KIE Algorithm - VI-LayoutXLM¶
1. Introduction¶
VI-LayoutXLM is improved based on LayoutXLM. In the process of downstream finetuning, the visual backbone network module is removed, and the model infernce speed is further improved on the basis of almost lossless accuracy.
On XFUND_zh dataset, the algorithm reproduction Hmean is as follows.
| Model | Backbone | Task | Config | Hmean | Download link |
|---|---|---|---|---|---|
| VI-LayoutXLM | VI-LayoutXLM-base | SER | ser_vi_layoutxlm_xfund_zh_udml.yml | 93.19% | trained model/inference model |
| VI-LayoutXLM | VI-LayoutXLM-base | RE | re_vi_layoutxlm_xfund_zh_udml.yml | 83.92% | trained model/inference model |
2. Environment¶
Please refer to "Environment Preparation" to configure the PaddleOCR environment, and refer to "Project Clone"to clone the project code.
3. Model Training / Evaluation / Prediction¶
Please refer to KIE tutorial. PaddleOCR has modularized the code structure, so that you only need to replace the configuration file to train different models.
4. Inference and Deployment¶
4.1 Python Inference¶
SER¶
First, we need to export the trained model into inference model. Take VI-LayoutXLM model trained on XFUND_zh as an example (trained model download link). Use the following command to export.
wget https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/ser_vi_layoutxlm_xfund_pretrained.tar
tar -xf ser_vi_layoutxlm_xfund_pretrained.tar
python3 tools/export_model.py -c configs/kie/vi_layoutxlm/ser_vi_layoutxlm_xfund_zh.yml -o Architecture.Backbone.checkpoints=./ser_vi_layoutxlm_xfund_pretrained/best_accuracy Global.save_inference_dir=./inference/ser_vi_layoutxlm_infer
Use the following command to infer using VI-LayoutXLM SER model.
The SER visualization results are saved in the ./output folder by default. The results are as follows.
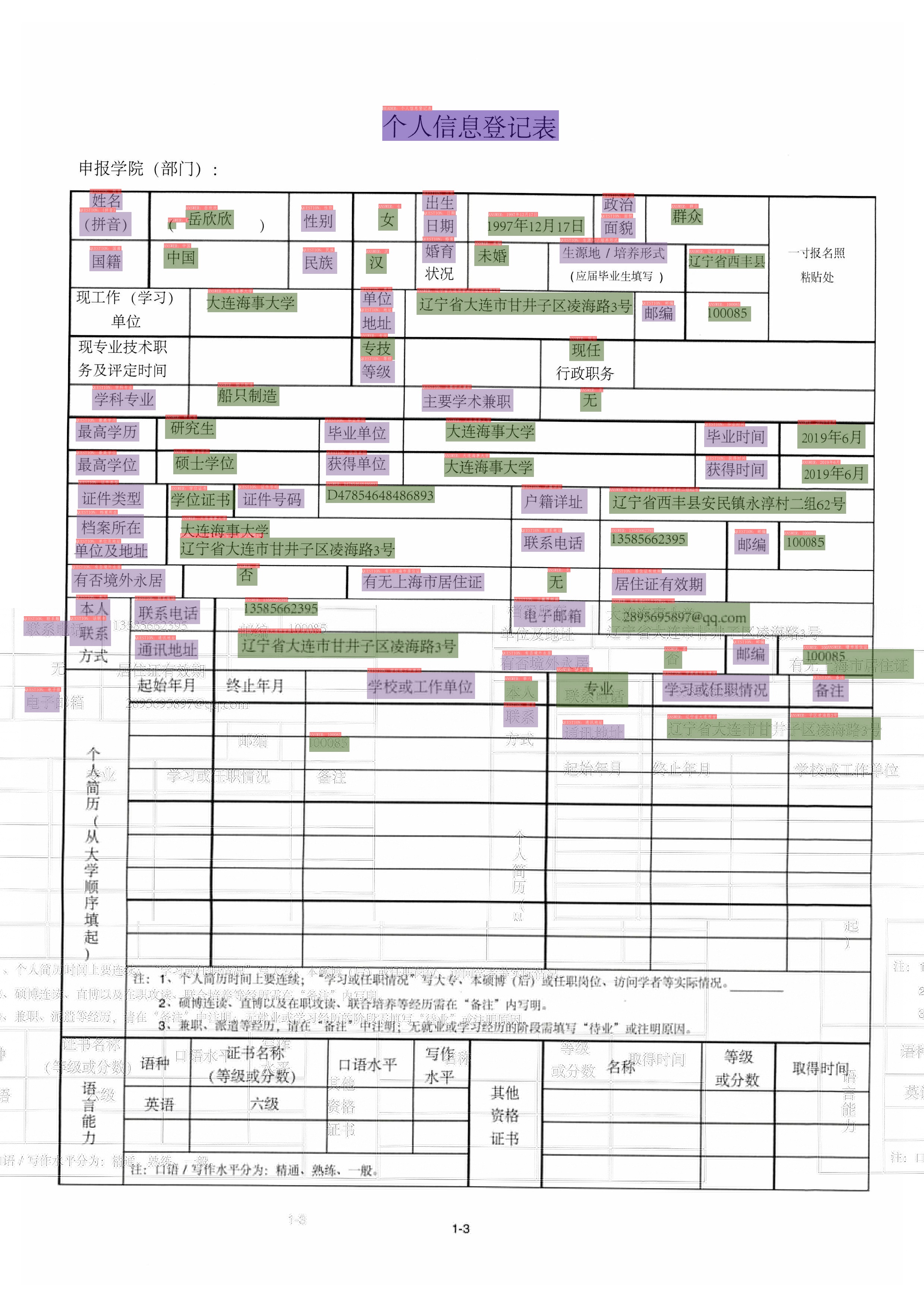
RE¶
First, we need to export the trained model into inference model. Take VI-LayoutXLM model trained on XFUND_zh as an example (trained model download link). Use the following command to export.
wget https://paddleocr.bj.bcebos.com/ppstructure/models/vi_layoutxlm/re_vi_layoutxlm_xfund_pretrained.tar
tar -xf re_vi_layoutxlm_xfund_pretrained.tar
python3 tools/export_model.py -c configs/kie/vi_layoutxlm/re_vi_layoutxlm_xfund_zh.yml -o Architecture.Backbone.checkpoints=./re_vi_layoutxlm_xfund_pretrained/best_accuracy Global.save_inference_dir=./inference/re_vi_layoutxlm_infer
Use the following command to infer using VI-LayoutXLM RE model.
The RE visualization results are saved in the ./output folder by default. The results are as follows.

4.2 C++ Inference¶
Not supported
4.3 Serving¶
Not supported
4.4 More¶
Not supported
5. FAQ¶
Citation¶
@article{DBLP:journals/corr/abs-2104-08836,
author = {Yiheng Xu and
Tengchao Lv and
Lei Cui and
Guoxin Wang and
Yijuan Lu and
Dinei Flor{\^{e}}ncio and
Cha Zhang and
Furu Wei},
title = {LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich
Document Understanding},
journal = {CoRR},
volume = {abs/2104.08836},
year = {2021},
url = {https://arxiv.org/abs/2104.08836},
eprinttype = {arXiv},
eprint = {2104.08836},
timestamp = {Thu, 14 Oct 2021 09:17:23 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2104-08836.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
@article{DBLP:journals/corr/abs-1912-13318,
author = {Yiheng Xu and
Minghao Li and
Lei Cui and
Shaohan Huang and
Furu Wei and
Ming Zhou},
title = {LayoutLM: Pre-training of Text and Layout for Document Image Understanding},
journal = {CoRR},
volume = {abs/1912.13318},
year = {2019},
url = {http://arxiv.org/abs/1912.13318},
eprinttype = {arXiv},
eprint = {1912.13318},
timestamp = {Mon, 01 Jun 2020 16:20:46 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-1912-13318.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
@article{DBLP:journals/corr/abs-2012-14740,
author = {Yang Xu and
Yiheng Xu and
Tengchao Lv and
Lei Cui and
Furu Wei and
Guoxin Wang and
Yijuan Lu and
Dinei A. F. Flor{\^{e}}ncio and
Cha Zhang and
Wanxiang Che and
Min Zhang and
Lidong Zhou},
title = {LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding},
journal = {CoRR},
volume = {abs/2012.14740},
year = {2020},
url = {https://arxiv.org/abs/2012.14740},
eprinttype = {arXiv},
eprint = {2012.14740},
timestamp = {Tue, 27 Jul 2021 09:53:52 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2012-14740.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}