快速构建卡证类OCR¶
1. 金融行业卡证识别应用¶
1.1 金融行业中的OCR相关技术¶
《“十四五”数字经济发展规划》指出,2020年我国数字经济核心产业增加值占GDP比重达7.8%,随着数字经济迈向全面扩展,到2025年该比例将提升至10%。
在过去数年的跨越发展与积累沉淀中,数字金融、金融科技已在对金融业的重塑与再造中充分印证了其自身价值。
以智能为目标,提升金融数字化水平,实现业务流程自动化,降低人力成本。

1.2 金融行业中的卡证识别场景介绍¶
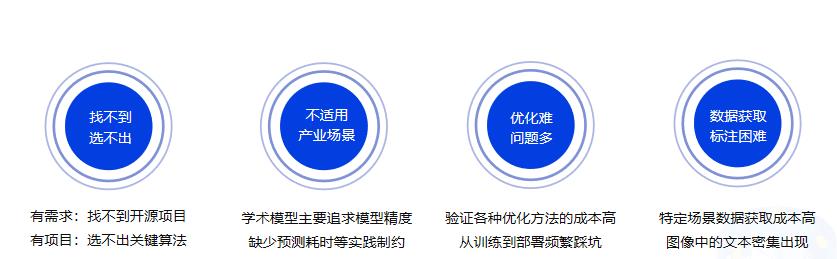
应用场景:身份证、银行卡、营业执照、驾驶证等。
应用难点:由于数据的采集来源多样,以及实际采集数据各种噪声:反光、褶皱、模糊、倾斜等各种问题干扰。

1.3 OCR落地挑战¶
2. 卡证识别技术解析¶
2.1 卡证分类模型¶
卡证分类:基于PPLCNet
与其他轻量级模型相比在CPU环境下ImageNet数据集上的表现
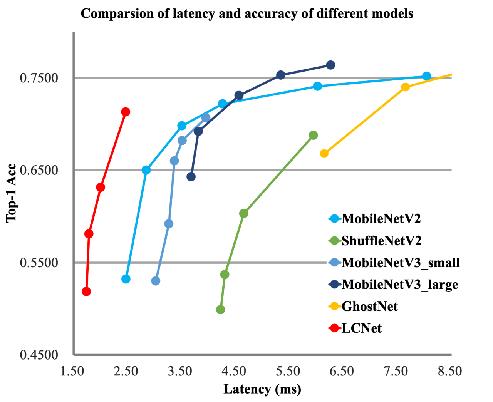
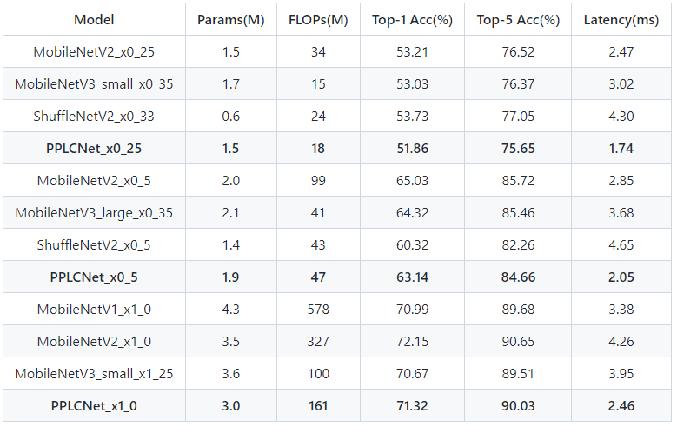
模型来自模型库PaddleClas,它是一个图像识别和图像分类任务的工具集,助力使用者训练出更好的视觉模型和应用落地。
2.2 卡证识别模型¶
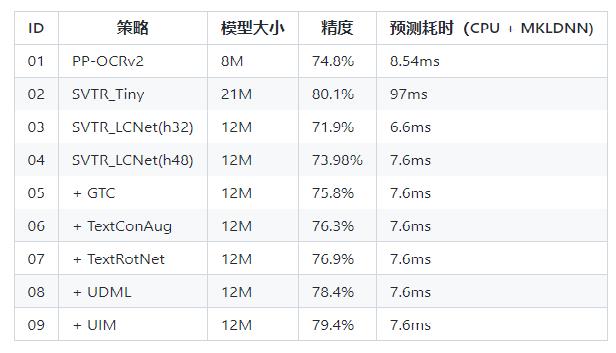
检测:DBNet 识别:SVRT

PPOCRv3在文本检测、识别进行了一系列改进优化,在保证精度的同时提升预测效率

3. OCR技术拆解¶
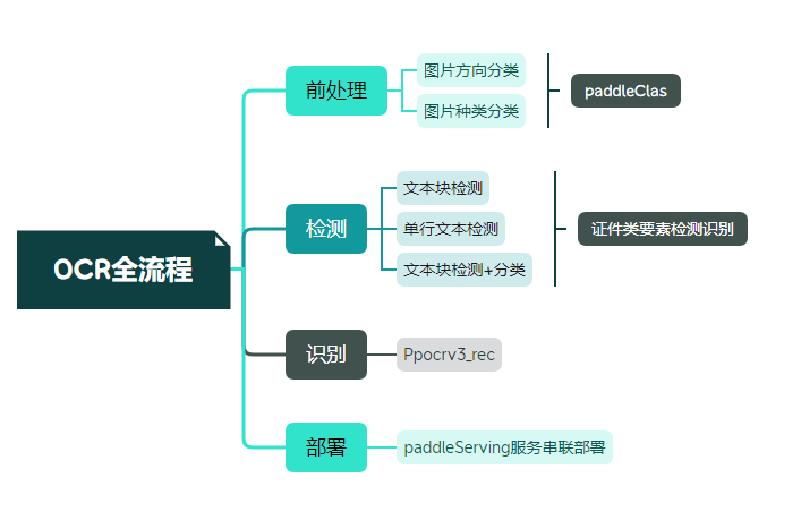
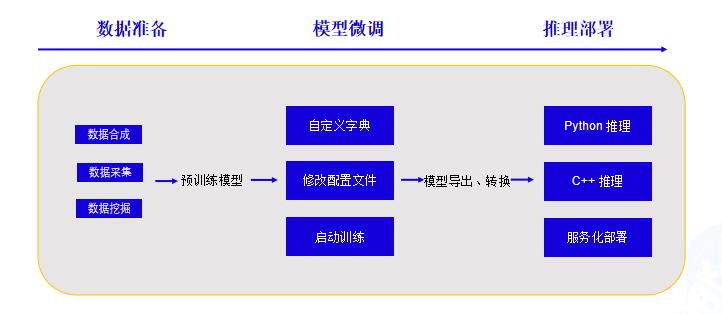
3.1技术流程¶
3.2 OCR技术拆解---卡证分类¶
卡证分类:数据、模型准备¶
A 使用爬虫获取无标注数据,将相同类别的放在同一文件夹下,文件名从0开始命名。具体格式如下图所示。
注:卡证类数据,建议每个类别数据量在500张以上

B 一行命令生成标签文件
C 下载预训练模型
卡证分类---修改配置文件¶
配置文件主要修改三个部分:
- 全局参数:预训练模型路径/训练轮次/图像尺寸
- 模型结构:分类数
- 数据处理:训练/评估数据路径

卡证分类---训练¶
指定配置文件启动训练:
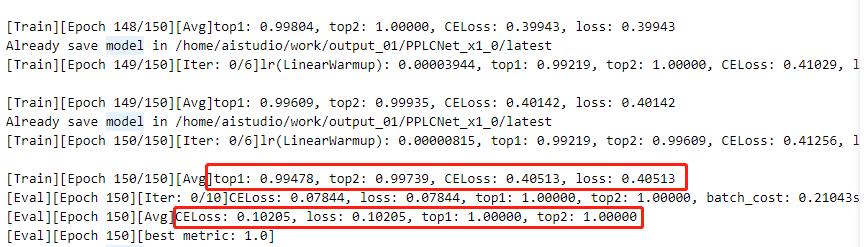
注:日志中显示了训练结果和评估结果(训练时可以设置固定轮数评估一次)
3.2 OCR技术拆解---卡证识别¶
卡证识别(以身份证检测为例) 存在的困难及问题:
-
在自然场景下,由于各种拍摄设备以及光线、角度不同等影响导致实际得到的证件影像千差万别。
-
如何快速提取需要的关键信息
-
多行的文本信息,检测结果如何正确拼接

-
OCR技术拆解---OCR工具库
PaddleOCR是一个丰富、领先且实用的OCR工具库,助力开发者训练出更好的模型并应用落地
身份证识别:用现有的方法识别

身份证识别:检测+分类¶
方法:基于现有的dbnet检测模型,加入分类方法。检测同时进行分类,从一定程度上优化识别流程


数据标注¶
使用PaddleOCRLable进行快速标注
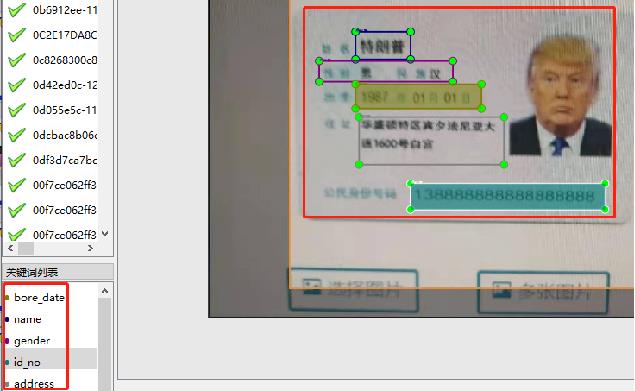
- 修改PPOCRLabel.py,将下图中的kie参数设置为True

- 数据标注踩坑分享

注:两者只有标注有差别,训练参数数据集都相同
4 . 项目实践¶
AIStudio项目链接:快速构建卡证类OCR
4.1 环境准备¶
1)拉取paddleocr项目,如果从github上拉取速度慢可以选择从gitee上获取。
2)获取并解压预训练模型,如果要使用其他模型可以从模型库里自主选择合适模型。
3)安装必要依赖
4.2 配置文件修改¶
修改配置文件 work/configs/det/detmv3db.yml
具体修改说明如下:
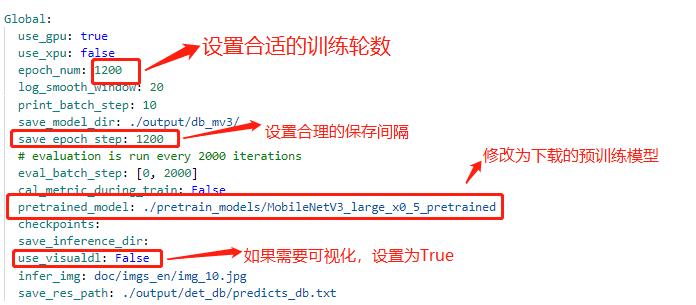
注:在上述的配置文件的Global变量中需要添加以下两个参数:
- label_list 为标签表 - num_classes 为分类数 上述两个参数根据实际的情况配置即可

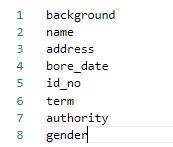
其中lable_list内容如下例所示,建议第一个参数设置为 background,不要设置为实际要提取的关键信息种类:
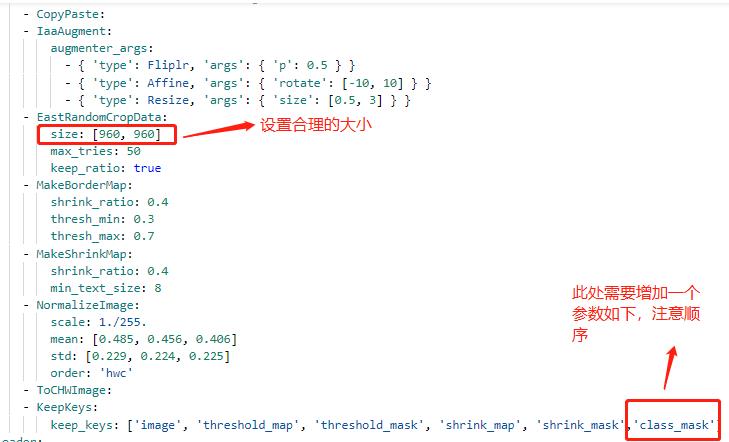
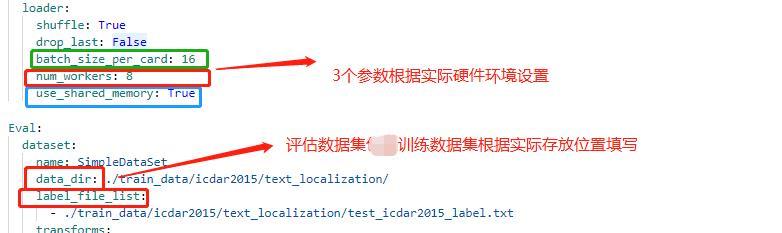
配置文件中的其他设置说明

4.3 代码修改¶
4.3.1 数据读取¶
修改 PaddleOCR/ppocr/data/imaug/label_ops.py中的DetLabelEncode
修改PaddleOCR/ppocr/data/imaug/make_shrink_map.py中的MakeShrinkMap类。这里需要注意的是,如果我们设置的label_list中的第一个参数为要检测的信息那么会得到如下的mask,
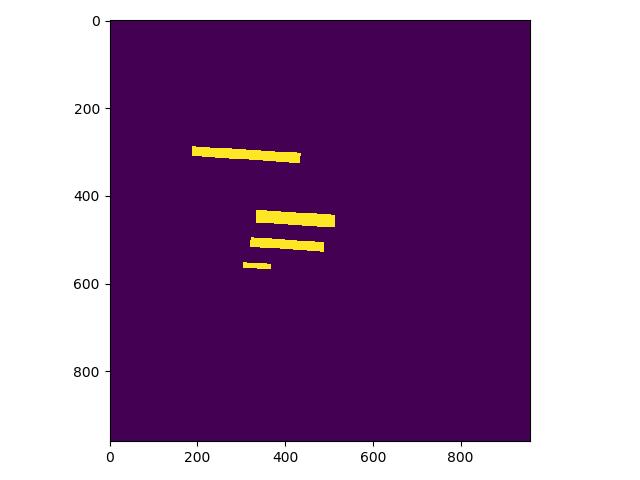
举例说明: 这是检测的mask图,图中有四个mask那么实际对应的分类应该是4类
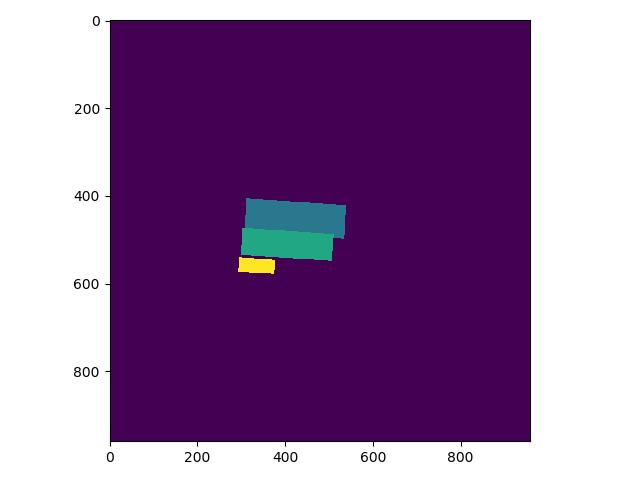
label_list中第一个为关键分类,则得到的分类Mask实际如下,与上图相比,少了一个box:
由于在训练数据中会对数据进行resize设置,yml中的操作为:EastRandomCropData,所以需要修改PaddleOCR/ppocr/data/imaug/random_crop_data.py中的EastRandomCropData
4.3.2 head修改¶
主要修改ppocr/modeling/heads/det_db_head.py,将Head类中的最后一层的输出修改为实际的分类数,同时在DBHead中新增分类的head。
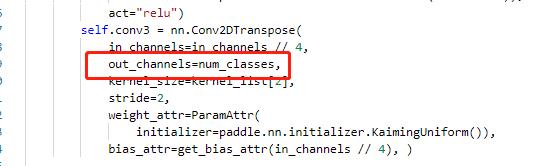
4.3.3 修改loss¶
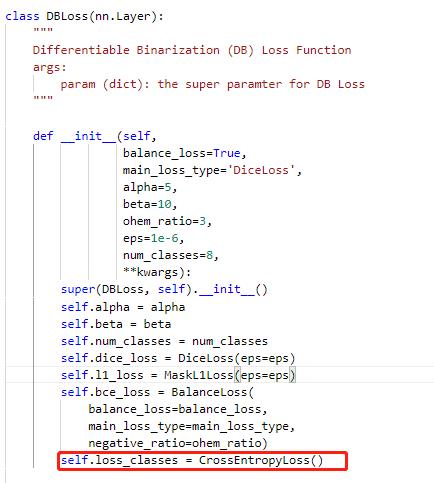
修改PaddleOCR/ppocr/losses/det_db_loss.py中的DBLoss类,分类采用交叉熵损失函数进行计算。
4.3.4 后处理¶
由于涉及到eval以及后续推理能否正常使用,我们需要修改后处理的相关代码,修改位置PaddleOCR/ppocr/postprocess/db_postprocess.py中的DBPostProcess类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 | |
4.4. 模型启动¶
在完成上述步骤后我们就可以正常启动训练
其他命令:
模型推理
5 总结¶
- 分类+检测在一定程度上能够缩短用时,具体的模型选取要根据业务场景恰当选择。
- 数据标注需要多次进行测试调整标注方法,一般进行检测模型微调,需要标注至少上百张。
- 设置合理的batch_size以及resize大小,同时注意lr设置。
References¶
- https://github.com/PaddlePaddle/PaddleOCR
- https://github.com/PaddlePaddle/PaddleClas
- https://blog.csdn.net/YY007H/article/details/124491217