版面区域检测模块使用教程¶
一、概述¶
版面区域检测任务的核心是对输入的文档图像进行内容解析和区域划分。通过识别图像中的不同元素(如文字、图表、图像、公式、段落、摘要、参考文献等),将其归类为预定义的类别,并确定这些区域在文档中的位置。
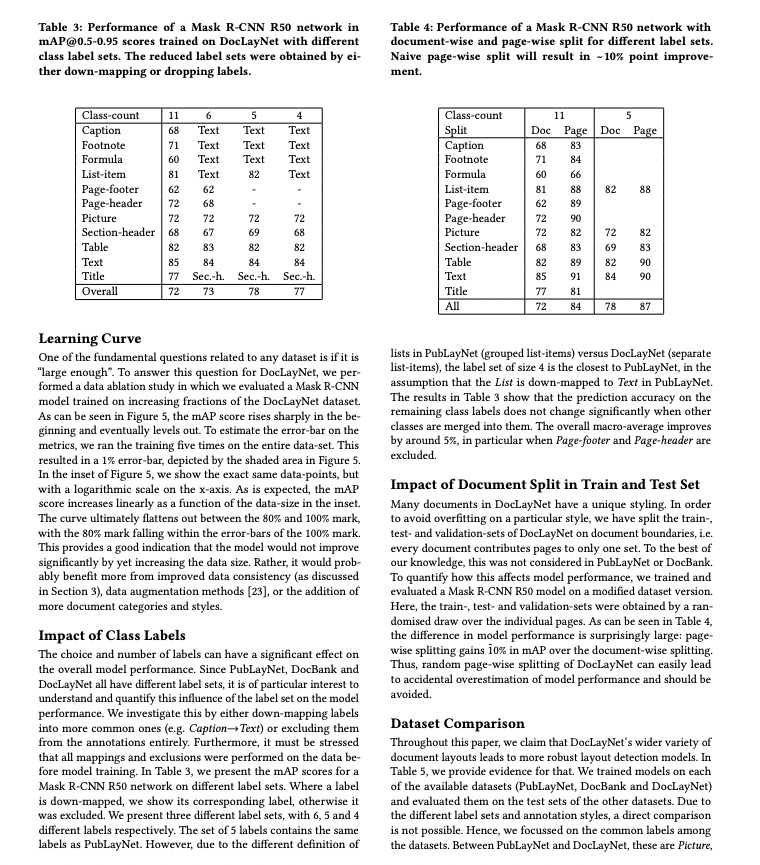
二、支持模型列表¶
- 版面检测模型,包含20个常见的类别:文档标题、段落标题、文本、页码、摘要、目录、参考文献、脚注、页眉、页脚、算法、公式、公式编号、图像、表格、图和表标题(图标题、表格标题和图表标题)、印章、图表、侧栏文本和参考文献内容
| 模型 | 模型下载链接 | mAP(0.5)(%) | GPU推理耗时(ms) [常规模式 / 高性能模式] |
CPU推理耗时(ms) [常规模式 / 高性能模式] |
模型存储大小(MB) | 介绍 |
|---|---|---|---|---|---|---|
| PP-DocLayout_plus-L | 推理模型/训练模型 | 83.2 | 53.03 / 17.23 | 634.62 / 378.32 | 126.01 | 基于RT-DETR-L在包含中英文论文、多栏杂志、报纸、PPT、合同、书本、试卷、研报、古籍、日文文档、竖版文字文档等场景的自建数据集训练的更高精度版面区域定位模型 |
注:以上精度指标的评估集是自建的版面区域检测数据集,包含中英文论文、杂志、报纸、研报、PPT、试卷、课本等 1300 张文档类型图片。
- 文档图像版面子模块检测,包含1个 版面区域 类别,能检测多栏的报纸、杂志的每个子文章的文本区域:
| 模型 | 模型下载链接 | mAP(0.5)(%) | GPU推理耗时(ms) [常规模式 / 高性能模式] |
CPU推理耗时(ms) [常规模式 / 高性能模式] |
模型存储大小(MB) | 介绍 |
|---|---|---|---|---|---|---|
| PP-DocBlockLayout | 推理模型/训练模型 | 95.9 | 34.60 / 28.54 | 506.43 / 256.83 | 123.92 | 基于RT-DETR-L在包含中英文论文、多栏杂志、报纸、PPT、合同、书本、试卷、研报、古籍、日文文档、竖版文字文档等场景的自建数据集训练的文档图像版面子模块检测模型 |
注:以上精度指标的评估集是自建的版面子区域检测数据集,包含中英文论文、杂志、报纸、研报、PPT、试卷、课本等 1000 张文档类型图片。
- 版面检测模型,包含23个常见的类别:文档标题、段落标题、文本、页码、摘要、目录、参考文献、脚注、页眉、页脚、算法、公式、公式编号、图像、图表标题、表格、表格标题、印章、图表标题、图表、页眉图像、页脚图像、侧栏文本
| 模型 | 模型下载链接 | mAP(0.5)(%) | GPU推理耗时(ms) [常规模式 / 高性能模式] |
CPU推理耗时(ms) [常规模式 / 高性能模式] |
模型存储大小(MB) | 介绍 |
|---|---|---|---|---|---|---|
| PP-DocLayout-L | 推理模型/训练模型 | 90.4 | 33.59 / 33.59 | 503.01 / 251.08 | 123.76 | 基于RT-DETR-L在包含中英文论文、杂志、合同、书本、试卷和研报等场景的自建数据集训练的高精度版面区域定位模型 |
| PP-DocLayout-M | 推理模型/训练模型 | 75.2 | 13.03 / 4.72 | 43.39 / 24.44 | 22.578 | 基于PicoDet-L在包含中英文论文、杂志、合同、书本、试卷和研报等场景的自建数据集训练的精度效率平衡的版面区域定位模型 |
| PP-DocLayout-S | 推理模型/训练模型 | 70.9 | 11.54 / 3.86 | 18.53 / 6.29 | 4.834 | 基于PicoDet-S在中英文论文、杂志、合同、书本、试卷和研报等场景上自建数据集训练的高效率版面区域定位模型 |
注:以上精度指标的评估集是自建的版面区域检测数据集,包含中英文论文、报纸、研报和试卷等 500 张文档类型图片。
❗ 以上列出的是版面检测模块重点支持的5个核心模型,该模块总共支持13个全量模型,包含多个预定义了不同类别的模型,完整的模型列表如下:
👉模型列表详情
* 表格版面检测模型| 模型 | 模型下载链接 | mAP(0.5)(%) | GPU推理耗时(ms) [常规模式 / 高性能模式] |
CPU推理耗时(ms) [常规模式 / 高性能模式] |
模型存储大小(MB) | 介绍 |
|---|---|---|---|---|---|---|
| PicoDet_layout_1x_table | 推理模型/训练模型 | 97.5 | 9.57 / 6.63 | 27.66 / 16.75 | 7.4 | 基于PicoDet-1x在自建数据集训练的高效率版面区域定位模型,可定位表格这1类区域 |
| 模型 | 模型下载链接 | mAP(0.5)(%) | GPU推理耗时(ms) [常规模式 / 高性能模式] |
CPU推理耗时(ms) [常规模式 / 高性能模式] |
模型存储大小(MB) | 介绍 |
|---|---|---|---|---|---|---|
| PicoDet-S_layout_3cls | 推理模型/训练模型 | 88.2 | 8.43 / 3.44 | 17.60 / 6.51 | 4.8 | 基于PicoDet-S轻量模型在中英文论文、杂志和研报等场景上自建数据集训练的高效率版面区域定位模型 |
| PicoDet-L_layout_3cls | 推理模型/训练模型 | 89.0 | 12.80 / 9.57 | 45.04 / 23.86 | 22.6 | 基于PicoDet-L在中英文论文、杂志和研报等场景上自建数据集训练的效率精度均衡版面区域定位模型 |
| RT-DETR-H_layout_3cls | 推理模型/训练模型 | 95.8 | 114.80 / 25.65 | 924.38 / 924.38 | 470.1 | 基于RT-DETR-H在中英文论文、杂志和研报等场景上自建数据集训练的高精度版面区域定位模型 |
| 模型 | 模型下载链接 | mAP(0.5)(%) | GPU推理耗时(ms) [常规模式 / 高性能模式] |
CPU推理耗时(ms) [常规模式 / 高性能模式] |
模型存储大小(MB) | 介绍 |
|---|---|---|---|---|---|---|
| PicoDet_layout_1x | 推理模型/训练模型 | 97.8 | 9.62 / 6.75 | 26.96 / 12.77 | 7.4 | 基于PicoDet-1x在PubLayNet数据集训练的高效率英文文档版面区域定位模型 |
| 模型 | 模型下载链接 | mAP(0.5)(%) | GPU推理耗时(ms) [常规模式 / 高性能模式] |
CPU推理耗时(ms) [常规模式 / 高性能模式] |
模型存储大小(MB) | 介绍 |
|---|---|---|---|---|---|---|
| PicoDet-S_layout_17cls | 推理模型/训练模型 | 87.4 | 8.80 / 3.62 | 17.51 / 6.35 | 4.8 | 基于PicoDet-S轻量模型在中英文论文、杂志和研报等场景上自建数据集训练的高效率版面区域定位模型 |
| PicoDet-L_layout_17cls | 推理模型/训练模型 | 89.0 | 12.60 / 10.27 | 43.70 / 24.42 | 22.6 | 基于PicoDet-L在中英文论文、杂志和研报等场景上自建数据集训练的效率精度均衡版面区域定位模型 |
| RT-DETR-H_layout_17cls | 推理模型/训练模型 | 98.3 | 115.29 / 101.18 | 964.75 / 964.75 | 470.2 | 基于RT-DETR-H在中英文论文、杂志和研报等场景上自建数据集训练的高精度版面区域定位模型 |
- 性能测试环境
- 测试数据集:
- 20类版面检测模型: PaddleOCR 自建的版面区域检测数据集,包含中英文论文、杂志、报纸、研报、PPT、试卷、课本等 1300 张文档类型图片。
- 1类版面子区域检测模型: PaddleOCR 自建的版面子区域检测数据集,包含中英文论文、杂志、报纸、研报、PPT、试卷、课本等 1000 张文档类型图片。
- 23类版面检测模型: PaddleOCR 自建的版面区域检测数据集,包含中英文论文、杂志、合同、书本、试卷和研报等常见的 500 张文档类型图片。
- 3类版面检测模型:PaddleOCR 自建的版面区域检测数据集,包含中英文论文、杂志和研报等常见的 1154 张文档类型图片。
- 5类英文文档区域检测模型: PubLayNet 的评估数据集,包含英文文档的 11245 张图片。
- 17类区域检测模型:PaddleOCR 自建的版面区域检测数据集,包含中英文论文、杂志和研报等常见的 892 张文档类型图片。
- 硬件配置:
- GPU:NVIDIA Tesla T4
- CPU:Intel Xeon Gold 6271C @ 2.60GHz
- 软件环境:
- Ubuntu 20.04 / CUDA 11.8 / cuDNN 8.9 / TensorRT 8.6.1.6
- paddlepaddle 3.0.0 / paddleocr 3.0.3
- 测试数据集:
- 推理模式说明
| 模式 | GPU配置 | CPU配置 | 加速技术组合 |
|---|---|---|---|
| 常规模式 | FP32精度 / 无TRT加速 | FP32精度 / 8线程 | PaddleInference |
| 高性能模式 | 选择先验精度类型和加速策略的最优组合 | FP32精度 / 8线程 | 选择先验最优后端(Paddle/OpenVINO/TRT等) |
三、快速开始¶
❗ 在快速开始前,请先安装 PaddleOCR 的 wheel 包,详细请参考 安装教程。
使用一行命令即可快速体验:
paddleocr layout_detection -i https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/layout.jpg
注:PaddleOCR 官方模型默认从 HuggingFace 获取,如运行环境访问 HuggingFace 不便,可通过环境变量修改模型源为 BOS:PADDLE_PDX_MODEL_SOURCE="BOS",未来将支持更多主流模型源;
您也可以将版面区域检测模块中的模型推理集成到您的项目中。运行以下代码前,请您下载示例图片到本地。
{kind=link}
from paddleocr import LayoutDetection
model = LayoutDetection(model_name="PP-DocLayout_plus-L")
output = model.predict("layout.jpg", batch_size=1, layout_nms=True)
for res in output:
res.print()
res.save_to_img(save_path="./output/")
res.save_to_json(save_path="./output/res.json")
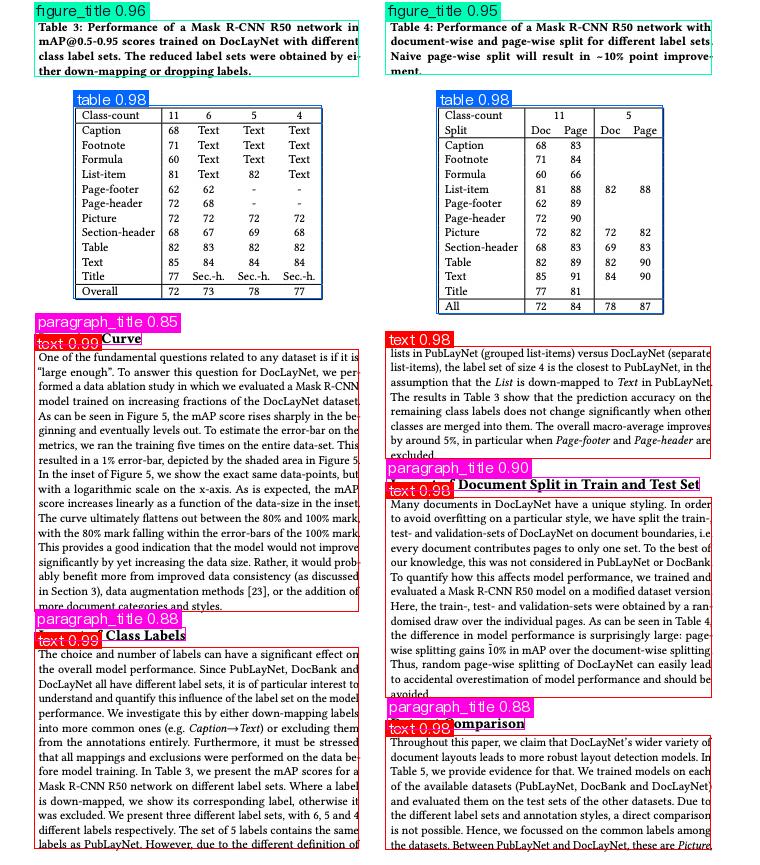
运行后,得到的结果为:
{'res': {'input_path': 'layout.jpg', 'page_index': None, 'boxes': [{'cls_id': 2, 'label': 'text', 'score': 0.9870226979255676, 'coordinate': [34.101906, 349.85275, 358.59213, 611.0772]}, {'cls_id': 2, 'label': 'text', 'score': 0.9866003394126892, 'coordinate': [34.500324, 647.1585, 358.29367, 848.66797]}, {'cls_id': 2, 'label': 'text', 'score': 0.9846674203872681, 'coordinate': [385.71445, 497.40973, 711.2261, 697.84265]}, {'cls_id': 8, 'label': 'table', 'score': 0.984126091003418, 'coordinate': [73.76879, 105.94899, 321.95303, 298.84888]}, {'cls_id': 8, 'label': 'table', 'score': 0.9834211468696594, 'coordinate': [436.95642, 105.81531, 662.7168, 313.48462]}, {'cls_id': 2, 'label': 'text', 'score': 0.9832247495651245, 'coordinate': [385.62787, 346.2288, 710.10095, 458.77127]}, {'cls_id': 2, 'label': 'text', 'score': 0.9816061854362488, 'coordinate': [385.7802, 735.1931, 710.56134, 849.9764]}, {'cls_id': 6, 'label': 'figure_title', 'score': 0.9577341079711914, 'coordinate': [34.421448, 20.055151, 358.71283, 76.53663]}, {'cls_id': 6, 'label': 'figure_title', 'score': 0.9505634307861328, 'coordinate': [385.72278, 20.053688, 711.29333, 74.92744]}, {'cls_id': 0, 'label': 'paragraph_title', 'score': 0.9001723527908325, 'coordinate': [386.46344, 477.03488, 699.4023, 490.07474]}, {'cls_id': 0, 'label': 'paragraph_title', 'score': 0.8845751285552979, 'coordinate': [35.413048, 627.73596, 185.58383, 640.52264]}, {'cls_id': 0, 'label': 'paragraph_title', 'score': 0.8837394118309021, 'coordinate': [387.17603, 716.3423, 524.7841, 729.258]}, {'cls_id': 0, 'label': 'paragraph_title', 'score': 0.8508939743041992, 'coordinate': [35.50064, 331.18445, 141.6444, 344.81097]}]}}
参数含义如下:
- input_path:输入的待预测图像的路径
- page_index:如果输入是PDF文件,则表示当前是PDF的第几页,否则为 None
- boxes:预测的目标框信息,一个字典列表。每个字典代表一个检出的目标,包含以下信息:
- cls_id:类别ID,一个整数
- label:类别标签,一个字符串
- score:目标框置信度,一个浮点数
- coordinate:目标框坐标,一个浮点数列表,格式为[xmin, ymin, xmax, ymax]
可视化图片如下:
相关方法、参数等说明如下:
LayoutDetection实例化目标检测模型(此处以PP-DocLayout_plus-L为例),具体说明如下:
| 参数 | 参数说明 | 参数类型 | 默认值 |
|---|---|---|---|
model_name |
模型名称。如果设置为None,则使用PP-DocLayout-L |
str|None |
None |
model_dir |
模型存储路径。 | str|None |
None |
device |
用于推理的设备。 例如: "cpu"、"gpu"、"npu"、"gpu:0"、"gpu:0,1"。如指定多个设备,将进行并行推理。 默认情况下,优先使用 GPU 0;若不可用则使用 CPU。 |
str|None |
None |
enable_hpi |
是否启用高性能推理。 | bool |
False |
use_tensorrt |
是否启用 Paddle Inference 的 TensorRT 子图引擎。如果模型不支持通过 TensorRT 加速,即使设置了此标志,也不会使用加速。 对于 CUDA 11.8 版本的飞桨,兼容的 TensorRT 版本为 8.x(x>=6),建议安装 TensorRT 8.6.1.6。 |
bool |
False |
precision |
当使用 Paddle Inference 的 TensorRT 子图引擎时设置的计算精度。 可选项: "fp32"、"fp16"。 |
str |
"fp32" |
enable_mkldnn |
是否启用 MKL-DNN 加速推理。如果 MKL-DNN 不可用或模型不支持通过 MKL-DNN 加速,即使设置了此标志,也不会使用加速。 |
bool |
True |
mkldnn_cache_capacity |
MKL-DNN 缓存容量。 | int |
10 |
cpu_threads |
在 CPU 上推理时使用的线程数量。 | int |
10 |
img_size |
输入图像大小。
|
int|list|None |
None |
threshold |
用于过滤掉低置信度预测结果的阈值。
|
float|dict|None |
None |
layout_nms |
是否使用NMS后处理,过滤重叠框。
|
bool|None |
None |
layout_unclip_ratio |
检测框的边长缩放倍数。
|
float|list|dict|None |
None |
layout_merge_bboxes_mode |
模型输出的检测框的合并处理模式。
|
str|dict|None |
None |
- 调用目标检测模型的
predict()方法进行推理预测,该方法会返回一个结果列表。另外,本模块还提供了predict_iter()方法。两者在参数接受和结果返回方面是完全一致的,区别在于predict_iter()返回的是一个generator,能够逐步处理和获取预测结果,适合处理大型数据集或希望节省内存的场景。可以根据实际需求选择使用这两种方法中的任意一种。predict()方法参数有input、batch_size和threshold,具体说明如下:
| 参数 | 参数说明 | 参数类型 | 默认值 |
|---|---|---|---|
input |
待预测数据,支持多种输入类型,必填。
|
Python Var|str|list |
|
batch_size |
批大小,可设置为任意正整数。 | int |
1 |
threshold |
参数含义与实例化参数基本相同。设置为None表示使用实例化参数,否则该参数优先级更高。 |
float|dict|None |
None |
layout_nms |
参数含义与实例化参数基本相同。设置为None表示使用实例化参数,否则该参数优先级更高。
| bool|None |
None |
layout_unclip_ratio |
参数含义与实例化参数基本相同。设置为None表示使用实例化参数,否则该参数优先级更高。
| float|list|dict|None |
None |
layout_merge_bboxes_mode |
参数含义与实例化参数基本相同。设置为None表示使用实例化参数,否则该参数优先级更高。
|
str|dict|None |
None |
{kind=link}
- 对预测结果进行处理,每个样本的预测结果均为对应的Result对象,且支持打印、保存为图片、保存为
json文件的操作:
| 方法 | 方法说明 | 参数 | 参数类型 | 参数说明 | 默认值 |
|---|---|---|---|---|---|
print() |
打印结果到终端 | format_json |
bool |
是否对输出内容进行使用 JSON 缩进格式化 |
True |
indent |
int |
指定缩进级别,以美化输出的 JSON 数据,使其更具可读性,仅当 format_json 为 True 时有效 |
4 | ||
ensure_ascii |
bool |
控制是否将非 ASCII 字符转义为 Unicode。设置为 True 时,所有非 ASCII 字符将被转义;False 则保留原始字符,仅当format_json为True时有效 |
False |
||
save_to_json() |
将结果保存为json格式的文件 | save_path |
str |
保存的文件路径,当为目录时,保存文件命名与输入文件类型命名一致 | 无 |
indent |
int |
指定缩进级别,以美化输出的 JSON 数据,使其更具可读性,仅当 format_json 为 True 时有效 |
4 | ||
ensure_ascii |
bool |
控制是否将非 ASCII 字符转义为 Unicode。设置为 True 时,所有非 ASCII 字符将被转义;False 则保留原始字符,仅当format_json为True时有效 |
False |
||
save_to_img() |
将结果保存为图像格式的文件 | save_path |
str |
保存的文件路径,当为目录时,保存文件命名与输入文件类型命名一致 | 无 |
- 此外,也支持通过属性获取带结果的可视化图像和预测结果,具体如下:
| 属性 | 属性说明 |
|---|---|
json |
获取预测的json格式的结果 |
img |
获取格式为dict的可视化图像 |
四、二次开发¶
由于 PaddleOCR 并不直接提供版面区域检测模块的训练,因此,如果需要训练版面区域测模型,可以参考 PaddleX 版面区域检测模块二次开发部分进行训练。训练后的模型可以无缝集成到 PaddleOCR 的 API 中进行推理。