PaddleOCR MCP Server¶
This project provides a lightweight Model Context Protocol (MCP) server designed to integrate PaddleOCR capabilities into various LLM applications.
Key Features¶
- Currently Supported Tools
- OCR: Performs text detection and recognition on images and PDF files.
- PP-StructureV3: Identifies and extracts text blocks, titles, paragraphs, images, tables, and other layout elements from images or PDF files, converting the input into Markdown documents.
- Supported Working Modes
- Local Python Library: Runs PaddleOCR pipelines directly on the local machine. This mode requires a suitable local environment and hardware, and is ideal for offline use or privacy-sensitive scenarios.
- AI Studio Community Service: Invokes services hosted on the PaddlePaddle AI Studio Community. This is suitable for quick testing, prototyping, or no-code scenarios.
- Self-hosted Service: Invokes the user's self-hosted PaddleOCR services. This mode offers the advantages of serving and high flexibility. It is suitable for scenarios requiring customized service configurations, as well as those with strict data privacy requirements. Currently, only the basic serving solution is supported.
Examples:¶
The following showcases creative use cases built with PaddleOCR MCP server combined with other tools:
Demo 1¶
In Claude for Desktop, extract handwritten content from images and save to note-taking software Notion. The PaddleOCR MCP server extracts text, formulas and other information from images while preserving document structure.

- Note: In addition to the PaddleOCR MCP server, this demo also uses the Notion MCP server.
Demo 2¶
In VSCode, convert handwritten ideas or pseudocode into runnable Python scripts that comply with project coding standards with one click, and upload them to GitHub repositories. The PaddleOCR MCP server extracts explicitly handwritten code from images for subsequent processing.
- In addition to the PaddleOCR MCP server, this demo also uses the filesystem MCP server.
Demo 3¶
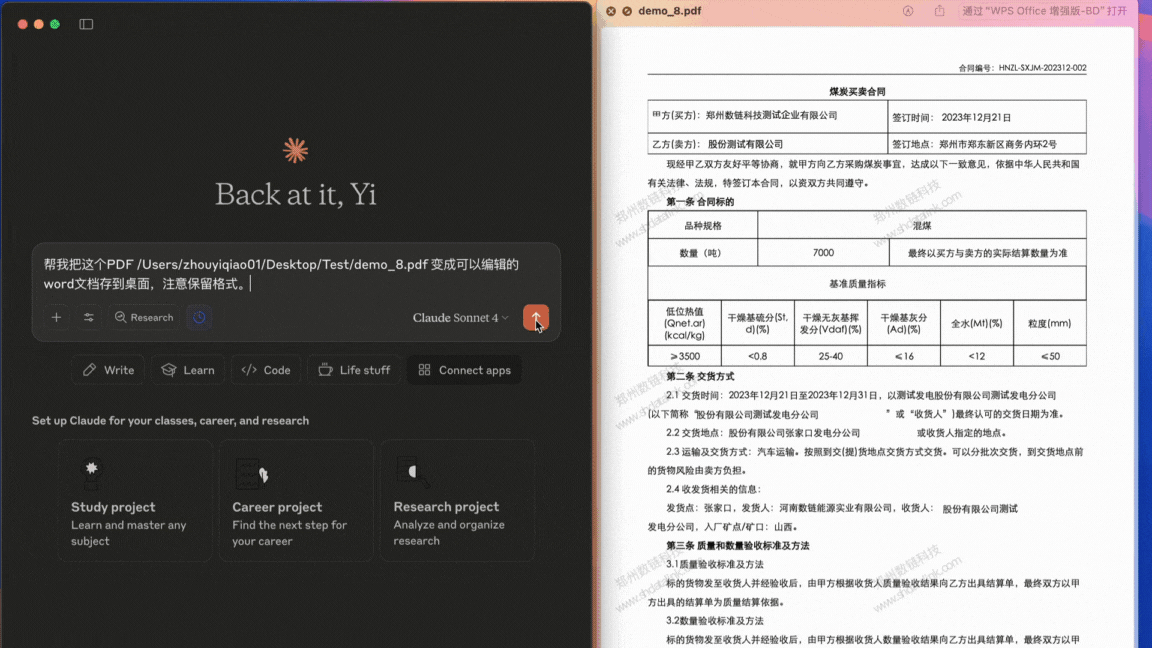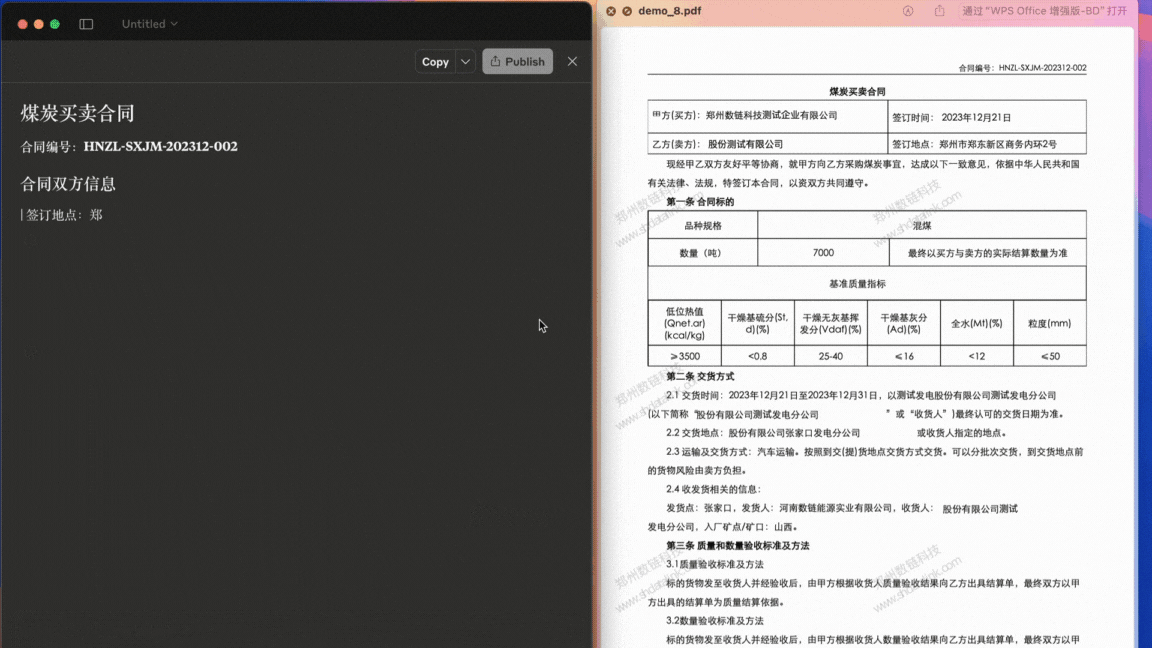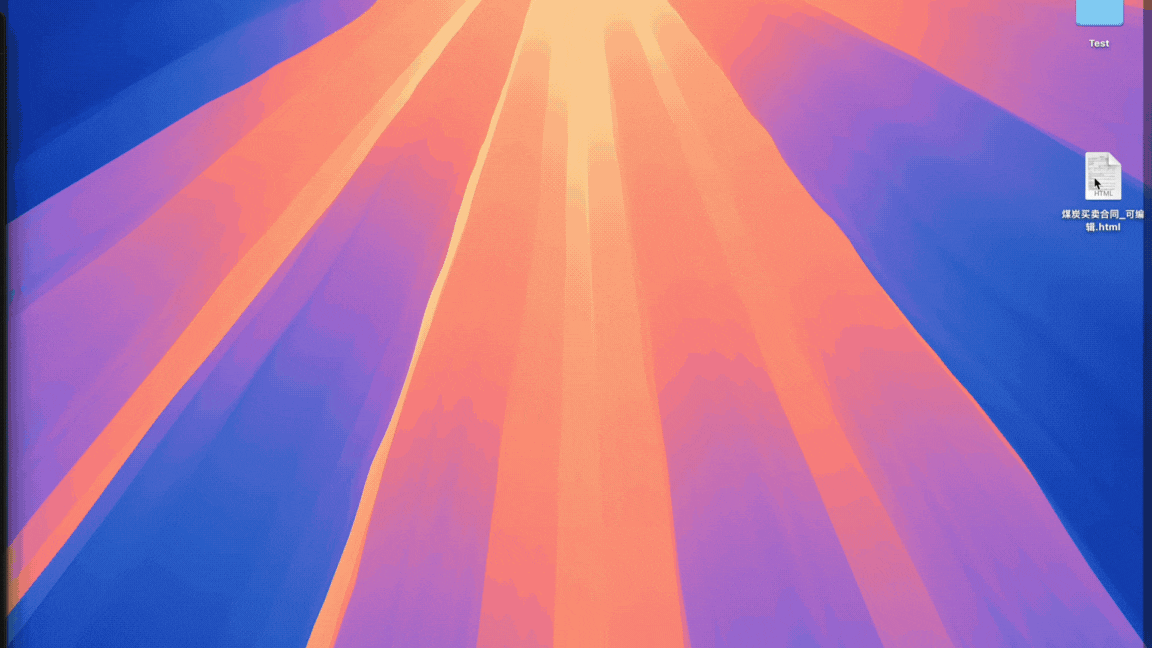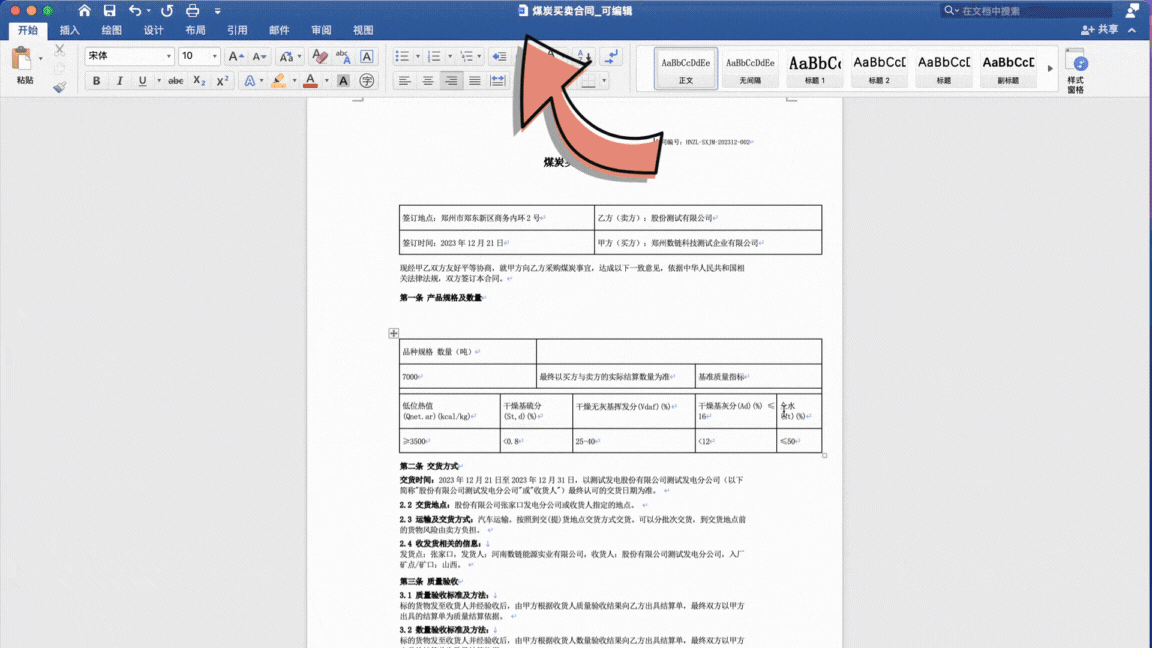
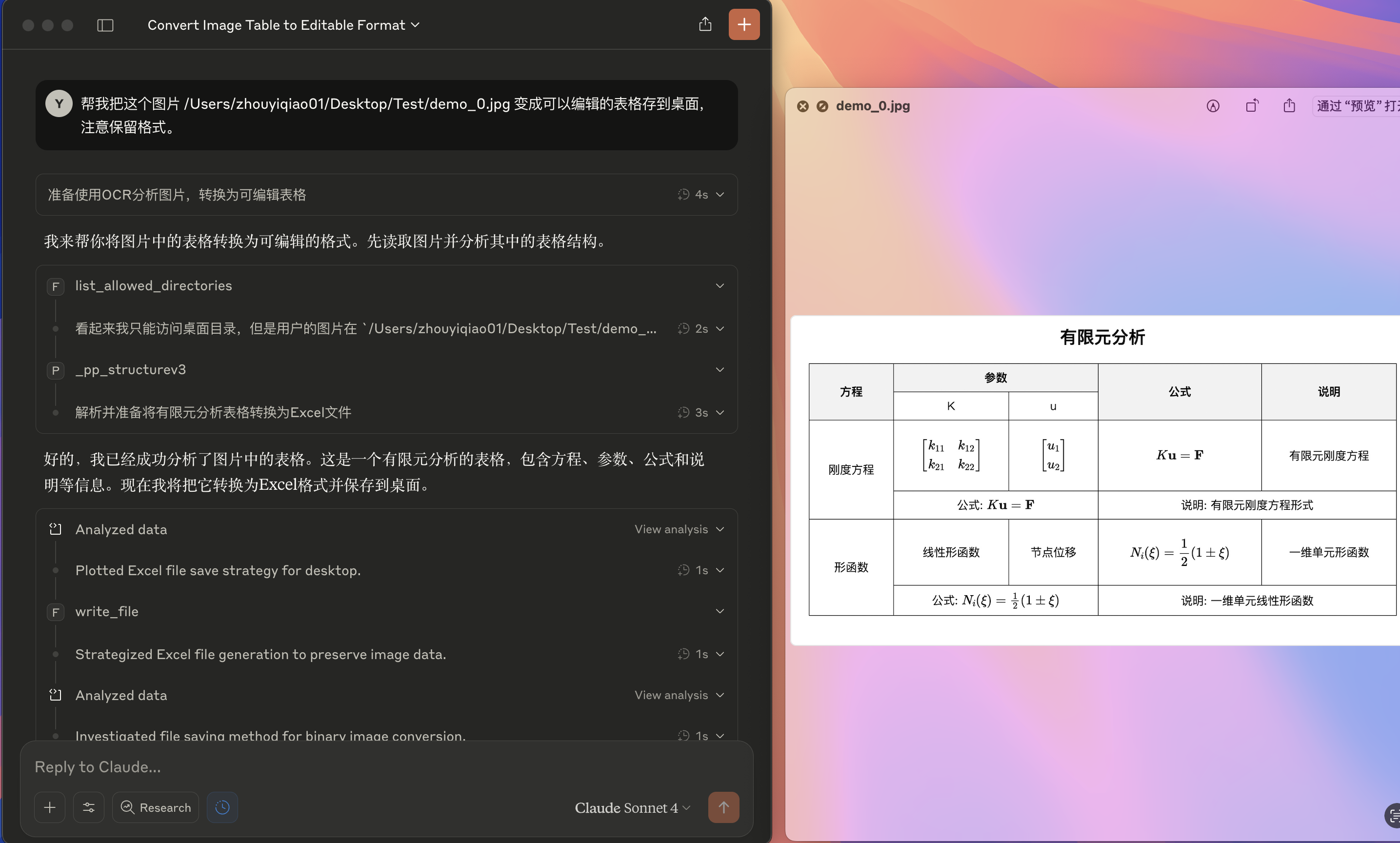
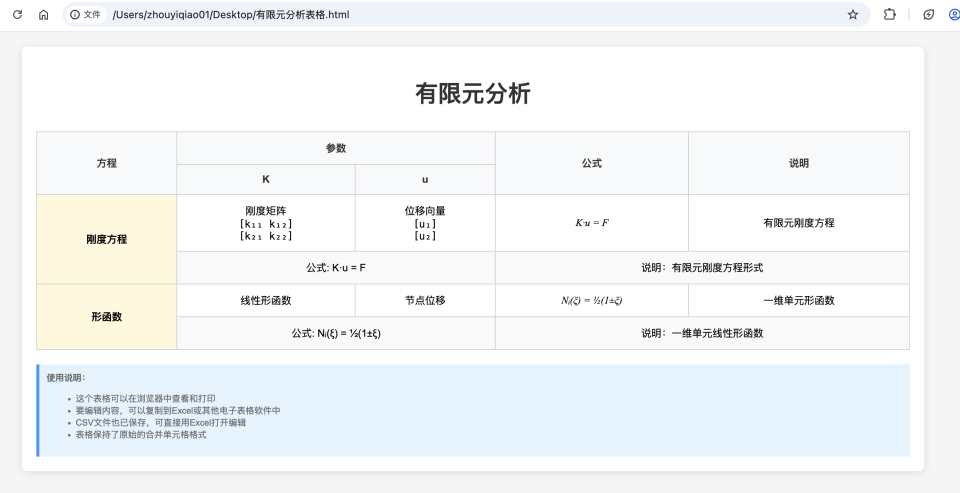
In Claude for Desktop, convert PDF documents or images containing complex tables, formulas, handwritten text and other content into locally editable files.
Demo 3.1¶
Convert complex PDF documents with tables and watermarks to editable doc/Word format:
Demo 3.2¶
Convert images containing formulas and tables to editable csv/Excel format:
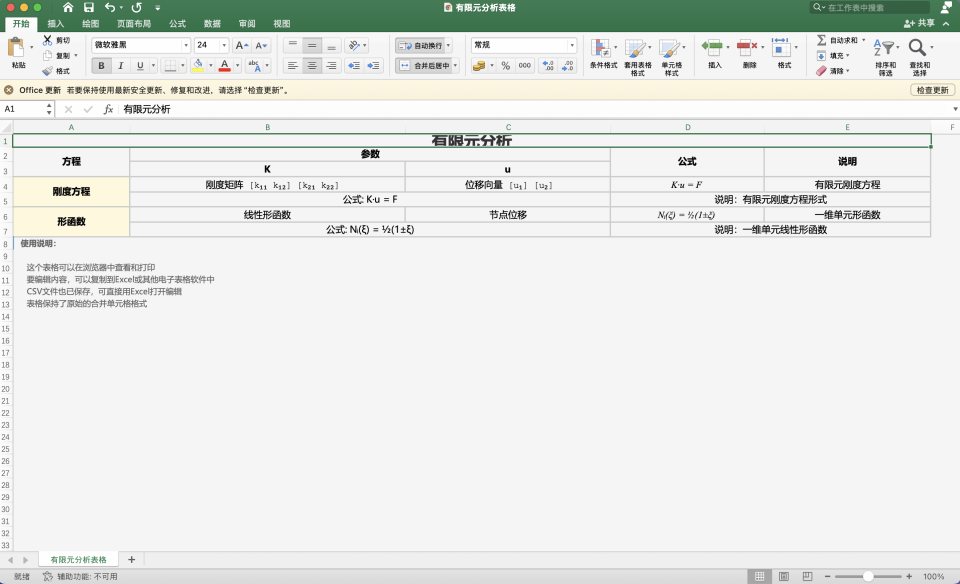
- In addition to the PaddleOCR MCP server, this demo also uses the filesystem MCP server.
Table of Contents¶
- Table of Contents
- 1. Installation
- 2. Using with Claude for Desktop
- 3. Running the Server
- 4. Parameter Reference
- 5. Known Limitations
1. Installation¶
This section explains how to install the paddleocr-mcp library via pip.
- For the local Python library mode, you need to install both
paddleocr-mcpand the PaddlePaddle framework along with PaddleOCR, as per the PaddleOCR installation documentation. - For the AI Studio community service or the self-hosted service modes, if used within MCP hosts like Claude for Desktop, the server can also be run without installation via tools like
uvx. See 2. Using with Claude for Desktop for details.
To install paddleocr-mcp using pip:
# Install the wheel
pip install https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/mcp/paddleocr_mcp/releases/v0.2.0/paddleocr_mcp-0.2.0-py3-none-any.whl
# Or install from source
# git clone https://github.com/PaddlePaddle/PaddleOCR.git
# pip install -e mcp_server
To verify successful installation:
If the help message is printed, the installation succeeded.
2. Using with Claude for Desktop¶
This section explains how to use the PaddleOCR MCP server within Claude for Desktop. The steps are also applicable to other MCP hosts with minor adjustments.
2.1 Quick Start¶
-
Install
paddleocr-mcpRefer to 1. Installation. To avoid dependency conflicts, it is strongly recommended to install in an isolated virtual environment.
-
Install PaddleOCR
Install the PaddlePaddle framework and PaddleOCR, as per the PaddleOCR installation documentation.
-
Add MCP Server Configuration
Locate the
claude_desktop_config.jsonconfiguration file:- macOS:
~/Library/Application Support/Claude/claude_desktop_config.json - Windows:
%APPDATA%\Claude\claude_desktop_config.json - Linux:
~/.config/Claude/claude_desktop_config.json
Edit the file as follows:
{ "mcpServers": { "paddleocr-ocr": { "command": "paddleocr_mcp", "args": [], "env": { "PADDLEOCR_MCP_PIPELINE": "OCR", "PADDLEOCR_MCP_PPOCR_SOURCE": "local" } } } }Notes:
-
PADDLEOCR_MCP_PIPELINE_CONFIGis optional; if not set, the default pipeline configuration will be used. If you need to adjust the configuration, such as changing the model, please refer to the PaddleOCR documentation to export the pipeline configuration file, and setPADDLEOCR_MCP_PIPELINE_CONFIGto the absolute path of this configuration file. -
Inference Performance Tips:
If you encounter issues such as long inference time or insufficient memory during use, you may consider adjusting the pipeline configuration according to the following recommendations.
-
OCR Pipeline: It is recommended to switch to the
mobileseries models. For example, you can modify the pipeline configuration file to usePP-OCRv5_mobile_detfor detection andPP-OCRv5_mobile_recfor recognition. -
PP-StructureV3 Pipeline:
- Disable unused features, e.g., set
use_formula_recognitiontoFalseto disable formula recognition. - Use lightweight models, such as replacing the OCR model with the
mobileversion or switching to a lightweight formula recognition model like PP-FormulaNet-S.
The following sample code can be used to obtain the pipeline configuration file, in which most optional features of the PP-StructureV3 pipeline are disabled, and some key models are replaced with lightweight versions.
from paddleocr import PPStructureV3 pipeline = PPStructureV3( use_doc_orientation_classify=False, # Disable document image orientation classification use_doc_unwarping=False, # Disable text image unwarping use_textline_orientation=False, # Disable text line orientation classification use_formula_recognition=False, # Disable formula recognition use_seal_recognition=False, # Disable seal text recognition use_table_recognition=False, # Disable table recognition use_chart_recognition=False, # Disable chart parsing # Use lightweight models text_detection_model_name="PP-OCRv5_mobile_det", text_recognition_model_name="PP-OCRv5_mobile_rec", layout_detection_model_name="PP-DocLayout-S", ) # The configuration file is saved to `PP-StructureV3.yaml` pipeline.export_paddlex_config_to_yaml("PP-StructureV3.yaml") - Disable unused features, e.g., set
-
Important:
- If
paddleocr_mcpis not in your system'sPATH, setcommandto the absolute path of the executable.
- macOS:
-
Restart the MCP Host
Restart Claude for Desktop. The
paddleocr-ocrtool should now be available in the application.
2.2 MCP Host Configuration Details¶
In the configuration file for Claude for Desktop, you need to define how the MCP server is started. The key fields are as follows:
command:paddleocr_mcp(if the executable can be found in thePATH) or the absolute path.args: Configurable command-line arguments, such as["--verbose"]. See 4. Parameter Reference for details.env: Configurable environment variables. See 4. Parameter Reference for details.
2.3 Working Modes Explained¶
You can configure the MCP server according to your requirements to run in different working modes. The operational procedures vary for different modes, which will be explained in detail below.
Mode 1: Local Python Library¶
See 2.1 Quick Start.
Mode 2: AI Studio Community Service¶
- Install
paddleocr-mcp. - Set up AI Studio community service.
- Visit PaddlePaddle AI Studio Community and log in.
- Under "PaddleX Pipeline" in the "More" section on the left, click in sequence: [Create Pipeline] - [OCR] - [General OCR] - [Deploy Directly] - [Start Deployment].
- After deployment, obtain your service base URL (e.g.,
https://xxxxxx.aistudio-hub.baidu.com). - Get your access token from this page.
- Refer to the configuration example below to modify the contents of the
claude_desktop_config.jsonfile. - Restart the MCP host.
Configuration example:
{
"mcpServers": {
"paddleocr-ocr": {
"command": "paddleocr_mcp",
"args": [],
"env": {
"PADDLEOCR_MCP_PIPELINE": "OCR",
"PADDLEOCR_MCP_PPOCR_SOURCE": "aistudio",
"PADDLEOCR_MCP_SERVER_URL": "<your-server-url>",
"PADDLEOCR_MCP_AISTUDIO_ACCESS_TOKEN": "<your-access-token>"
}
}
}
}
Notes:
- Replace
<your-server-url>with your AI Studio service base URL, e.g.,https://xxxxx.aistudio-hub.baidu.com. Make sure not to include the endpoint path (such as/ocr). - Replace
<your-access-token>with your access token.
Important:
- Do not expose your access token.
You may also train and deploy custom models on the platform.
Mode 3: Self-hosted Service¶
- In the environment where you need to run the PaddleOCR inference server, run the inference server as per the PaddleOCR serving documentation.
- Install
paddleocr-mcpwhere the MCP server will run. - Refer to the configuration example below to modify the contents of the
claude_desktop_config.jsonfile. - Set
PADDLEOCR_MCP_SERVER_URL(e.g.,"http://127.0.0.1:8000"). - Restart the MCP host.
Configuration example:
{
"mcpServers": {
"paddleocr-ocr": {
"command": "paddleocr_mcp",
"args": [],
"env": {
"PADDLEOCR_MCP_PIPELINE": "OCR",
"PADDLEOCR_MCP_PPOCR_SOURCE": "self_hosted",
"PADDLEOCR_MCP_SERVER_URL": "<your-server-url>"
}
}
}
}
Note:
- Replace
<your-server-url>with your service’s base URL (e.g.,http://127.0.0.1:8000).
2.4 Using uvx¶
Currently, for both the AI Studio and self-hosted modes, starting the MCP server via uvx is also supported. With this approach, manual installation of paddleocr-mcp is not required. The main steps are as follows:
- Install uv.
-
Modify
claude_desktop_config.json. Example for self-hosted mode:{ "mcpServers": { "paddleocr-ocr": { "command": "uvx", "args": [ "--from", "paddleocr-mcp@https://paddle-model-ecology.bj.bcebos.com/paddlex/PaddleX3.0/mcp/paddleocr_mcp/releases/v0.2.0/paddleocr_mcp-0.2.0-py3-none-any.whl", "paddleocr_mcp" ], "env": { "PADDLEOCR_MCP_PIPELINE": "OCR", "PADDLEOCR_MCP_PPOCR_SOURCE": "self_hosted", "PADDLEOCR_MCP_SERVER_URL": "<your-server-url>" } } } }Due to the different startup methods used, the settings for
commandandargsin the configuration file differ significantly from those described in 2.1 Quick Start. However, the command-line arguments and environment variables (such asPADDLEOCR_MCP_SERVER_URL) supported by the MCP service itself can still be set in the same way.
3. Running the Server¶
In addition to MCP hosts like Claude for Desktop, you can also run the PaddleOCR MCP server via the CLI.
To view help:
Example commands:
# OCR + AI Studio community service + stdio
PADDLEOCR_MCP_AISTUDIO_ACCESS_TOKEN=xxxxxx paddleocr_mcp --pipeline OCR --ppocr_source aistudio --server_url https://xxxxxx.aistudio-hub.baidu.com
# PP-StructureV3 + local Python library + stdio
paddleocr_mcp --pipeline PP-StructureV3 --ppocr_source local
# OCR + self-hosted service + Streamable HTTP
paddleocr_mcp --pipeline OCR --ppocr_source self_hosted --server_url http://127.0.0.1:8080 --http
You can find all the supported parameters of the PaddleOCR MCP server in 4. Parameter Reference.
4. Parameter Reference¶
You can control the MCP server via environment variables or CLI arguments.
| Environment Variable | CLI Argument | Type | Description | Options | Default |
|---|---|---|---|---|---|
PADDLEOCR_MCP_PIPELINE |
--pipeline |
str |
Pipeline to run. | "OCR", "PP-StructureV3" |
"OCR" |
PADDLEOCR_MCP_PPOCR_SOURCE |
--ppocr_source |
str |
Source of PaddleOCR capabilities. | "local" (local Python library), "aistudio" (AI Studio community service), "self_hosted" (self-hosted service) |
"local" |
PADDLEOCR_MCP_SERVER_URL |
--server_url |
str |
Base URL for the underlying service (aistudio or self_hosted mode only). |
- | None |
PADDLEOCR_MCP_AISTUDIO_ACCESS_TOKEN |
--aistudio_access_token |
str |
AI Studio access token (aistudio mode only). |
- | None |
PADDLEOCR_MCP_TIMEOUT |
--timeout |
int |
Read timeout for the underlying requests (seconds). | - | 60 |
PADDLEOCR_MCP_DEVICE |
--device |
str |
Device for inference (local mode only). |
- | None |
PADDLEOCR_MCP_PIPELINE_CONFIG |
--pipeline_config |
str |
Path to pipeline config file (local mode only). |
- | None |
| - | --http |
bool |
Use Streamable HTTP instead of stdio (for remote/multi-client use). | - | False |
| - | --host |
str |
Host for the Stremable HTTP mode. | - | "127.0.0.1" |
| - | --port |
int |
Port for the Streamable HTTP mode. | - | 8000 |
| - | --verbose |
bool |
Enable verbose logging for debugging. | - | False |
5. Known Limitations¶
- In the local Python library mode, the current tools cannot process PDF document inputs that are Base64 encoded.
- In the local Python library mode, the current tools do not infer the file type based on the model's
file_typeprompt, and may fail to process some complex URLs. - For the PP-StructureV3 pipeline, if the input file contains images, the returned results may significantly increase token usage. If image content is not needed, you can explicitly exclude it through prompts to reduce resource consumption.