基于VI-LayoutXLM的发票关键信息抽取
1. 项目背景及意义
关键信息抽取在文档场景中被广泛使用,如身份证中的姓名、住址信息抽取,快递单中的姓名、联系方式等关键字段内容的抽取。传统基于模板匹配的方案需要针对不同的场景制定模板并进行适配,较为繁琐,不够鲁棒。基于该问题,我们借助飞桨提供的PaddleOCR套件中的关键信息抽取方案,实现对增值税发票场景的关键信息抽取。
2. 项目内容
本项目基于PaddleOCR开源套件,以VI-LayoutXLM多模态关键信息抽取模型为基础,针对增值税发票场景进行适配,提取该场景的关键信息。
3. 安装环境
# 首先git官方的PaddleOCR项目,安装需要的依赖
# 第一次运行打开该注释
clone https://gitee.com/PaddlePaddle/PaddleOCR.git
cd PaddleOCR
# 安装PaddleOCR的依赖
install -r requirements.txt
# 安装关键信息抽取任务的依赖
install -r ./ppstructure/kie/requirements.txt
4. 关键信息抽取
基于文档图像的关键信息抽取包含3个部分:(1)文本检测(2)文本识别(3)关键信息抽取方法,包括语义实体识别或者关系抽取,下面分别进行介绍。
4.1 文本检测
本文重点关注发票的关键信息抽取模型训练与预测过程,因此在关键信息抽取过程中,直接使用标注的文本检测与识别标注信息进行测试,如果你希望自定义该场景的文本检测模型,完成端到端的关键信息抽取部分,请参考文本检测模型训练教程 ,按照训练数据格式准备数据,并完成该场景下垂类文本检测模型的微调过程。
4.2 文本识别
本文重点关注发票的关键信息抽取模型训练与预测过程,因此在关键信息抽取过程中,直接使用提供的文本检测与识别标注信息进行测试,如果你希望自定义该场景的文本检测模型,完成端到端的关键信息抽取部分,请参考文本识别模型训练教程 ,按照训练数据格式准备数据,并完成该场景下垂类文本识别模型的微调过程。
4.3 语义实体识别 (Semantic Entity Recognition)
语义实体识别指的是给定一段文本行,确定其类别(如姓名、住址等类别)。PaddleOCR中提供了基于VI-LayoutXLM的多模态语义实体识别方法,融合文本、位置与版面信息,相比LayoutXLM多模态模型,去除了其中的视觉骨干网络特征提取部分,引入符合阅读顺序的文本行排序方法,同时使用UDML联合互蒸馏方法进行训练,最终在精度与速度方面均超越LayoutXLM。更多关于VI-LayoutXLM的算法介绍与精度指标,请参考:VI-LayoutXLM算法介绍 。
4.3.1 准备数据
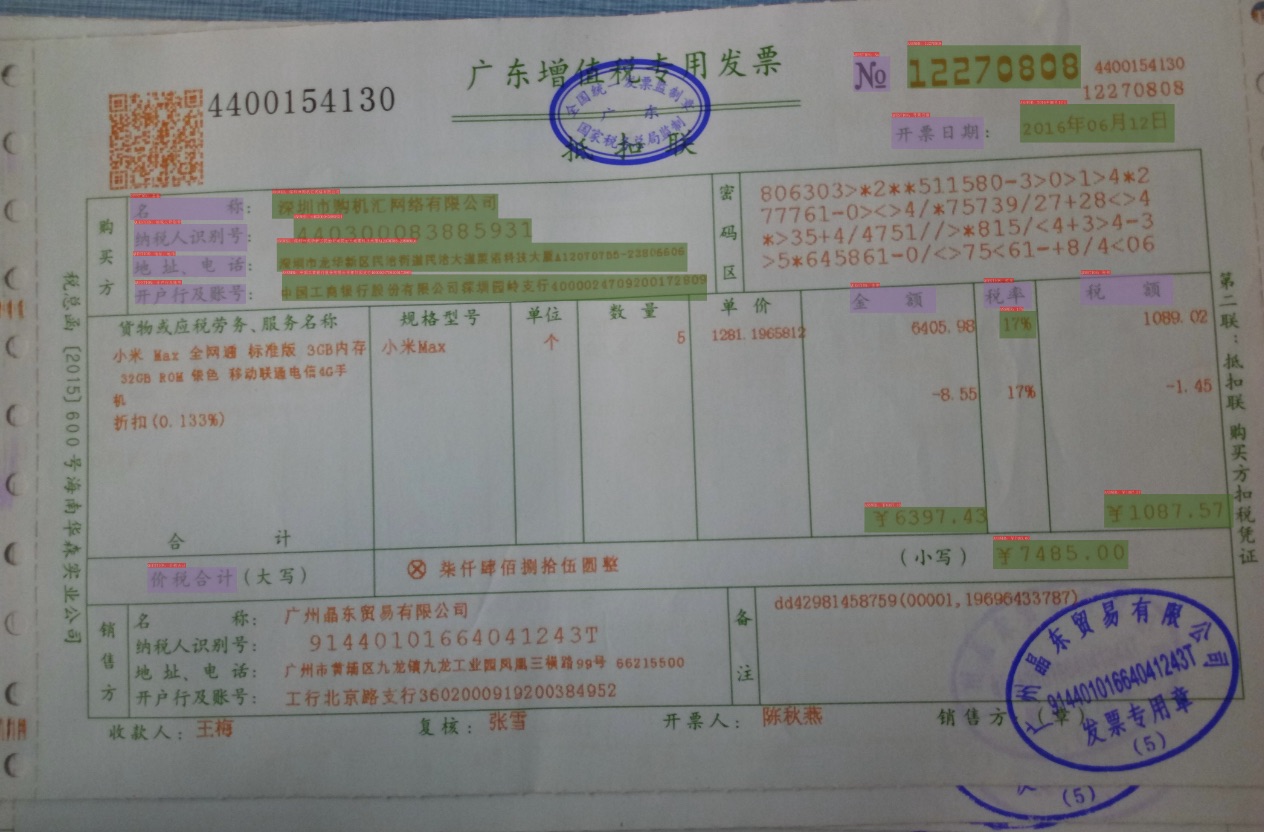
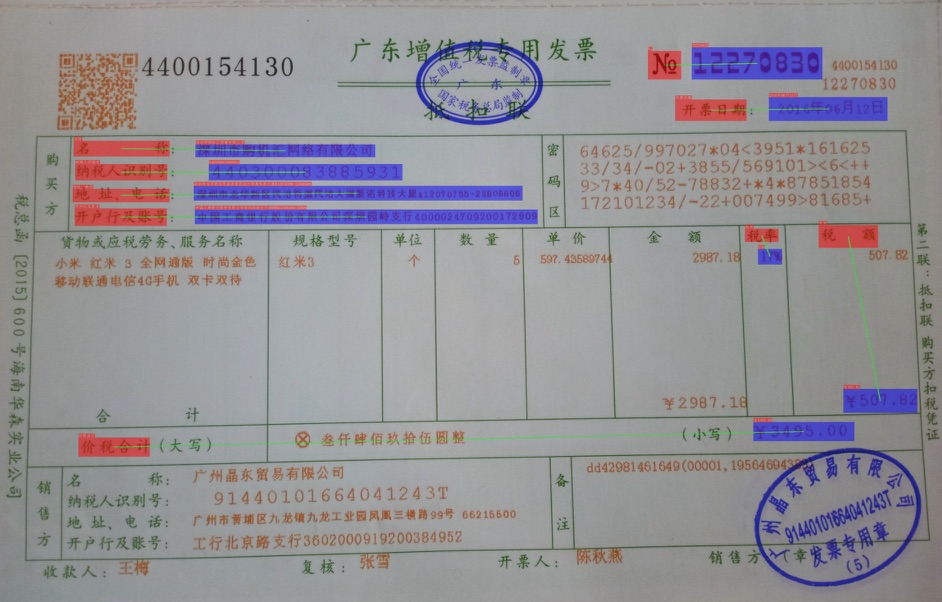
发票场景为例,我们首先需要标注出其中的关键字段,我们将其标注为问题-答案的key-value pair,如下,编号No为12270830,则No字段标注为question,12270830字段标注为answer。如下图所示。
注意:
如果文本检测模型数据标注过程中,没有标注 非关键信息内容 的检测框,那么在标注关键信息抽取任务的时候,也不需要标注该部分,如上图所示;如果标注的过程,如果同时标注了非关键信息内容 的检测框,那么我们需要将该部分的label记为other。
标注过程中,需要以文本行为单位进行标注,无需标注单个字符的位置信息。
已经处理好的增值税发票数据集从这里下载:增值税发票数据集下载链接 。
下载好发票数据集,并解压在train_data目录下,目录结构如下所示。
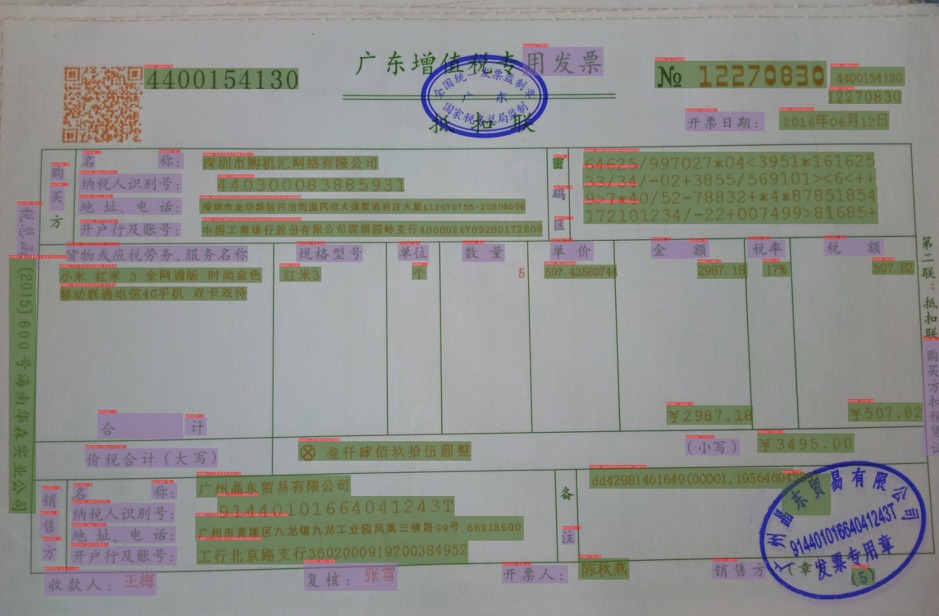
其中class_list.txt是包含other, question, answer,3个种类的的类别列表(不区分大小写),imgs目录底下,train.json与val.json分别表示训练与评估集合的标注文件。训练集中包含30张图片,验证集中包含8张图片。部分标注如下所示。
b33 . jpg [{ "transcription" : "No" , "label" : "question" , "points" : [[ 2882 , 472 ], [ 3026 , 472 ], [ 3026 , 588 ], [ 2882 , 588 ]], }, { "transcription" : "12269563" , "label" : "answer" , "points" : [[ 3066 , 448 ], [ 3598 , 448 ], [ 3598 , 576 ], [ 3066 , 576 ]], ]}]
相比于OCR检测的标注,仅多了label字段。
4.3.2 开始训练
VI-LayoutXLM的配置为ser_vi_layoutxlm_xfund_zh_udml.yml ,需要修改数据、类别数目以及配置文件。
Architecture :
model_type : &model_type "kie"
name : DistillationModel
algorithm : Distillation
Models :
Teacher :
pretrained :
freeze_params : false
return_all_feats : true
model_type : *model_type
algorithm : &algorithm "LayoutXLM"
Transform :
Backbone :
name : LayoutXLMForSer
pretrained : True
# one of base or vi
mode : vi
checkpoints :
# 定义类别数目
num_classes : &num_classes 5
...
PostProcess :
name : DistillationSerPostProcess
model_name : [ "Student" , "Teacher" ]
key : backbone_out
# 定义类别文件
class_path : &class_path train_data/zzsfp/class_list.txt
Train :
dataset :
name : SimpleDataSet
# 定义训练数据目录与标注文件
data_dir : train_data/zzsfp/imgs
label_file_list :
- train_data/zzsfp/train.json
...
Eval :
dataset :
# 定义评估数据目录与标注文件
name : SimpleDataSet
data_dir : train_data/zzsfp/imgs
label_file_list :
- train_data/zzsfp/val.json
...
LayoutXLM与VI-LayoutXLM针对该场景的训练结果如下所示。
模型
迭代轮数
Hmean
LayoutXLM
50
100.00%
VI-LayoutXLM
50
100.00%
可以看出,由于当前数据量较少,场景比较简单,因此2个模型的Hmean均达到了100%。
4.3.3 模型评估
模型训练过程中,使用的是知识蒸馏的策略,最终保留了学生模型的参数,在评估时,我们需要针对学生模型的配置文件进行修改: ser_vi_layoutxlm_xfund_zh.yml ,修改内容与训练配置相同,包括类别数、类别映射文件、数据目录 。
修改完成后,执行下面的命令完成评估过程。
# 注意:需要根据你的配置文件地址与保存的模型地址,对评估命令进行修改
tools/eval.py -c ./fapiao/ser_vi_layoutxlm.yml -o Architecture.Backbone.checkpoints= fapiao/models/ser_vi_layoutxlm_fapiao_udml/best_accuracy
输出结果如下所示:
[ 2022 /08/18 08 :49:58] ppocr INFO: metric eval ***************
[ 2022 /08/18 08 :49:58] ppocr INFO: precision:1.0
[ 2022 /08/18 08 :49:58] ppocr INFO: recall:1.0
[ 2022 /08/18 08 :49:58] ppocr INFO: hmean:1.0
[ 2022 /08/18 08 :49:58] ppocr INFO: fps:1.9740402401574881
4.3.4 模型预测
使用下面的命令进行预测:
tools/infer_kie_token_ser.py -c fapiao/ser_vi_layoutxlm.yml -o Architecture.Backbone.checkpoints= fapiao/models/ser_vi_layoutxlm_fapiao_udml/best_accuracy Global.infer_img= ./train_data/XFUND/zh_val/val.json Global.infer_mode= False
预测结果会保存在配置文件中的Global.save_res_path目录中。
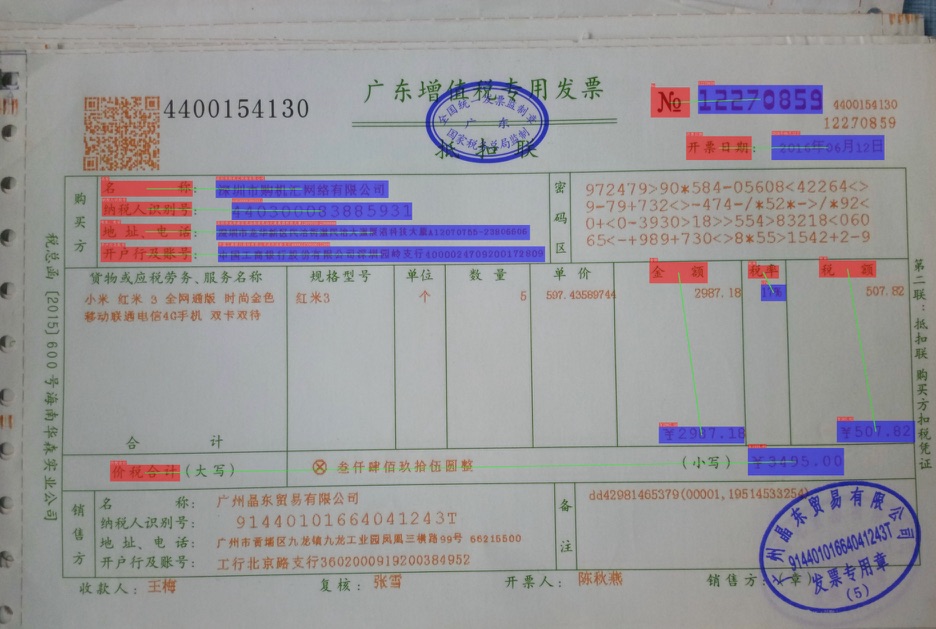
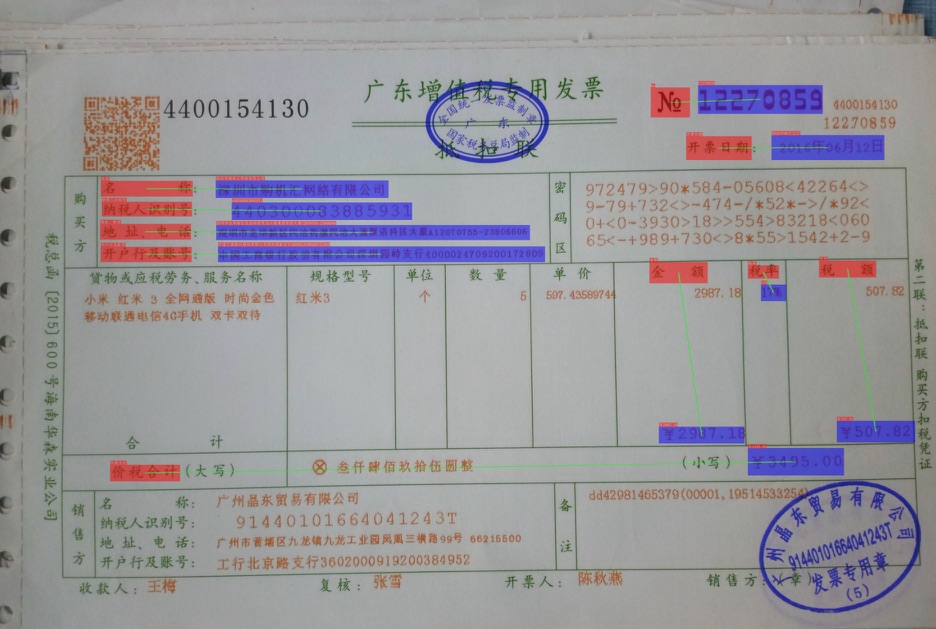
部分预测结果如下所示。
注意:在预测时,使用的文本检测与识别结果为标注的结果,直接从json文件里面进行读取。
如果希望使用OCR引擎结果得到的结果进行推理,则可以使用下面的命令进行推理。
tools/infer_kie_token_ser.py -c fapiao/ser_vi_layoutxlm.yml -o Architecture.Backbone.checkpoints= fapiao/models/ser_vi_layoutxlm_fapiao_udml/best_accuracy Global.infer_img= ./train_data/zzsfp/imgs/b25.jpg Global.infer_mode= True
结果如下所示:
它会使用PP-OCRv3的文本检测与识别模型进行获取文本位置与内容信息。
可以看出,由于训练的过程中,没有标注额外的字段为other类别,所以大多数检测出来的字段被预测为question或者answer。
如果希望构建基于你在垂类场景训练得到的OCR检测与识别模型,可以使用下面的方法传入检测与识别的inference 模型路径,即可完成OCR文本检测与识别以及SER的串联过程。
tools/infer_kie_token_ser.py -c fapiao/ser_vi_layoutxlm.yml -o Architecture.Backbone.checkpoints= fapiao/models/ser_vi_layoutxlm_fapiao_udml/best_accuracy Global.infer_img= ./train_data/zzsfp/imgs/b25.jpg Global.infer_mode= True Global.kie_rec_model_dir= "your_rec_model" Global.kie_det_model_dir= "your_det_model"
使用SER模型,可以获取图像中所有的question与answer的字段,继续这些字段的类别,我们需要进一步获取question与answer之间的连接,因此需要进一步训练关系抽取模型,解决该问题。本文也基于VI-LayoutXLM多模态预训练模型,进行下游RE任务的模型训练。
4.4.1 准备数据
以发票场景为例,相比于SER任务,RE中还需要标记每个文本行的id信息以及链接关系linking,如下所示。
标注文件的部分内容如下所示。
b33 . jpg [{ "transcription" : "No" , "label" : "question" , "points" : [[ 2882 , 472 ], [ 3026 , 472 ], [ 3026 , 588 ], [ 2882 , 588 ]], "id" : 0 , "linking" : [[ 0 , 1 ]]}, { "transcription" : "12269563" , "label" : "answer" , "points" : [[ 3066 , 448 ], [ 3598 , 448 ], [ 3598 , 576 ], [ 3066 , 576 ]], "id" : 1 , "linking" : [[ 0 , 1 ]]}]
相比与SER的标注,多了id与linking的信息,分别表示唯一标识以及连接关系。
已经处理好的增值税发票数据集从这里下载:增值税发票数据集下载链接 。
4.4.2 开始训练
基于VI-LayoutXLM的RE任务配置为re_vi_layoutxlm_xfund_zh_udml.yml ,需要修改数据路径、类别列表文件 。
Train :
dataset :
name : SimpleDataSet
# 定义训练数据目录与标注文件
data_dir : train_data/zzsfp/imgs
label_file_list :
- train_data/zzsfp/train.json
transforms :
- DecodeImage : # load image
img_mode : RGB
channel_first : False
- VQATokenLabelEncode : # Class handling label
contains_re : True
algorithm : *algorithm
class_path : &class_path train_data/zzsfp/class_list.txt
...
Eval :
dataset :
# 定义评估数据目录与标注文件
name : SimpleDataSet
data_dir : train_data/zzsfp/imgs
label_file_list :
- train_data/zzsfp/val.json
...
LayoutXLM与VI-LayoutXLM针对该场景的训练结果如下所示。
模型
迭代轮数
Hmean
LayoutXLM
50
98.00%
VI-LayoutXLM
50
99.30%
可以看出,对于VI-LayoutXLM相比LayoutXLM的Hmean高了1.3%。
4.4.3 模型评估
模型训练过程中,使用的是知识蒸馏的策略,最终保留了学生模型的参数,在评估时,我们需要针对学生模型的配置文件进行修改: re_vi_layoutxlm_xfund_zh.yml ,修改内容与训练配置相同,包括类别映射文件、数据目录 。
修改完成后,执行下面的命令完成评估过程。
# 注意:需要根据你的配置文件地址与保存的模型地址,对评估命令进行修改
tools/eval.py -c ./fapiao/re_vi_layoutxlm.yml -o Architecture.Backbone.checkpoints= fapiao/models/re_vi_layoutxlm_fapiao_udml/best_accuracy
输出结果如下所示:
[ 2022 / 08 / 18 12 : 17 : 14 ] ppocr INFO : metric eval ***************
[ 2022 / 08 / 18 12 : 17 : 14 ] ppocr INFO : precision : 1.0
[ 2022 / 08 / 18 12 : 17 : 14 ] ppocr INFO : recall : 0.9873417721518988
[ 2022 / 08 / 18 12 : 17 : 14 ] ppocr INFO : hmean : 0.9936305732484078
[ 2022 / 08 / 18 12 : 17 : 14 ] ppocr INFO : fps : 2.765963539771157
4.4.4 模型预测
使用下面的命令进行预测:
# -c 后面的是RE任务的配置文件
# -o 后面的字段是RE任务的配置
# -c_ser 后面的是SER任务的配置文件
# -c_ser 后面的字段是SER任务的配置
tools/infer_kie_token_ser_re.py -c fapiao/re_vi_layoutxlm.yml -o Architecture.Backbone.checkpoints= fapiao/models/re_vi_layoutxlm_fapiao_trained/best_accuracy Global.infer_img= ./train_data/zzsfp/val.json Global.infer_mode= False -c_ser fapiao/ser_vi_layoutxlm.yml -o_ser Architecture.Backbone.checkpoints= fapiao/models/ser_vi_layoutxlm_fapiao_trained/best_accuracy
预测结果会保存在配置文件中的Global.save_res_path目录中。
部分预测结果如下所示。
注意:在预测时,使用的文本检测与识别结果为标注的结果,直接从json文件里面进行读取。
如果希望使用OCR引擎结果得到的结果进行推理,则可以使用下面的命令进行推理。
tools/infer_kie_token_ser_re.py -c fapiao/re_vi_layoutxlm.yml -o Architecture.Backbone.checkpoints= fapiao/models/re_vi_layoutxlm_fapiao_udml/best_accuracy Global.infer_img= ./train_data/zzsfp/val.json Global.infer_mode= True -c_ser fapiao/ser_vi_layoutxlm.yml -o_ser Architecture.Backbone.checkpoints= fapiao/models/ser_vi_layoutxlm_fapiao_udml/best_accuracy
如果希望构建基于你在垂类场景训练得到的OCR检测与识别模型,可以使用下面的方法传入,即可完成SER + RE的串联过程。
tools/infer_kie_token_ser_re.py -c fapiao/re_vi_layoutxlm.yml -o Architecture.Backbone.checkpoints= fapiao/models/re_vi_layoutxlm_fapiao_udml/best_accuracy Global.infer_img= ./train_data/zzsfp/val.json Global.infer_mode= True -c_ser fapiao/ser_vi_layoutxlm.yml -o_ser Architecture.Backbone.checkpoints= fapiao/models/ser_vi_layoutxlm_fapiao_udml/best_accuracy Global.kie_rec_model_dir= "your_rec_model" Global.kie_det_model_dir= "your_det_model"
2025年4月13日
2025年4月13日
GitHub