文档输入。
- 在本地 Python 库模式下,当前提供的工具不会根据模型提示的
file_type推断文件类型,对于一些复杂 URL 可能处理失败。 - 对于 PP-StructureV3 产线,若输入文件中包含图像,返回结果可能会显著增加 token 使用量。若无需图像内容,可通过提示词明确排除,以降低资源消耗。