Mobile deployment based on Paddle-Lite¶
This tutorial will introduce how to use Paddle-Lite to deploy PaddleOCR ultra-lightweight Chinese and English detection models on mobile phones.
Paddle-Lite is a lightweight inference engine for PaddlePaddle. It provides efficient inference capabilities for mobile phones and IoT, and extensively integrates cross-platform hardware to provide lightweight deployment solutions for end-side deployment issues.
1. Preparation¶
Preparation environment¶
- Computer (for Compiling Paddle Lite)
- Mobile phone (arm7 or arm8)
1.1 Prepare the cross-compilation environment¶
The cross-compilation environment is used to compile C++ demos of Paddle Lite and PaddleOCR. Supports multiple development environments.
For the compilation process of different development environments, please refer to the corresponding documents.
1.2 Prepare Paddle-Lite library¶
There are two ways to obtain the Paddle-Lite library:
-
[Recommended] Download directly, the download link of the Paddle-Lite library is as follows:
Platform Paddle-Lite library download link Android arm7 / arm8 IOS arm7 / arm8 Note: 1. The above Paddle-Lite library is compiled from the Paddle-Lite 2.10 branch. For more information about Paddle-Lite 2.10, please refer to link.
Note: It is recommended to use paddlelite>=2.10 version of the prediction library, other prediction library versions download link
-
Compile Paddle-Lite to get the prediction library. The compilation method of Paddle-Lite is as follows:
Note: When compiling Paddle-Lite to obtain the Paddle-Lite library, you need to turn on the two options --with_cv=ON --with_extra=ON, --arch means the arm version, here is designated as armv8,
More compilation commands refer to the introduction link 。
After directly downloading the Paddle-Lite library and decompressing it, you can get the inference_lite_lib.android.armv8/ folder, and the Paddle-Lite library obtained by compiling Paddle-Lite is located
Paddle-Lite/build.lite.android.armv8.gcc/inference_lite_lib.android.armv8/ folder.
The structure of the prediction library is as follows:
2 Run¶
2.1 Inference Model Optimization¶
Paddle Lite provides a variety of strategies to automatically optimize the original training model, including quantization, sub-graph fusion, hybrid scheduling, Kernel optimization and so on. In order to make the optimization process more convenient and easy to use, Paddle Lite provide opt tools to automatically complete the optimization steps and output a lightweight, optimal executable model.
If you have prepared the model file ending in .nb, you can skip this step.
The following table also provides a series of models that can be deployed on mobile phones to recognize Chinese. You can directly download the optimized model.
| Version | Introduction | Model size | Detection model | Text Direction model | Recognition model | Paddle-Lite branch |
|---|---|---|---|---|---|---|
| PP-OCRv3 | extra-lightweight chinese OCR optimized model | 16.2M | download link | download link | download link | v2.10 |
| PP-OCRv3(slim) | extra-lightweight chinese OCR optimized model | 5.9M | download link | download link | download link | v2.10 |
| PP-OCRv2 | extra-lightweight chinese OCR optimized model | 11M | download link | download link | download link | v2.10 |
| PP-OCRv2(slim) | extra-lightweight chinese OCR optimized model | 4.6M | download link | download link | download link | v2.10 |
If you directly use the model in the above table for deployment, you can skip the following steps and directly read Section 2.2.
If the model to be deployed is not in the above table, you need to follow the steps below to obtain the optimized model.
Step 1: Refer to document to install paddlelite, which is used to convert paddle inference model to paddlelite required for running nb model
After installation, the following commands can view the help information
Introduction to paddle_lite_opt parameters:
| Options | Description |
|---|---|
| --model_dir | The path of the PaddlePaddle model to be optimized (non-combined form) |
| --model_file | The network structure file path of the PaddlePaddle model (combined form) to be optimized |
| --param_file | The weight file path of the PaddlePaddle model (combined form) to be optimized |
| --optimize_out_type | Output model type, currently supports two types: protobuf and naive_buffer, among which naive_buffer is a more lightweight serialization/deserialization implementation. If you need to perform model prediction on the mobile side, please set this option to naive_buffer. The default is protobuf |
| --optimize_out | The output path of the optimized model |
| --valid_targets | The executable backend of the model, the default is arm. Currently it supports x86, arm, opencl, npu, xpu, multiple backends can be specified at the same time (separated by spaces), and Model Optimize Tool will automatically select the best method. If you need to support Huawei NPU (DaVinci architecture NPU equipped with Kirin 810/990 Soc), it should be set to npu, arm |
| --record_tailoring_info | When using the function of cutting library files according to the model, set this option to true to record the kernel and OP information contained in the optimized model. The default is false |
--model_dir is suitable for the non-combined mode of the model to be optimized, and the inference model of PaddleOCR is the combined mode, that is, the model structure and model parameters are stored in a single file.
Step 2: Use paddle_lite_opt to convert the inference model to the mobile model format.
The following takes the ultra-lightweight Chinese model of PaddleOCR as an example to introduce the use of the compiled opt file to complete the conversion of the inference model to the Paddle-Lite optimized model
After the conversion is successful, there will be more files ending with .nb in the inference model directory, which is the successfully converted model file.
2.2 Run optimized model on Phone¶
Some preparatory work is required first.
-
Prepare an Android phone with arm8. If the compiled prediction library and opt file are armv7, you need an arm7 phone and modify ARM_ABI = arm7 in the Makefile.
-
Make sure the phone is connected to the computer, open the USB debugging option of the phone, and select the file transfer mode.
-
Install the adb tool on the computer.
3.1. Install ADB for MAC:
3.2. Install ADB for Linux
3.3. Install ADB for windows
To install on win, you need to go to Google's Android platform to download the adb package for installation:link
Verify whether adb is installed successfully
If there is device output, it means the installation is successful。
-
Prepare optimized models, prediction library files, test images and dictionary files used.
Prepare the test image, taking PaddleOCR/doc/imgs/11.jpg as an example, copy the image file to the demo/cxx/ocr/debug/ folder. Prepare the model files optimized by the lite opt tool, ch_PP-OCRv3_det_slim_opt.nb , ch_PP-OCRv3_rec_slim_opt.nb , and place them under the demo/cxx/ocr/debug/ folder.
The structure of the OCR demo is as follows after the above command is executed:
Note:
ppocr_keys_v1.txtis a Chinese dictionary file. If the nb model is used for English recognition or other language recognition, dictionary file should be replaced with a dictionary of the corresponding language. PaddleOCR provides a variety of dictionaries under ppocr/utils/, including:
-
config.txtof the detector and classifier, as shown below: -
Run Model on phone
After the above steps are completed, you can use adb to push the file to the phone to run, the steps are as follows:
If you modify the code, you need to recompile and push to the phone.
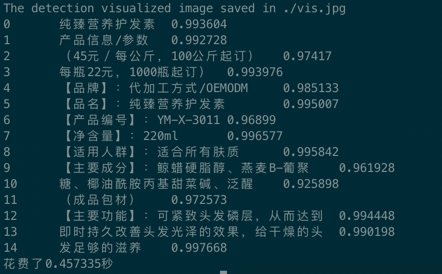
The outputs are as follows:
FAQ¶
Q1: What if I want to change the model, do I need to run it again according to the process?
A1: If you have performed the above steps, you only need to replace the .nb model file to complete the model replacement.
Q2: How to test with another picture?
A2: Replace the .jpg test image under ./debug with the image you want to test, and run adb push to push new image to the phone.
Q3: How to package it into the mobile APP?
A3: This demo aims to provide the core algorithm part that can run OCR on mobile phones. Further, PaddleOCR/deploy/android_demo is an example of encapsulating this demo into a mobile app for reference.
Q4: When running the demo, an error is reported Error: This model is not supported, because kernel for 'io_copy' is not supported by Paddle-Lite.
A4: The problem is that the installed paddlelite version does not match the downloaded prediction library version. Make sure that the paddleliteopt tool matches your prediction library version, and try to switch to the nb model again.