版面分析模块使用教程¶
一、概述¶
版面分析任务在版面区域检测的基础上,进一步引入了**实例分割**与**阅读顺序预测**能力。通过对输入的文档图像进行分析,不仅能识别各类版面元素(如文字、图表、图像、公式、段落标题、摘要、参考文献等)并输出其边界框,还能同时输出每个区域的**精确轮廓掩码**和**阅读顺序编号**,为文档理解与信息抽取流程提供更完整的结构化信息。
版面分析模块目前支持模型 PP-DocLayoutV3,基于 DETR 架构并以 PPHGNetV2-L 为骨干网络,在实例分割任务之上增加了**阅读顺序预测**分支,可端到端学习文档元素的阅读顺序关系。

二、支持模型列表¶
推理耗时仅包含模型推理耗时,不包含前后处理耗时。
- 版面分析模型,包含25个常见类别:摘要、算法、侧栏文本、图表、目录、行间公式、文档标题、图表标题、页脚、页脚图像、脚注、公式编号、页眉、页眉图像、图像、行内公式、页码、段落标题、参考文献、参考文献内容、印章、表格、文本、竖版文字、图注
| 模型 | 模型下载链接 | GPU推理耗时(ms) A100 GPU |
模型存储大小(MB) | 介绍 |
|---|---|---|---|---|
| PP-DocLayoutV3 | 推理模型/训练模型 | 23.77 | 126 | 基于DETR在包含中英文论文、多栏杂志、报纸、PPT、合同、书本、试卷、研报等场景的自建数据集上训练的版面分析模型,支持25类版面元素的实例分割及阅读顺序预测 |
注:以上精度指标的评估集为自建的版面分析数据集,包含中英文多种文档场景图片。
三、快速集成¶
❗ 在快速集成前,请先安装 PaddleX 的 wheel 包,详细请参考 PaddleX本地安装教程
完成 whl 包的安装后,几行代码即可完成版面分析模块的推理,可以任意切换该模块下的模型,您也可以将版面分析模块中的模型推理集成到您的项目中。运行以下代码前,请您下载示例图片到本地。
{kind=link}
from paddlex import create_model
model_name = "PP-DocLayoutV3"
model = create_model(model_name=model_name)
output = model.predict("layout_analysis_demo.jpg", batch_size=1)
for res in output:
res.print()
res.save_to_img(save_path="./output/")
res.save_to_json(save_path="./output/res.json")
注:PaddleX 支持多个模型托管平台,官方模型默认优先从 HuggingFace 下载。PaddleX 也支持通过环境变量 PADDLE_PDX_MODEL_SOURCE 设置优先使用的托管平台,目前支持 huggingface、aistudio、bos、modelscope,如优先使用 bos:PADDLE_PDX_MODEL_SOURCE="bos";
👉 运行后,得到的结果为:(点击展开)
{'res': {'input_path': 'layout.jpg', 'page_index': None, 'boxes': [{'cls_id': 22, 'label': 'text', 'score': 0.98, 'coordinate': [34.1, 349.8, 358.5, 611.0], 'polygon_points': [[34.1, 349.8], [358.5, 349.8], [358.5, 611.0], [34.1, 611.0]], 'order': 3}, ...]}}
[xmin, ymin, xmax, ymax]
- `polygon_points`:实例分割轮廓点列表,格式为[[x1, y1], [x2, y2], ...]
- `order`:阅读顺序编号,一个整数,表示该区域在文档中的阅读顺序(从0开始)
运行后,save_to_img() 保存的可视化结果如下,图中标注了各区域的类别、置信度、实例分割掩码及阅读顺序编号:

相关方法、参数等说明如下:
create_model实例化版面分析模型(此处以PP-DocLayoutV3为例),具体说明如下:
| 参数 | 参数说明 | 参数类型 | 可选项 | 默认值 |
|---|---|---|---|---|
model_name |
模型名称 | str |
无 | 无 |
model_dir |
模型存储路径 | str |
无 | 无 |
device |
模型推理设备 | str |
支持指定GPU具体卡号,如"gpu:0",其他硬件具体卡号,如"npu:0",CPU如"cpu"。 | gpu:0 |
engine |
推理引擎 | str | None |
可选 paddle、paddle_static、paddle_dynamic、flexible、transformers。 |
None |
engine_config |
推理引擎配置 | dict | None |
不同引擎支持不同字段,请参考推理引擎与配置。 | None |
pp_option |
用于改变运行模式等配置项 | PaddlePredictorOption |
关于推理配置的详细说明,请参考兼容配置(PaddlePredictorOption)。 | None |
img_size |
输入图像大小;如果不指定,将默认使用PaddleX官方模型配置 | int/list/None |
|
None |
threshold |
用于过滤掉低置信度预测结果的阈值;如果不指定,将默认使用PaddleX官方模型配置 | float/dict/None |
|
None |
layout_nms |
是否使用NMS后处理,过滤重叠框;如果不指定,将默认使用PaddleX官方模型配置 | bool/None |
|
None |
layout_unclip_ratio |
检测框的边长缩放倍数;如果不指定,将默认使用PaddleX官方模型配置 | float/list/dict/None |
|
None |
layout_merge_bboxes_mode |
模型输出的检测框的合并处理模式;如果不指定,将默认使用PaddleX官方模型配置 | string/dict/None |
|
None |
-
其中,
model_name必须指定,指定model_name后,默认使用 PaddleX 内置的模型参数,在此基础上,指定model_dir时,使用用户自定义的模型。 -
调用版面分析模型的
predict()方法进行推理预测,predict()方法参数有input、batch_size和threshold,具体说明如下:
| 参数 | 参数说明 | 参数类型 | 可选项 | 默认值 |
|---|---|---|---|---|
input |
待预测数据,支持多种输入类型 | Python Var/str/list |
|
无 |
batch_size |
批大小 | int |
大于0的任意整数 | 1 |
threshold |
用于过滤掉低置信度预测结果的阈值 | float/dict/None |
|
None |
- 对预测结果进行处理,每个样本的预测结果均为对应的Result对象,且支持打印、保存为图片、保存为
json文件的操作:
| 方法 | 方法说明 | 参数 | 参数类型 | 参数说明 | 默认值 |
|---|---|---|---|---|---|
print() |
打印结果到终端 | format_json |
bool |
是否对输出内容进行使用 JSON 缩进格式化 |
True |
indent |
int |
指定缩进级别,以美化输出的 JSON 数据,仅当 format_json 为 True 时有效 |
4 | ||
ensure_ascii |
bool |
控制是否将非 ASCII 字符转义为 Unicode,仅当 format_json 为 True 时有效 |
False |
||
save_to_json() |
将结果保存为json格式的文件 | save_path |
str |
保存的文件路径,当为目录时,保存文件命名与输入文件类型命名一致 | 无 |
indent |
int |
指定缩进级别,以美化输出的 JSON 数据,仅当 format_json 为 True 时有效 |
4 | ||
ensure_ascii |
bool |
控制是否将非 ASCII 字符转义为 Unicode,仅当 format_json 为 True 时有效 |
False |
||
save_to_img() |
将结果保存为图像格式的文件(可视化图像含实例分割掩码与阅读顺序编号) | save_path |
str |
保存的文件路径,当为目录时,保存文件命名与输入文件类型命名一致 | 无 |
- 此外,也支持通过属性获取带结果的可视化图像和预测结果,具体如下:
| 属性 | 属性说明 |
|---|---|
json |
获取预测的json格式的结果 |
img |
获取格式为dict的可视化图像,图像中标注了各区域的类别、置信度、实例分割掩码及阅读顺序编号 |
关于更多 PaddleX 的单模型推理的 API 的使用方法,可以参考PaddleX单模型Python脚本使用说明。
四、二次开发¶
如果你追求更高精度的现有模型,可以使用PaddleX的二次开发能力,开发更好的版面分析模型。在使用PaddleX开发版面分析模型之前,请务必安装PaddleX的Detection相关的模型训练能力,安装过程可以参考PaddleX本地安装教程。
4.1 数据准备¶
在进行模型训练前,需要准备相应任务模块的数据集。PaddleX 针对每一个模块提供了数据校验功能,只有通过数据校验的数据才可以进行模型训练。此外,PaddleX为每一个模块都提供了Demo数据集,您可以基于官方提供的 Demo 数据完成后续的开发。若您希望用私有数据集进行后续的模型训练,可以参考PaddleX目标检测任务模块数据标注教程。
4.1.1 Demo 数据下载¶
您可以参考下面的命令将 Demo 数据集下载到指定文件夹:
cd /path/to/paddlex
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/data/doclayoutv3_examples.tar -P ./dataset
tar -xf ./dataset/doclayoutv3_examples.tar -C ./dataset/
4.1.2 数据集格式说明¶
版面分析模块使用 COCOInstSegDataset 格式,并补充了阅读顺序标注,数据集目录结构如下:
doclayoutv3_examples/
├── images/ # 原始图像目录
│ ├── train_0001.jpg
│ ├── val_0001.jpg
│ └── ...
├── images_mask/ # 用于训练的图像目录(与 images 内容相同)
│ └── ...
└── annotations/
├── instance_train.json # 训练集标注(COCO实例分割格式 + read_order字段)
└── instance_val.json # 验证集标注(COCO实例分割格式 + read_order字段)
标注文件遵循 COCO 实例分割格式,并在每条标注中增加了 read_order 字段,用于记录该区域在文档中的阅读顺序(从0开始的非负整数,同一图像内各标注的 read_order 值应构成连续序列)。示例标注如下:
{
"annotations": [
{
"id": 1,
"image_id": 1,
"category_id": 22,
"bbox": [34.1, 349.8, 324.4, 261.2],
"segmentation": [[34.1, 349.8, 358.5, 349.8, 358.5, 611.0, 34.1, 611.0]],
"area": 84740.0,
"iscrowd": 0,
"read_order": 0
}
]
}
模型支持的25个类别及其ID(与 categories 中的 id 对应)如下:
| 类别名(英文) | 类别含义 |
|---|---|
abstract |
摘要 |
algorithm |
算法 |
aside_text |
侧栏文本 |
chart |
图表 |
content |
目录 |
display_formula |
行间公式 |
doc_title |
文档标题 |
figure_title |
图表标题 |
footer |
页脚 |
footer_image |
页脚图像 |
footnote |
脚注 |
formula_number |
公式编号 |
header |
页眉 |
header_image |
页眉图像 |
image |
图像 |
inline_formula |
行内公式 |
number |
页码 |
paragraph_title |
段落标题 |
reference |
参考文献 |
reference_content |
参考文献内容 |
seal |
印章 |
table |
表格 |
text |
文本 |
vertical_text |
竖版文字 |
vision_footnote |
图注 |
4.1.3 数据校验¶
一行命令即可完成数据校验:
python main.py -c paddlex/configs/modules/layout_analysis/PP-DocLayoutV3.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/doclayoutv3_examples
执行上述命令后,PaddleX 会对数据集进行校验,并统计数据集的基本信息,命令运行成功后会在log中打印出 Check dataset passed ! 信息。校验结果文件保存在 ./output/check_dataset_result.json,同时相关产出会保存在当前目录的 ./output/check_dataset 目录下,产出目录中包括可视化的示例样本图片(标注了实例分割掩码与阅读顺序编号)和样本分布直方图。
👉 校验结果详情(点击展开)
校验结果文件具体内容为:
{
"done_flag": true,
"check_pass": true,
"attributes": {
"num_classes": 11,
"train_samples": 6351,
"train_sample_paths": [
"check_dataset\/demo_img\/train_4141.jpg",
"check_dataset\/demo_img\/train_3699.jpg",
"check_dataset\/demo_img\/train_3764.jpg",
"check_dataset\/demo_img\/train_2279.jpg",
"check_dataset\/demo_img\/train_4647.jpg",
"check_dataset\/demo_img\/train_4442.jpg",
"check_dataset\/demo_img\/train_2006.jpg",
"check_dataset\/demo_img\/train_1463.jpg",
"check_dataset\/demo_img\/train_3275.jpg",
"check_dataset\/demo_img\/train_4509.jpg"
],
"val_samples": 945,
"val_sample_paths": [
"check_dataset\/demo_img\/val_0105.jpg",
"check_dataset\/demo_img\/val_0031.jpg",
"check_dataset\/demo_img\/val_0755.jpg",
"check_dataset\/demo_img\/val_0876.jpg",
"check_dataset\/demo_img\/val_0374.jpg",
"check_dataset\/demo_img\/val_0566.jpg",
"check_dataset\/demo_img\/val_0748.jpg",
"check_dataset\/demo_img\/val_0167.jpg",
"check_dataset\/demo_img\/val_0345.jpg",
"check_dataset\/demo_img\/val_0471.jpg"
],
"read_order_validation": {
"instance_train": {
"total_images": 500,
"valid_images": 500,
"invalid_images": [],
"pass_rate": 1.0
},
"instance_val": {
"total_images": 100,
"valid_images": 100,
"invalid_images": [],
"pass_rate": 1.0
}
}
},
"analysis": {
"histogram": "check_dataset\/histogram.png"
},
"dataset_path": "doclayoutv3_examples",
"show_type": "image",
"dataset_type": "COCOInstSegDataset"
}
上述校验结果中,check_pass 为 True 表示数据集格式符合要求,其他部分指标的说明如下:
attributes.num_classes:该数据集类别数为11;attributes.train_samples:该数据集训练集样本数量;attributes.val_samples:该数据集验证集样本数量;attributes.train_sample_paths:该数据集训练集样本可视化图片相对路径列表;attributes.val_sample_paths:该数据集验证集样本可视化图片相对路径列表;attributes.read_order_validation:read_order字段验证统计,包含训练集和验证集各自的总图像数、通过验证的图像数及通过率。
数据校验还对数据集中所有类别的样本数量分布情况进行了分析,并绘制了分布直方图(histogram.png)。
注意:版面分析数据校验会额外验证每张图像标注中的read_order 字段:
- 完整性:每条标注必须含有
read_order字段; - 类型合法性:
read_order必须为非负整数; - 连续性:同一图像内各标注的
read_order应构成从0开始的连续整数序列(如不连续会给出警告)。
4.1.4 数据集格式转换/数据集划分(可选)¶
在您完成数据校验之后,可以通过**修改配置文件**或是**追加超参数**的方式对数据集的训练/验证比例进行重新划分。
👉 数据集划分详情(点击展开)
(1)数据集格式转换
版面分析暂不支持数据格式转换,请直接使用 COCO 实例分割格式(含 read_order 字段)。
(2)数据集划分
数据集划分的参数可以通过修改配置文件中 CheckDataset 下的字段进行设置:
CheckDataset:
split:
enable: True
train_percent: 90
val_percent: 10
随后执行命令:
python main.py -c paddlex/configs/modules/layout_analysis/PP-DocLayoutV3.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/doclayoutv3_examples
数据划分执行之后,原有标注文件会被在原路径下重命名为 xxx.bak。
以上参数同样支持通过追加命令行参数的方式进行设置:
python main.py -c paddlex/configs/modules/layout_analysis/PP-DocLayoutV3.yaml \
-o Global.mode=check_dataset \
-o Global.dataset_dir=./dataset/doclayoutv3_examples \
-o CheckDataset.split.enable=True \
-o CheckDataset.split.train_percent=90 \
-o CheckDataset.split.val_percent=10
4.2 模型训练¶
一条命令即可完成模型的训练,以训练 PP-DocLayoutV3 为例:
python main.py -c paddlex/configs/modules/layout_analysis/PP-DocLayoutV3.yaml \
-o Global.mode=train \
-o Global.dataset_dir=./dataset/doclayoutv3_examples
需要如下几步:
- 指定模型的
.yaml配置文件路径(此处为PP-DocLayoutV3.yaml) - 指定模式为模型训练:
-o Global.mode=train - 指定训练数据集路径:
-o Global.dataset_dir - 其他相关参数均可通过修改
.yaml配置文件中的Global和Train下的字段来进行设置,也可以通过在命令行中追加参数来进行调整。如指定前2卡gpu训练:-o Global.device=gpu:0,1;设置训练轮次数为10:-o Train.epochs_iters=10。更多可修改的参数及其详细解释,可以查阅模型对应任务模块的配置文件说明PaddleX通用模型配置文件参数说明。
👉 更多说明(点击展开)
- 模型训练过程中,PaddleX 会自动保存模型权重文件,默认为
output,如需指定保存路径,可通过配置文件中-o Global.output字段进行设置。 - PaddleX 对您屏蔽了动态图权重和静态图权重的概念。在模型训练的过程中,会同时产出动态图和静态图的权重,在模型推理时,默认选择静态图权重推理。
-
在完成模型训练后,所有产出保存在指定的输出目录(默认为
./output/)下,通常有以下产出: -
train_result.json:训练结果记录文件,记录了训练任务是否正常完成,以及产出的权重指标、相关文件路径等; train.log:训练日志文件,记录了训练过程中的模型指标变化、loss 变化等;config.yaml:训练配置文件,记录了本次训练的超参数的配置;.pdparams、.pdema、.pdopt.pdstate、.pdiparams、.json:模型权重相关文件,包括网络参数、优化器、EMA、静态图网络参数、静态图网络结构等;- 【注意】:版面分析模型在训练时使用了
order_loss分支(权重系数为50),该损失项用于监督阅读顺序预测,训练日志中可以看到order_loss的变化情况。
4.3 模型评估¶
在完成模型训练后,可以对指定的模型权重文件在验证集上进行评估,验证模型精度。使用 PaddleX 进行模型评估,一条命令即可完成模型的评估:
python main.py -c paddlex/configs/modules/layout_analysis/PP-DocLayoutV3.yaml \
-o Global.mode=evaluate \
-o Global.dataset_dir=./dataset/doclayoutv3_examples
与模型训练类似,需要如下几步:
- 指定模型的
.yaml配置文件路径(此处为PP-DocLayoutV3.yaml) - 指定模式为模型评估:
-o Global.mode=evaluate - 指定验证数据集路径:
-o Global.dataset_dir
其他相关参数均可通过修改 .yaml 配置文件中的 Global 和 Evaluate 下的字段来进行设置,详细请参考PaddleX通用模型配置文件参数说明。
👉 更多说明(点击展开)
在模型评估时,需要指定模型权重文件路径,每个配置文件中都内置了默认的权重保存路径,如需要改变,只需要通过追加命令行参数的形式进行设置即可,如-o Evaluate.weight_path=./output/best_model/best_model/model.pdparams。
在完成模型评估后,会产出 evaluate_result.json,其记录了评估的结果,具体来说,记录了评估任务是否正常完成,以及模型的评估指标。
4.4 模型推理¶
在完成模型的训练和评估后,即可使用训练好的模型权重进行推理预测。在PaddleX中实现模型推理预测可以通过两种方式:命令行和wheel包。
4.4.1 模型推理¶
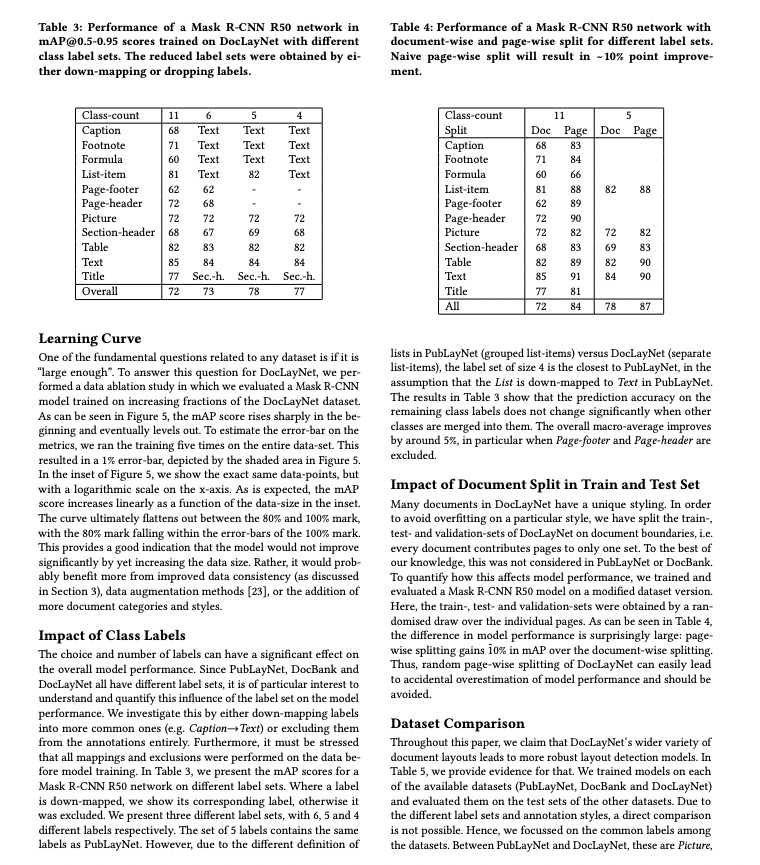
- 通过命令行的方式进行推理预测,只需如下一条命令。运行以下代码前,请您下载示例图片到本地。
{kind=link}
python main.py -c paddlex/configs/modules/layout_analysis/PP-DocLayoutV3.yaml \
-o Global.mode=predict \
-o Predict.model_dir="./output/best_model/inference" \
-o Predict.input="layout.jpg"
与模型训练和评估类似,需要如下几步:
- 指定模型的
.yaml配置文件路径(此处为PP-DocLayoutV3.yaml) - 指定模式为模型推理预测:
-o Global.mode=predict - 指定模型权重路径:
-o Predict.model_dir="./output/best_model/inference" - 指定输入数据路径:
-o Predict.input="..."
其他相关参数均可通过修改 .yaml 配置文件中的 Global 和 Predict 下的字段来进行设置,详细请参考PaddleX通用模型配置文件参数说明。
4.4.2 权重转换¶
本模块支持将 Paddle 动态图权重(.pdparams)转换为 safetensors 格式,方便在 PaddleX 的 paddle_dynamic 和 transformers 引擎中直接加载使用。支持权重转换的模型包括:PP-DocLayoutV3。
- 通过命令行的方式进行权重转换,以
PP-DocLayoutV3模型为例:
python main.py -c paddlex/configs/modules/layout_analysis/PP-DocLayoutV3.yaml \
-o Global.mode=pdparams2safetensors \
-o Pdparams2safetensors.input_path=./path/to/model.pdparams \
-o Pdparams2safetensors.output_dir=./output/safetensors/
- 参数说明:
Global.mode:指定模式为权重转换:pdparams2safetensorsPdparams2safetensors.input_path:输入的.pdparams权重文件路径(也可指定包含该文件的目录)Pdparams2safetensors.output_dir:转换后的safetensors格式模型输出目录
转换完成后,输出目录中将包含 model.safetensors、config.json、preprocess_config.json、inference.yml 等文件,可直接用于推理。
其他相关参数均可通过修改 .yaml 配置文件中的 Pdparams2safetensors 下的字段来进行设置,详细请参考PaddleX通用模型配置文件参数说明。
4.4.3 模型集成¶
模型可以直接集成到PaddleX产线中,也可以直接集成到您自己的项目中。
- 产线集成
版面分析模块可以集成到PaddleX的文档解析产线(PaddleOCR-VL 和 PaddleOCR-VL-1.5)等产线中,只需要替换模型路径即可完成版面分析模块的模型更新。
- 模块集成
您产出的权重可以直接集成到版面分析模块中,可以参考快速集成的 Python 示例代码,只需要将模型替换为你训练的到的模型路径即可。