基于PP-OCRv3的PCB字符识别¶
1. 项目介绍¶
印刷电路板(PCB)是电子产品中的核心器件,对于板件质量的测试与监控是生产中必不可少的环节。在一些场景中,通过PCB中信号灯颜色和文字组合可以定位PCB局部模块质量问题,PCB文字识别中存在如下难点:
- 裁剪出的PCB图片宽高比例较小
- 文字区域整体面积也较小
- 包含垂直、水平多种方向文本
针对本场景,PaddleOCR基于全新的PP-OCRv3通过合成数据、微调以及其他场景适配方法完成小字符文本识别任务,满足企业上线要求。PCB检测、识别效果如 图1 所示:

注:欢迎在AIStudio领取免费算力体验线上实训,项目链接: 基于PP-OCRv3实现PCB字符识别
2. 安装说明¶
下载PaddleOCR源码,安装依赖环境。
3. 数据准备¶
我们通过图片合成工具生成 图2 所示的PCB图片,整图只有高25、宽150左右、文字区域高9、宽45左右,包含垂直和水平2种方向的文本:

暂时不开源生成的PCB数据集,但是通过更换背景,通过如下代码生成数据即可:
生成图片参数解释:
num_img:生成图片数量
font_min_size、font_max_size:字体最大、最小尺寸
bg_path:文字区域背景存放路径
det_bg_path:整图背景存放路径
fonts_path:字体路径
corpus_path:语料路径
output_dir:生成图片存储路径
这里生成 100张 相同尺寸和文本的图片,如 图3 所示,方便大家跑通实验。通过如下代码解压数据集:
在生成数据集的时需要生成检测和识别训练需求的格式:
- 文本检测
标注文件格式如下,中间用'\t'分隔:
" 图像文件名 json.dumps编码的图像标注信息"
ch4_test_images/img_61.jpg [{"transcription": "MASA", "points": [[310, 104], [416, 141], [418, 216], [312, 179]]}, {...}]
json.dumps编码前的图像标注信息是包含多个字典的list,字典中的 points 表示文本框的四个点的坐标(x, y),从左上角的点开始顺时针排列。 transcription 表示当前文本框的文字,当其内容为“###”时,表示该文本框无效,在训练时会跳过。
- 文本识别
标注文件的格式如下, txt文件中默认请将图片路径和图片标签用'\t'分割,如用其他方式分割将造成训练报错。
" 图像文件名 图像标注信息 "
train_data/rec/train/word_001.jpg 简单可依赖
train_data/rec/train/word_002.jpg 用科技让复杂的世界更简单
...
4. 文本检测¶
选用飞桨OCR开发套件PaddleOCR中的PP-OCRv3模型进行文本检测和识别。针对检测模型和识别模型,进行了共计9个方面的升级:
-
PP-OCRv3检测模型对PP-OCRv2中的CML协同互学习文本检测蒸馏策略进行了升级,分别针对教师模型和学生模型进行进一步效果优化。其中,在对教师模型优化时,提出了大感受野的PAN结构LK-PAN和引入了DML蒸馏策略;在对学生模型优化时,提出了残差注意力机制的FPN结构RSE-FPN。
-
PP-OCRv3的识别模块是基于文本识别算法SVTR优化。SVTR不再采用RNN结构,通过引入Transformers结构更加有效地挖掘文本行图像的上下文信息,从而提升文本识别能力。PP-OCRv3通过轻量级文本识别网络SVTR_LCNet、Attention损失指导CTC损失训练策略、挖掘文字上下文信息的数据增广策略TextConAug、TextRotNet自监督预训练模型、UDML联合互学习策略、UIM无标注数据挖掘方案,6个方面进行模型加速和效果提升。
更多细节请参考PP-OCRv3技术报告。
我们使用 3种方案 进行检测模型的训练、评估:
- PP-OCRv3英文超轻量检测预训练模型直接评估
- PP-OCRv3英文超轻量检测预训练模型 + 验证集padding直接评估
- PP-OCRv3英文超轻量检测预训练模型 + fine-tune
4.1 预训练模型直接评估¶
我们首先通过PaddleOCR提供的预训练模型在验证集上进行评估,如果评估指标能满足效果,可以直接使用预训练模型,不再需要训练。
使用预训练模型直接评估步骤如下:
1)下载预训练模型¶
PaddleOCR已经提供了PP-OCR系列模型,部分模型展示如下表所示:
| 模型简介 | 模型名称 | 推荐场景 | 检测模型 | 方向分类器 | 识别模型 |
|---|---|---|---|---|---|
| 中英文超轻量PP-OCRv3模型(16.2M) | ch_PP-OCRv3_xx | 移动端&服务器端 | 推理模型 / 训练模型 | 推理模型 / 训练模型 | 推理模型 / 训练模型 |
| 英文超轻量PP-OCRv3模型(13.4M) | en_PP-OCRv3_xx | 移动端&服务器端 | 推理模型 / 训练模型 | 推理模型 / 训练模型 | 推理模型 / 训练模型 |
| 中英文超轻量PP-OCRv2模型(13.0M) | ch_PP-OCRv2_xx | 移动端&服务器端 | 推理模型 / 训练模型 | 推理模型 / 预训练模型 | 推理模型 / 训练模型 |
| 中英文超轻量PP-OCR mobile模型(9.4M) | ch_ppocr_mobile_v2.0_xx | 移动端&服务器端 | 推理模型 / 预训练模型 | 推理模型 / 预训练模型 | 推理模型 / 预训练模型 |
| 中英文通用PP-OCR server模型(143.4M) | ch_ppocr_server_v2.0_xx | 服务器端 | 推理模型 / 预训练模型 | 推理模型 / 预训练模型 | 推理模型 / 预训练模型 |
更多模型下载(包括多语言),可以参考PP-OCR系列模型下载
这里我们使用PP-OCRv3英文超轻量检测模型,下载并解压预训练模型:
模型评估
首先修改配置文件configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml中的以下字段:
然后在验证集上进行评估,具体代码如下:
4.2 预训练模型+验证集padding直接评估¶
考虑到PCB图片比较小,宽度只有25左右、高度只有140-170左右,我们在原图的基础上进行padding,再进行检测评估,padding前后效果对比如 图4 所示:

将图片都padding到300*300大小,因为坐标信息发生了变化,我们同时要修改标注文件,在/home/aistudio/dataset目录里也提供了padding之后的图片,大家也可以尝试训练和评估:
同上,我们需要修改配置文件configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_cml.yml中的以下字段:
将训练完成的模型放置在对应目录下即可完成模型推理
4.3 预训练模型+fine-tune¶
基于预训练模型,在生成的1500图片上进行fine-tune训练和评估,其中train数据1200张,val数据300张,修改配置文件configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml中的以下字段:
执行下面命令启动训练:
模型评估
使用训练好的模型进行评估,更新模型路径Global.checkpoints:
使用训练好的模型进行评估,指标如下所示:
| 序号 | 方案 | hmean | 效果提升 | 实验分析 |
|---|---|---|---|---|
| 1 | PP-OCRv3英文超轻量检测预训练模型 | 64.64% | - | 提供的预训练模型具有泛化能力 |
| 2 | PP-OCRv3英文超轻量检测预训练模型 + 验证集padding | 72.13% | +7.49% | padding可以提升尺寸较小图片的检测效果 |
| 3 | PP-OCRv3英文超轻量检测预训练模型 + fine-tune | 100.00% | +27.87% | fine-tune会提升垂类场景效果 |
注:上述实验结果均是在1500张图片(1200张训练集,300张测试集)上训练、评估的得到,AIstudio只提供了100张数据,所以指标有所差异属于正常,只要策略有效、规律相同即可。
5. 文本识别¶
我们分别使用如下4种方案进行训练、评估:
- 方案1:PP-OCRv3中英文超轻量识别预训练模型直接评估
- 方案2:PP-OCRv3中英文超轻量检测预训练模型 + fine-tune
- 方案3:PP-OCRv3中英文超轻量检测预训练模型 + fine-tune + 公开通用识别数据集
- 方案4:PP-OCRv3中英文超轻量检测预训练模型 + fine-tune + 增加PCB图像数量
5.1 预训练模型直接评估¶
同检测模型,我们首先使用PaddleOCR提供的识别预训练模型在PCB验证集上进行评估。
使用预训练模型直接评估步骤如下:
1)下载预训练模型
我们使用PP-OCRv3中英文超轻量文本识别模型,下载并解压预训练模型:
模型评估
首先修改配置文件configs/det/ch_PP-OCRv3/ch_PP-OCRv2_rec_distillation.yml中的以下字段:
我们使用下载的预训练模型进行评估:
5.2 三种fine-tune方案¶
方案2、3、4训练和评估方式是相同的,因此在我们了解每个技术方案之后,再具体看修改哪些参数是相同,哪些是不同的。
方案介绍:
1) 方案2:预训练模型 + fine-tune
- 在预训练模型的基础上进行fine-tune,使用1500张PCB进行训练和评估,其中训练集1200张,验证集300张。
2) 方案3:预训练模型 + fine-tune + 公开通用识别数据集
- 当识别数据比较少的情况,可以考虑添加公开通用识别数据集。在方案2的基础上,添加公开通用识别数据集,如lsvt、rctw等。
3)方案4:预训练模型 + fine-tune + 增加PCB图像数量
- 如果能够获取足够多真实场景,我们可以通过增加数据量提升模型效果。在方案2的基础上,增加PCB的数量到2W张左右。
参数修改:
接着我们看需要修改的参数,以上方案均需要修改配置文件configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml的参数,修改一次即可:
更换不同的方案每次需要修改的参数:
同时方案3修改以下参数
如 图5 所示:
我们提取Student模型的参数,在PCB数据集上进行fine-tune,可以参考如下代码:
修改参数后,每个方案都执行如下命令启动训练:
使用训练好的模型进行评估,更新模型路径Global.checkpoints:
所有方案评估指标如下:
| 序号 | 方案 | acc | 效果提升 | 实验分析 |
|---|---|---|---|---|
| 1 | PP-OCRv3中英文超轻量识别预训练模型直接评估 | 46.67% | - | 提供的预训练模型具有泛化能力 |
| 2 | PP-OCRv3中英文超轻量识别预训练模型 + fine-tune | 42.02% | -4.65% | 在数据量不足的情况,反而比预训练模型效果低(也可以通过调整超参数再试试) |
| 3 | PP-OCRv3中英文超轻量识别预训练模型 + fine-tune + 公开通用识别数据集 | 77.00% | +30.33% | 在数据量不足的情况下,可以考虑补充公开数据训练 |
| 4 | PP-OCRv3中英文超轻量识别预训练模型 + fine-tune + 增加PCB图像数量 | 99.99% | +22.99% | 如果能获取更多数据量的情况,可以通过增加数据量提升效果 |
注:上述实验结果均是在1500张图片(1200张训练集,300张测试集)、2W张图片、添加公开通用识别数据集上训练、评估的得到,AIstudio只提供了100张数据,所以指标有所差异属于正常,只要策略有效、规律相同即可。
6. 模型导出¶
inference 模型(paddle.jit.save保存的模型) 一般是模型训练,把模型结构和模型参数保存在文件中的固化模型,多用于预测部署场景。 训练过程中保存的模型是checkpoints模型,保存的只有模型的参数,多用于恢复训练等。 与checkpoints模型相比,inference 模型会额外保存模型的结构信息,在预测部署、加速推理上性能优越,灵活方便,适合于实际系统集成。
因为上述模型只训练了1个epoch,因此我们使用训练最优的模型进行预测,存储在/home/aistudio/best_models/目录下,解压即可
结果存储在inference_results目录下,检测如下图所示:

同理,导出识别模型并进行推理。
同检测模型,识别模型也只训练了1个epoch,因此我们使用训练最优的模型进行预测,存储在/home/aistudio/best_models/目录下,解压即可
端到端预测结果存储在det_res_infer文件夹内,结果如下图所示:

7. 端对端评测¶
接下来介绍文本检测+文本识别的端对端指标评估方式。主要分为三步:
1)首先运行tools/infer/predict_system.py,将image_dir改为需要评估的数据文件家,得到保存的结果:
得到保存结果,文本检测识别可视化图保存在det_rec_infer/目录下,预测结果保存在det_rec_infer/system_results.txt中,格式如下:0018.jpg [{"transcription": "E295", "points": [[88, 33], [137, 33], [137, 40], [88, 40]]}]
2)然后将步骤一保存的数据转换为端对端评测需要的数据格式: 修改 tools/end2end/convert_ppocr_label.py中的代码,convert_label函数中设置输入标签路径,Mode,保存标签路径等,对预测数据的GTlabel和预测结果的label格式进行转换。
运行convert_ppocr_label.py:
得到如下结果:
3) 最后,执行端对端评测,运行tools/end2end/eval_end2end.py计算端对端指标,运行方式如下:
使用预训练模型+fine-tune'检测模型、预训练模型 + 2W张PCB图片funetune识别模型,在300张PCB图片上评估得到如下结果,fmeasure为主要关注的指标:
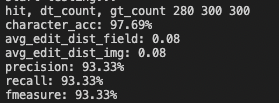
注: 使用上述命令不能跑出该结果,因为数据集不相同,可以更换为自己训练好的模型,按上述流程运行
8. Jetson部署¶
我们只需要以下步骤就可以完成Jetson nano部署模型,简单易操作:
1、在Jetson nano开发版上环境准备:
-
安装PaddlePaddle
-
下载PaddleOCR并安装依赖
2、执行预测
-
将推理模型下载到jetson
-
执行检测、识别、串联预测即可
详细参考流程。
9. 总结¶
检测实验分别使用PP-OCRv3预训练模型在PCB数据集上进行了直接评估、验证集padding、 fine-tune 3种方案,识别实验分别使用PP-OCRv3预训练模型在PCB数据集上进行了直接评估、 fine-tune、添加公开通用识别数据集、增加PCB图片数量4种方案,指标对比如下:
- 检测
| 序号 | 方案 | hmean | 效果提升 | 实验分析 |
|---|---|---|---|---|
| 1 | PP-OCRv3英文超轻量检测预训练模型直接评估 | 64.64% | - | 提供的预训练模型具有泛化能力 |
| 2 | PP-OCRv3英文超轻量检测预训练模型 + 验证集padding直接评估 | 72.13% | +7.49% | padding可以提升尺寸较小图片的检测效果 |
| 3 | PP-OCRv3英文超轻量检测预训练模型 + fine-tune | 100.00% | +27.87% | fine-tune会提升垂类场景效果 |
- 识别
| 序号 | 方案 | acc | 效果提升 | 实验分析 |
|---|---|---|---|---|
| 1 | PP-OCRv3中英文超轻量识别预训练模型直接评估 | 46.67% | - | 提供的预训练模型具有泛化能力 |
| 2 | PP-OCRv3中英文超轻量识别预训练模型 + fine-tune | 42.02% | -4.65% | 在数据量不足的情况,反而比预训练模型效果低(也可以通过调整超参数再试试) |
| 3 | PP-OCRv3中英文超轻量识别预训练模型 + fine-tune + 公开通用识别数据集 | 77.00% | +30.33% | 在数据量不足的情况下,可以考虑补充公开数据训练 |
| 4 | PP-OCRv3中英文超轻量识别预训练模型 + fine-tune + 增加PCB图像数量 | 99.99% | +22.99% | 如果能获取更多数据量的情况,可以通过增加数据量提升效果 |
- 端到端
| det | rec | fmeasure |
|---|---|---|
| PP-OCRv3英文超轻量检测预训练模型 + fine-tune | PP-OCRv3中英文超轻量识别预训练模型 + fine-tune + 增加PCB图像数量 | 93.30% |
结论
PP-OCRv3的检测模型在未经过fine-tune的情况下,在PCB数据集上也有64.64%的精度,说明具有泛化能力。验证集padding之后,精度提升7.5%,在图片尺寸较小的情况,我们可以通过padding的方式提升检测效果。经过 fine-tune 后能够极大的提升检测效果,精度达到100%。
PP-OCRv3的识别模型方案1和方案2对比可以发现,当数据量不足的情况,预训练模型精度可能比fine-tune效果还要高,所以我们可以先尝试预训练模型直接评估。如果在数据量不足的情况下想进一步提升模型效果,可以通过添加公开通用识别数据集,识别效果提升30%,非常有效。最后如果我们能够采集足够多的真实场景数据集,可以通过增加数据量提升模型效果,精度达到99.99%。
更多资源¶
-
更多深度学习知识、产业案例、面试宝典等,请参考:awesome-DeepLearning
-
更多PaddleOCR使用教程,请参考:PaddleOCR
-
飞桨框架相关资料,请参考:飞桨深度学习平台