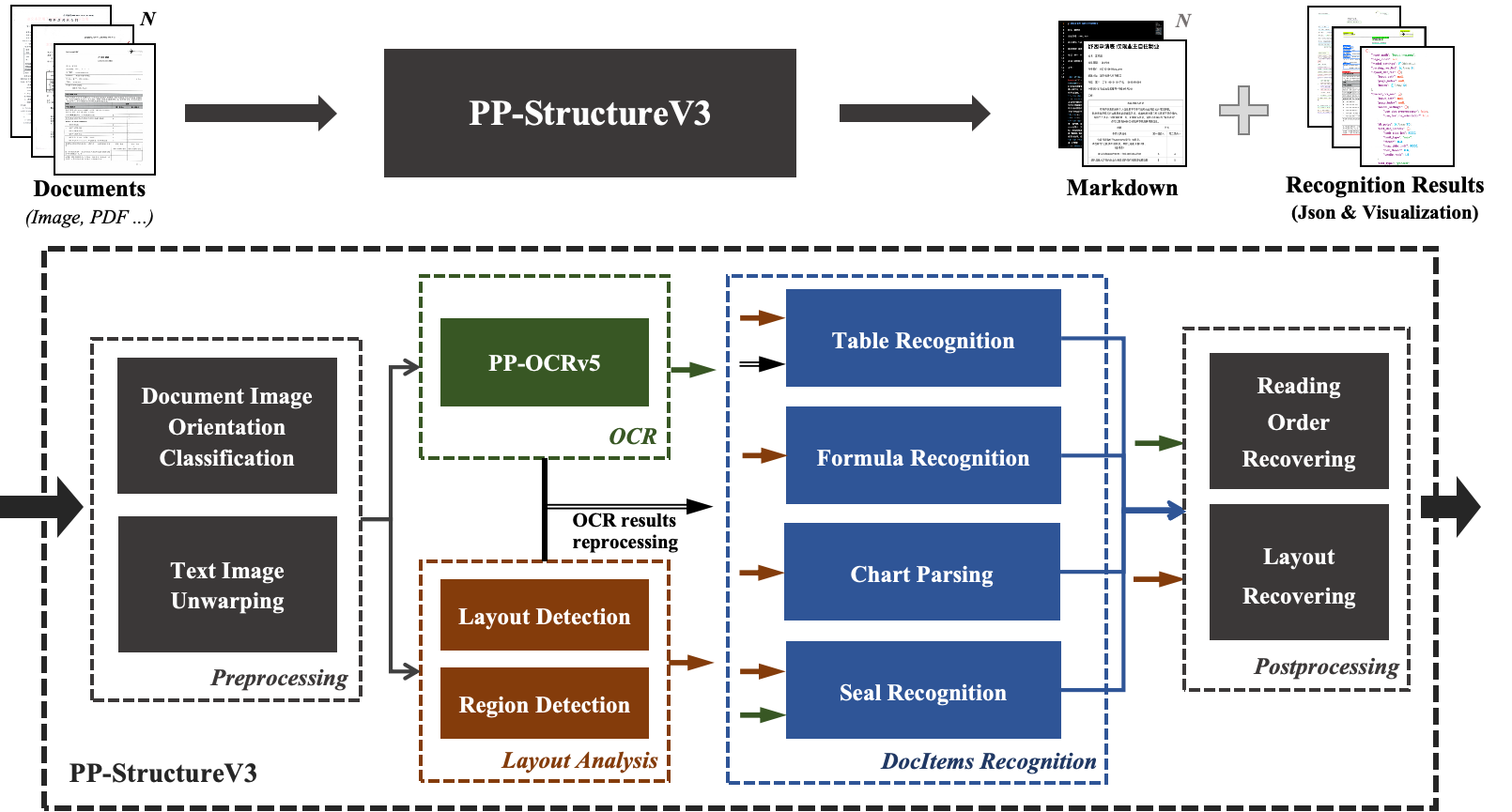
一、PP-StructureV3 简介¶
PP-StructureV3 产线在通用版面解析v1产线的基础上,强化了版面区域检测、表格识别、公式识别的能力,增加了图表理解和多栏阅读顺序的恢复能力、结果转换 Markdown 文件的能力,在多种文档数据中,表现优异,可以处理较复杂的文档数据。本产线同时提供了灵活的服务化部署方式,支持在多种硬件上使用多种编程语言调用。不仅如此,本产线也提供了二次开发的能力,您可以基于本产线在您自己的数据集上训练调优,训练后的模型也可以无缝集成。
二、关键指标¶
| Method Type | Methods | OverallEdit↓ | TextEdit↓ | FormulaEdit↓ | TableEdit↓ | Read OrderEdit↓ | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| EN | ZH | EN | ZH | EN | ZH | EN | ZH | EN | ZH | ||
| Pipeline Tools | PP-structureV3 | 0.145 | 0.206 | 0.058 | 0.088 | 0.295 | 0.535 | 0.159 | 0.109 | 0.069 | 0.091 |
| MinerU-0.9.3 | 0.15 | 0.357 | 0.061 | 0.215 | 0.278 | 0.577 | 0.18 | 0.344 | 0.079 | 0.292 | |
| MinerU-1.3.11 | 0.166 | 0.310 | 0.0826 | 0.2000 | 0.3368 | 0.6236 | 0.1613 | 0.1833 | 0.0834 | 0.2316 | |
| Marker-1.2.3 | 0.336 | 0.556 | 0.08 | 0.315 | 0.53 | 0.883 | 0.619 | 0.685 | 0.114 | 0.34 | |
| Mathpix | 0.191 | 0.365 | 0.105 | 0.384 | 0.306 | 0.454 | 0.243 | 0.32 | 0.108 | 0.304 | |
| Docling-2.14.0 | 0.589 | 0.909 | 0.416 | 0.987 | 0.999 | 1 | 0.627 | 0.81 | 0.313 | 0.837 | |
| Pix2Text-1.1.2.3 | 0.32 | 0.528 | 0.138 | 0.356 | 0.276 | 0.611 | 0.584 | 0.645 | 0.281 | 0.499 | |
| Unstructured-0.17.2 | 0.586 | 0.716 | 0.198 | 0.481 | 0.999 | 1 | 1 | 0.998 | 0.145 | 0.387 | |
| OpenParse-0.7.0 | 0.646 | 0.814 | 0.681 | 0.974 | 0.996 | 1 | 0.284 | 0.639 | 0.595 | 0.641 | |
| Expert VLMs | GOT-OCR | 0.287 | 0.411 | 0.189 | 0.315 | 0.36 | 0.528 | 0.459 | 0.52 | 0.141 | 0.28 |
| Nougat | 0.452 | 0.973 | 0.365 | 0.998 | 0.488 | 0.941 | 0.572 | 1 | 0.382 | 0.954 | |
| Mistral OCR | 0.268 | 0.439 | 0.072 | 0.325 | 0.318 | 0.495 | 0.6 | 0.65 | 0.083 | 0.284 | |
| OLMOCR-sglang | 0.326 | 0.469 | 0.097 | 0.293 | 0.455 | 0.655 | 0.608 | 0.652 | 0.145 | 0.277 | |
| SmolDocling-256M_transformer | 0.493 | 0.816 | 0.262 | 0.838 | 0.753 | 0.997 | 0.729 | 0.907 | 0.227 | 0.522 | |
| General VLMs | Gemini2.0-flash | 0.191 | 0.264 | 0.091 | 0.139 | 0.389 | 0.584 | 0.193 | 0.206 | 0.092 | 0.128 |
| Gemini2.5-Pro | 0.148 | 0.212 | 0.055 | 0.168 | 0.356 | 0.439 | 0.13 | 0.119 | 0.049 | 0.121 | |
| GPT4o | 0.233 | 0.399 | 0.144 | 0.409 | 0.425 | 0.606 | 0.234 | 0.329 | 0.128 | 0.251 | |
| Qwen2-VL-72B | 0.252 | 0.327 | 0.096 | 0.218 | 0.404 | 0.487 | 0.387 | 0.408 | 0.119 | 0.193 | |
| Qwen2.5-VL-72B | 0.214 | 0.261 | 0.092 | 0.18 | 0.315 | 0.434 | 0.341 | 0.262 | 0.106 | 0.168 | |
| InternVL2-76B | 0.44 | 0.443 | 0.353 | 0.29 | 0.543 | 0.701 | 0.547 | 0.555 | 0.317 | 0.228 | |
以上部分数据出自: * OmniDocBench * OmniDocBench: Benchmarking Diverse PDF Document Parsing with Comprehensive Annotations
三、推理 Benchmark¶
在不同GPU环境下,不同配置的 PP-StructureV3 和 MinerU 对比的性能指标如下。
基本测试环境: * Paddle 3.0正式版 * PaddleOCR 3.0.0正式版 * MinerU 1.3.10 * CUDA 11.8 * cuDNN 8.9
3.1 本地推理¶
本地推理分别在 V100 和 A100 两种 GPU机器上,测试了 6 种不同配置下 PP-StructureV3 的性能,测试数据为15个PDF文件,共925页,包含表格、公式、印章、图表等元素。
下述 PP-StructureV3 配置中,OCR 模型详情请见PP-OCRv5,公式识别模型详情请见公式识别,文本检测模块 max_side_limit 设置请见文本检测。
NVIDIA Tesla V100 + Intel Xeon Gold 6271C¶
| 方案 | 配置 | 平均每页耗时 (s) | 平均CPU利用率 (%) | 峰值RAM用量 (GB) | 平均RAM用量 (GB) | 平均GPU利用率 (%) | 峰值VRAM用量 (GB) | 平均VRAM用量 (GB) | |||
| PP-StructureV3 | OCR模型 | 公式识别模型 | 是否启用图表识别模块 | 文本检测max_side_limit | |||||||
| Server系列 | PP-FormulaNet-L | ✗ | 4096 | 1.77 | 111.4 | 6.7 | 5.2 | 38.9 | 17.0 | 16.5 | |
| Server系列 | PP-FormulaNet-L | ✔ | 4096 | 4.09 | 105.3 | 5.5 | 4.0 | 24.7 | 17.0 | 16.6 | |
| Mobile系列 | PP-FormulaNet-L | ✗ | 4096 | 1.56 | 113.7 | 6.6 | 4.9 | 29.1 | 10.7 | 10.6 | |
| Server系列 | PP-FormulaNet-M | ✗ | 4096 | 1.42 | 112.9 | 6.8 | 5.1 | 38 | 16.0 | 15.5 | |
| Mobile系列 | PP-FormulaNet-M | ✗ | 4096 | 1.15 | 114.8 | 6.5 | 5.0 | 26.1 | 8.4 | 8.3 | |
| Mobile系列 | PP-FormulaNet-M | ✗ | 1200 | 0.99 | 113 | 7.0 | 5.6 | 29.2 | 8.6 | 8.5 | |
| MinerU | - | 1.57 | 142.9 | 13.3 | 11.8 | 43.3 | 31.6 | 9.7 | |||
NVIDIA A100 + Intel Xeon Platinum 8350C¶
| 方案 | 配置 | 平均每页耗时 (s) | 平均CPU利用率 (%) | 峰值RAM用量 (GB) | 平均RAM用量 (GB) | 平均GPU利用率 (%) | 峰值VRAM用量 (GB) | 平均VRAM用量 (GB) | |||
| PP-StructureV3 | OCR模型 | 公式识别模型 | 是否启用图表识别模块 | 文本检测max_side_limit | |||||||
| Server系列 | PP-FormulaNet-L | ✗ | 4096 | 1.12 | 109.8 | 9.2 | 7.8 | 29.8 | 21.8 | 21.1 | |
| Server系列 | PP-FormulaNet-L | ✔ | 4096 | 2.76 | 103.7 | 9.0 | 7.7 | 24 | 21.8 | 21.1 | |
| Mobile系列 | PP-FormulaNet-L | ✗ | 4096 | 1.04 | 110.7 | 9.3 | 7.8 | 22 | 12.2 | 12.1 | |
| Server系列 | PP-FormulaNet-M | ✗ | 4096 | 0.95 | 111.4 | 9.1 | 7.8 | 28.1 | 21.8 | 21.0 | |
| Mobile系列 | PP-FormulaNet-M | ✗ | 4096 | 0.89 | 112.1 | 9.2 | 7.8 | 18.5 | 11.4 | 11.2 | |
| Mobile系列 | PP-FormulaNet-M | ✗ | 1200 | 0.64 | 113.5 | 10.2 | 8.5 | 23.7 | 11.4 | 11.2 | |
| MinerU | - | 1.06 | 168.3 | 18.3 | 16.8 | 27.5 | 76.9 | 14.8 | |||
3.2 服务化部署¶
服务化部署测试基于 NVIDIA A100 + Intel Xeon Platinum 8350C 环境,测试数据为 1500 张图像,包含表格、公式、印章、图表等元素。
| 实例数 | 并发请求数 | 吞吐 | 平均时延(s) | 成功请求数/总请求数 | 4卡 ✖️ 1实例/卡 | 4 | 1.69 | 2.36 | 100% | 4卡 ✖️ 4实例/卡 | 16 | 4.05 | 3.87 | 100% |
四、PP-StructureV3 Demo示例¶

五、使用方法和常见问题¶
- 默认模型是什么配置,如果需要更高精度、更快速度、或者更小显存,应该调哪些参数或者更换哪些模型,对结果影响大概有多大?
在“使用轻量OCR模型+轻量公式模型,文本检测max 1200”的基础上,将产线配置文件中的use_chart_recognition设置为False,不加载图表识别模型,可以进一步减少显存用量。在V100测试环境中,峰值和平均显存用量分别从8776.0 MB和8680.8 MB降低到6118.0 MB和6016.7 MB;在A100测试环境中,峰值和平均显存用量分别从11716.0 MB和11453.9 MB降低到9850.0 MB和9593.5 MB。 在Python API或CLI设置device为<设备类型>:<设备编号1>,<设备编号2>...(例如gpu:0,1,2,3)可实现多卡并行推理。如果内置的多卡并行推理功能提速效果仍不满足预期,可参考多进程并行推理示例代码,结合具体场景进行进一步优化:多进程并行推理。
- 服务化部署的常见问题
(1)服务可以并发处理请求吗?
对于基础服务化部署方案,服务同一时间只处理一个请求,该方案主要用于快速验证、打通开发链路,或者用在不需要并发请求的场景;
对于高稳定性服务化部署方案,服务默认在同一时间只处理一个请求,但用户可以参考服务化部署指南,通过调整配置实现水平扩展,以使服务同时处理多个请求。
(2)如何降低时延、提升吞吐?
无论使用哪一种服务化部署方案,都可以通过启用高性能推理插件提升模型推理速度,从而降低处理时延。
此外,对于高稳定性服务化部署方案,通过调整服务配置,设置多个实例,也可以充分利用部署机器的资源,有效提升吞吐。