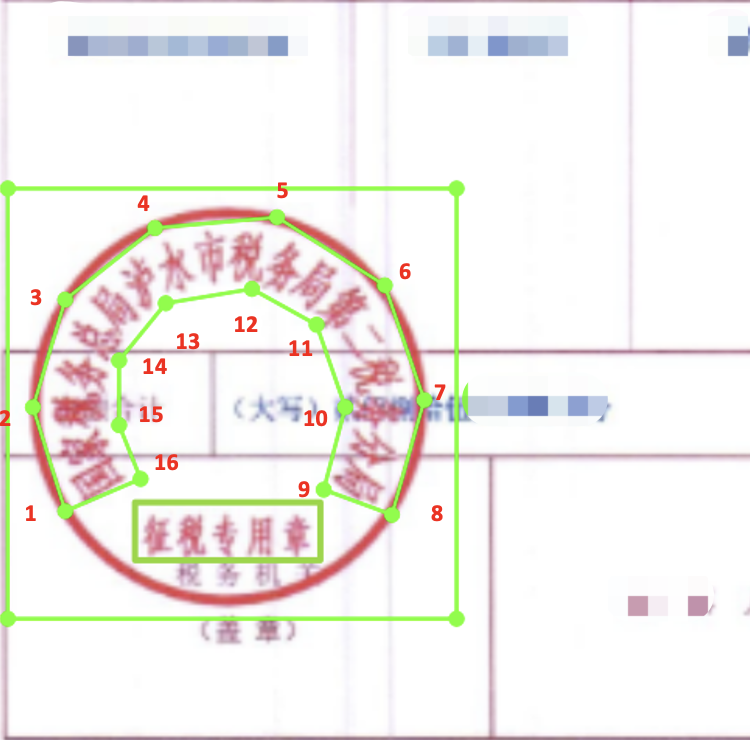
importnumpyasnpimportjsonimportcv2importosfromshapely.geometryimportPolygondefpoly2box(poly):xmin=np.min(np.array(poly)[:,0])ymin=np.min(np.array(poly)[:,1])xmax=np.max(np.array(poly)[:,0])ymax=np.max(np.array(poly)[:,1])returnnp.array([[xmin,ymin],[xmax,ymin],[xmax,ymax],[xmin,ymax]])defdraw_text_det_res(dt_boxes,src_im,color=(255,255,0)):forboxindt_boxes:box=np.array(box).astype(np.int32).reshape(-1,2)cv2.polylines(src_im,[box],True,color=color,thickness=2)returnsrc_imclassLabelDecode(object):def__init__(self,**kwargs):passdef__call__(self,data):label=json.loads(data['label'])nBox=len(label)seal_boxes=self.get_seal_boxes(label)gt_label=[]forseal_boxinseal_boxes:seal_anno={'seal_box':seal_box}boxes,txts,txt_tags=[],[],[]forbnoinrange(0,nBox):box=label[bno]['points']txt=label[bno]['transcription']try:ints=self.get_intersection(box,seal_box)exceptExceptionasE:print(E)continueifabs(Polygon(box).area-self.get_intersection(box,seal_box))<1e-3and \
abs(Polygon(box).area-self.get_union(box,seal_box))>1e-3:boxes.append(box)txts.append(txt)iftxtin['*','###','待识别']:txt_tags.append(True)else:txt_tags.append(False)seal_anno['polys']=boxesseal_anno['texts']=txtsseal_anno['ignore_tags']=txt_tagsgt_label.append(seal_anno)returngt_labeldefget_seal_boxes(self,label):nBox=len(label)seal_box=[]forbnoinrange(0,nBox):box=label[bno]['points']iflen(box)==4:seal_box.append(box)iflen(seal_box)==0:returnNoneseal_box=self.valid_seal_box(seal_box)returnseal_boxdefis_seal_box(self,box,boxes):is_seal=Trueforpolyinboxes:iflist(box.shape())!=list(box.shape.shape()):ifabs(Polygon(box).area-self.get_intersection(box,poly))<1e-3:returnFalseelse:ifnp.sum(np.array(box)-np.array(poly))<1e-3:# continue when the box is same with polycontinueifabs(Polygon(box).area-self.get_intersection(box,poly))<1e-3:returnFalsereturnis_sealdefvalid_seal_box(self,boxes):iflen(boxes)==1:returnboxesnew_boxes=[]flag=Trueforkinrange(0,len(boxes)):flag=Truetmp_box=boxes[k]foriinrange(0,len(boxes)):ifk==i:continueifabs(Polygon(tmp_box).area-self.get_intersection(tmp_box,boxes[i]))<1e-3:flag=Falsecontinueifflag:new_boxes.append(tmp_box)returnnew_boxesdefget_union(self,pD,pG):returnPolygon(pD).union(Polygon(pG)).areadefget_intersection_over_union(self,pD,pG):returnget_intersection(pD,pG)/get_union(pD,pG)defget_intersection(self,pD,pG):returnPolygon(pD).intersection(Polygon(pG)).areadefexpand_points_num(self,boxes):max_points_num=0forboxinboxes:iflen(box)>max_points_num:max_points_num=len(box)ex_boxes=[]forboxinboxes:ex_box=box+[box[-1]]*(max_points_num-len(box))ex_boxes.append(ex_box)returnex_boxesdefgen_extract_label(data_dir,label_file,seal_gt,seal_ppocr_gt):label_decode_func=LabelDecode()gts=open(label_file,"r").readlines()seal_gt_list=[]seal_ppocr_list=[]foridx,lineinenumerate(gts):img_path,label=line.strip().split("\t")data={'label':label,'img_path':img_path}res=label_decode_func(data)src_img=cv2.imread(os.path.join(data_dir,img_path))ifresisNone:print("ERROR! res is None!")continueanno=[]fori,gtinenumerate(res):# print(i, box, type(box), )anno.append({'polys':gt['seal_box'],'cls':1})seal_gt_list.append(f"{img_path}\t{json.dumps(anno)}\n")seal_ppocr_list.append(f"{img_path}\t{json.dumps(res)}\n")ifnotos.path.exists(os.path.dirname(seal_gt)):os.makedirs(os.path.dirname(seal_gt))ifnotos.path.exists(os.path.dirname(seal_ppocr_gt)):os.makedirs(os.path.dirname(seal_ppocr_gt))withopen(seal_gt,"w")asf:f.writelines(seal_gt_list)f.close()withopen(seal_ppocr_gt,'w')asf:f.writelines(seal_ppocr_list)f.close()defvis_seal_ppocr(data_dir,label_file,save_dir):datas=open(label_file,'r').readlines()foridx,lineinenumerate(datas):img_path,label=line.strip().split('\t')img_path=os.path.join(data_dir,img_path)label=json.loads(label)src_im=cv2.imread(img_path)ifsrc_imisNone:continueforannoinlabel:seal_box=anno['seal_box']txt_boxes=anno['polys']# vis seal boxsrc_im=draw_text_det_res([seal_box],src_im,color=(255,255,0))src_im=draw_text_det_res(txt_boxes,src_im,color=(255,0,0))save_path=os.path.join(save_dir,os.path.basename(img_path))ifnotos.path.exists(save_dir):os.makedirs(save_dir)# print(src_im.shape)cv2.imwrite(save_path,src_im)defdraw_html(img_dir,save_name):importglobimages_dir=glob.glob(img_dir+"/*")print(len(images_dir))html_path=save_namewithopen(html_path,'w')ashtml:html.write('<html>\n<body>\n')html.write('<table border="1">\n')html.write("<meta http-equiv=\"Content-Type\" content=\"text/html; charset=utf-8\" />")html.write("<tr>\n")html.write(f'<td> \n GT')fori,filenameinenumerate(sorted(images_dir)):iffilename.endswith("txt"):continueprint(filename)base="{}".format(filename)ifTrue:html.write("<tr>\n")html.write(f'<td> {filename}\n GT')html.write('<td>GT 310\n<img src="%s" width=640></td>'%(base))html.write("</tr>\n")html.write('<style>\n')html.write('span {\n')html.write(' color: red;\n')html.write('}\n')html.write('</style>\n')html.write('</table>\n')html.write('</html>\n</body>\n')print("ok")defcrop_seal_from_img(label_file,data_dir,save_dir,save_gt_path):ifnotos.path.exists(save_dir):os.makedirs(save_dir)datas=open(label_file,'r').readlines()all_gts=[]count=0foridx,lineinenumerate(datas):img_path,label=line.strip().split('\t')img_path=os.path.join(data_dir,img_path)label=json.loads(label)src_im=cv2.imread(img_path)ifsrc_imisNone:continueforc,annoinenumerate(label):seal_poly=anno['seal_box']txt_boxes=anno['polys']txts=anno['texts']ignore_tags=anno['ignore_tags']box=poly2box(seal_poly)img_crop=src_im[box[0][1]:box[2][1],box[0][0]:box[2][0],:]save_path=os.path.join(save_dir,f"{idx}_{c}.jpg")cv2.imwrite(save_path,np.array(img_crop))img_gt=[]foriinrange(len(txts)):txt_boxes_crop=np.array(txt_boxes[i])txt_boxes_crop[:,1]-=box[0,1]txt_boxes_crop[:,0]-=box[0,0]img_gt.append({'transcription':txts[i],"points":txt_boxes_crop.tolist(),"ignore_tag":ignore_tags[i]})iflen(img_gt)>=1:count+=1save_gt=f"{os.path.basename(save_path)}\t{json.dumps(img_gt)}\n"all_gts.append(save_gt)print(f"The num of all image: {len(all_gts)}, and the number of useful image: {count}")ifnotos.path.exists(os.path.dirname(save_gt_path)):os.makedirs(os.path.dirname(save_gt_path))withopen(save_gt_path,"w")asf:f.writelines(all_gts)f.close()print("Done")if__name__=="__main__":# 数据处理gen_extract_label("./seal_labeled_datas","./seal_labeled_datas/Label.txt","./seal_ppocr_gt/seal_det_img.txt","./seal_ppocr_gt/seal_ppocr_img.txt")vis_seal_ppocr("./seal_labeled_datas","./seal_ppocr_gt/seal_ppocr_img.txt","./seal_ppocr_gt/seal_ppocr_vis/")draw_html("./seal_ppocr_gt/seal_ppocr_vis/","./vis_seal_ppocr.html")seal_ppocr_img_label="./seal_ppocr_gt/seal_ppocr_img.txt"crop_seal_from_img(seal_ppocr_img_label,"./seal_labeled_datas/","./seal_img_crop","./seal_img_crop/label.txt")
importosimportnumpyasnpfromppdet.core.workspaceimportregister,serializablefrom.datasetimportDetDatasetimportcv2importjsonfromppdet.utils.loggerimportsetup_loggerlogger=setup_logger(__name__)@register@serializableclassSealDataSet(DetDataset):""" Load dataset with COCO format. Args: dataset_dir (str): root directory for dataset. image_dir (str): directory for images. anno_path (str): coco annotation file path. data_fields (list): key name of data dictionary, at least have 'image'. sample_num (int): number of samples to load, -1 means all. load_crowd (bool): whether to load crowded ground-truth. False as default allow_empty (bool): whether to load empty entry. False as default empty_ratio (float): the ratio of empty record number to total record's, if empty_ratio is out of [0. ,1.), do not sample the records and use all the empty entries. 1. as default """def__init__(self,dataset_dir=None,image_dir=None,anno_path=None,data_fields=['image'],sample_num=-1,load_crowd=False,allow_empty=False,empty_ratio=1.):super(SealDataSet,self).__init__(dataset_dir,image_dir,anno_path,data_fields,sample_num)self.load_image_only=Falseself.load_semantic=Falseself.load_crowd=load_crowdself.allow_empty=allow_emptyself.empty_ratio=empty_ratiodef_sample_empty(self,records,num):# if empty_ratio is out of [0. ,1.), do not sample the recordsifself.empty_ratio<0.orself.empty_ratio>=1.:returnrecordsimportrandomsample_num=min(int(num*self.empty_ratio/(1-self.empty_ratio)),len(records))records=random.sample(records,sample_num)returnrecordsdefparse_dataset(self):anno_path=os.path.join(self.dataset_dir,self.anno_path)image_dir=os.path.join(self.dataset_dir,self.image_dir)records=[]empty_records=[]ct=0assertanno_path.endswith('.txt'), \
'invalid seal_gt file: '+anno_pathall_datas=open(anno_path,'r').readlines()foridx,lineinenumerate(all_datas):im_path,label=line.strip().split('\t')img_path=os.path.join(image_dir,im_path)label=json.loads(label)im_h,im_w,im_c=cv2.imread(img_path).shapecoco_rec={'im_file':img_path,'im_id':np.array([idx]),'h':im_h,'w':im_w,}if'image'inself.data_fieldselse{}ifnotself.load_image_only:bboxes=[]forannoinlabel:poly=anno['polys']# poly to boxx1=np.min(np.array(poly)[:,0])y1=np.min(np.array(poly)[:,1])x2=np.max(np.array(poly)[:,0])y2=np.max(np.array(poly)[:,1])eps=1e-5ifx2-x1>epsandy2-y1>eps:clean_box=[round(float(x),3)forxin[x1,y1,x2,y2]]anno={'clean_box':clean_box,'gt_cls':int(anno['cls'])}bboxes.append(anno)else:logger.info("invalid box")num_bbox=len(bboxes)ifnum_bbox<=0:continuegt_bbox=np.zeros((num_bbox,4),dtype=np.float32)gt_class=np.zeros((num_bbox,1),dtype=np.int32)is_crowd=np.zeros((num_bbox,1),dtype=np.int32)# gt_poly = [None] * num_bboxfori,boxinenumerate(bboxes):gt_class[i][0]=box['gt_cls']gt_bbox[i,:]=box['clean_box']is_crowd[i][0]=0gt_rec={'is_crowd':is_crowd,'gt_class':gt_class,'gt_bbox':gt_bbox,# 'gt_poly': gt_poly,}fork,vingt_rec.items():ifkinself.data_fields:coco_rec[k]=vrecords.append(coco_rec)ct+=1ifself.sample_num>0andct>=self.sample_num:breakself.roidbs=records