一、PP-ChatOCRV4简介¶
PP-ChatOCRv4是飞桨特色的文档图像智能分析解决方案,结合了 LLM、MLLM 和 OCR 等技术,一站式解决版面分析、生僻字识别、多页 PDF 文件批量解析、复杂表格识别、印章识别等常见的复杂文档信息抽取难点问题,结合文心大模型将海量数据和知识相融合,信息抽取准确率高且应用广泛。本产线同时提供了灵活的服务化部署方式,支持在多种硬件上部署。不仅如此,本产线也提供了二次开发的能力,您可以基于本产线在您自己的数据集上训练调优,训练后的模型也可以无缝集成。
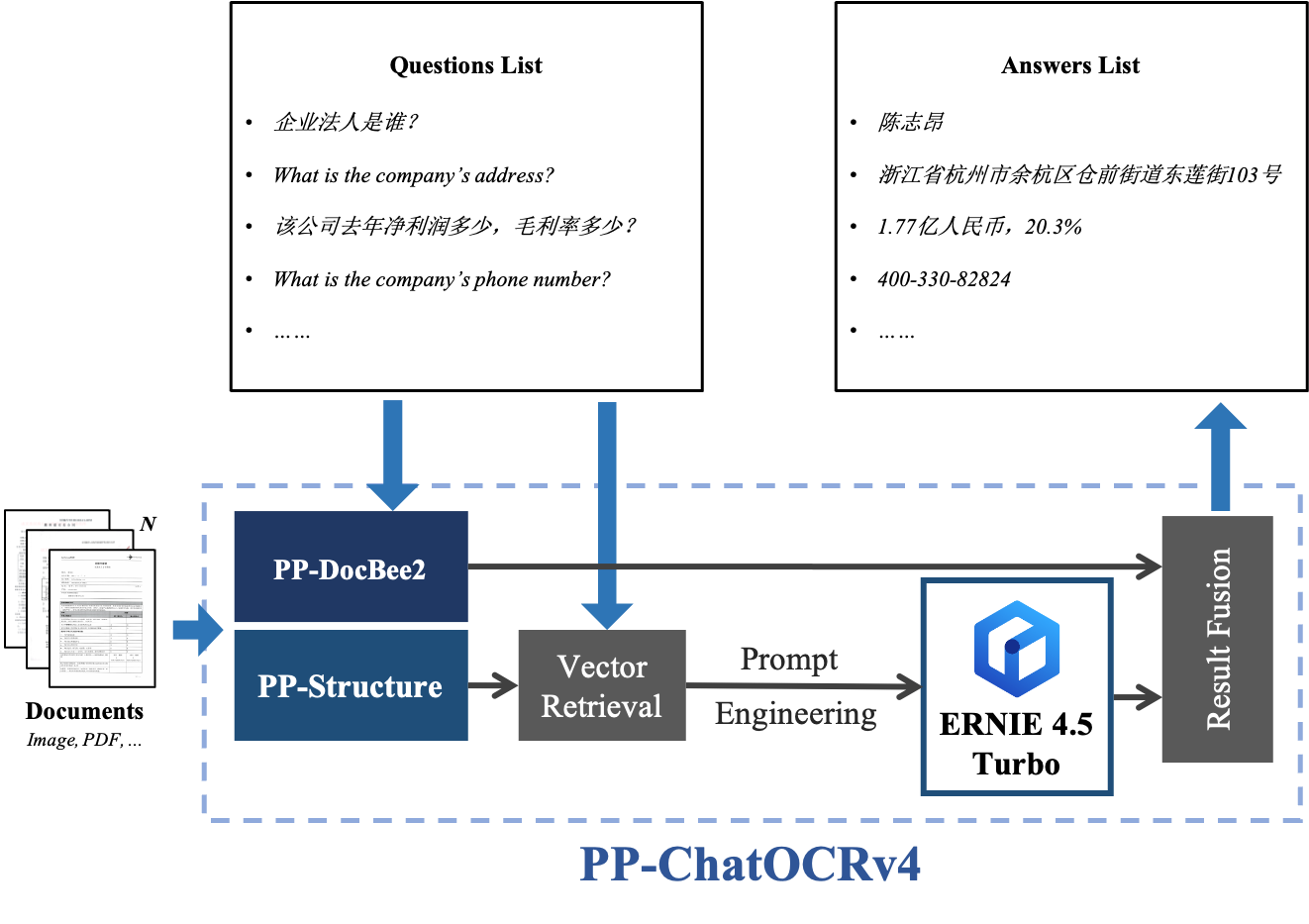
二、关键指标¶
| Solution | Avg Recall |
|---|---|
| GPT-4o | 63.47% |
| PP-ChatOCRv3 | 70.08% |
| Qwen2.5-VL-72B | 80.26% |
| PP-ChatOCRv4 | 85.55% |
三、PP-ChatOCRv4 Demo示例¶
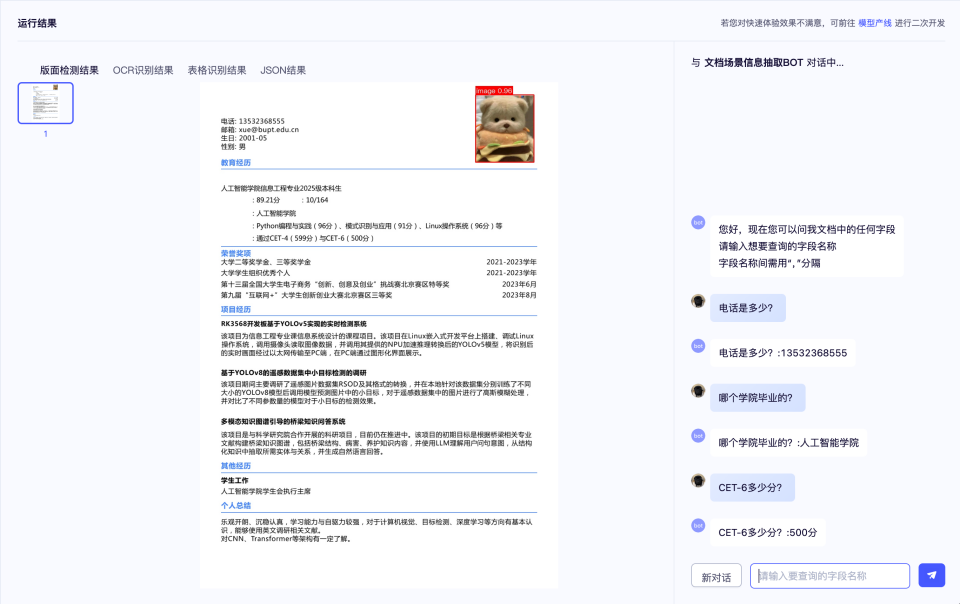
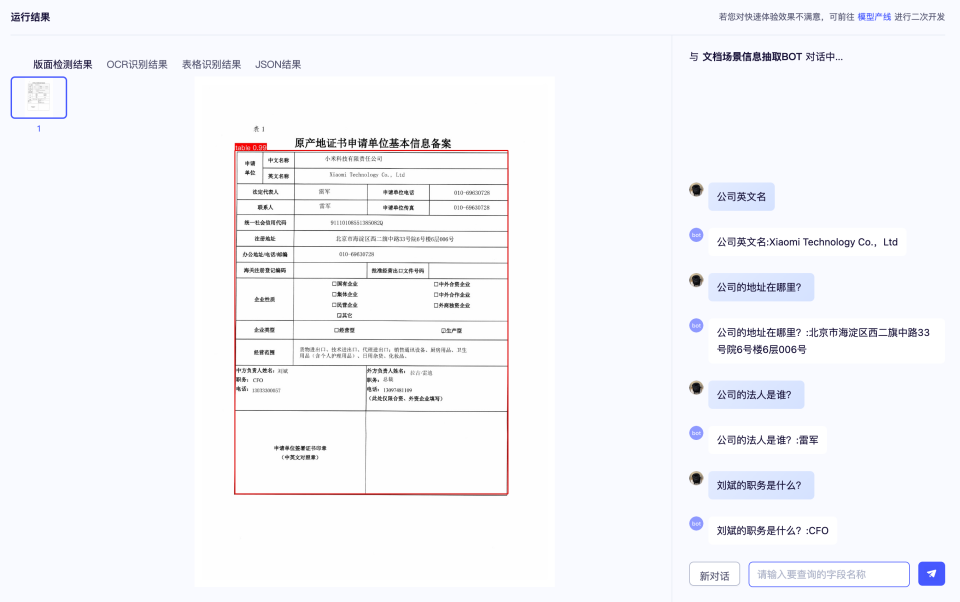
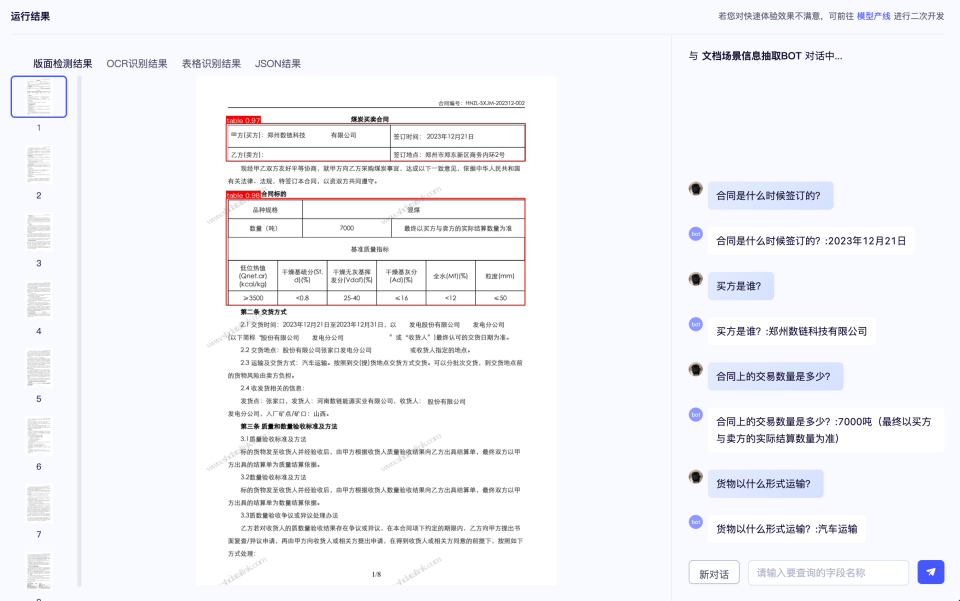
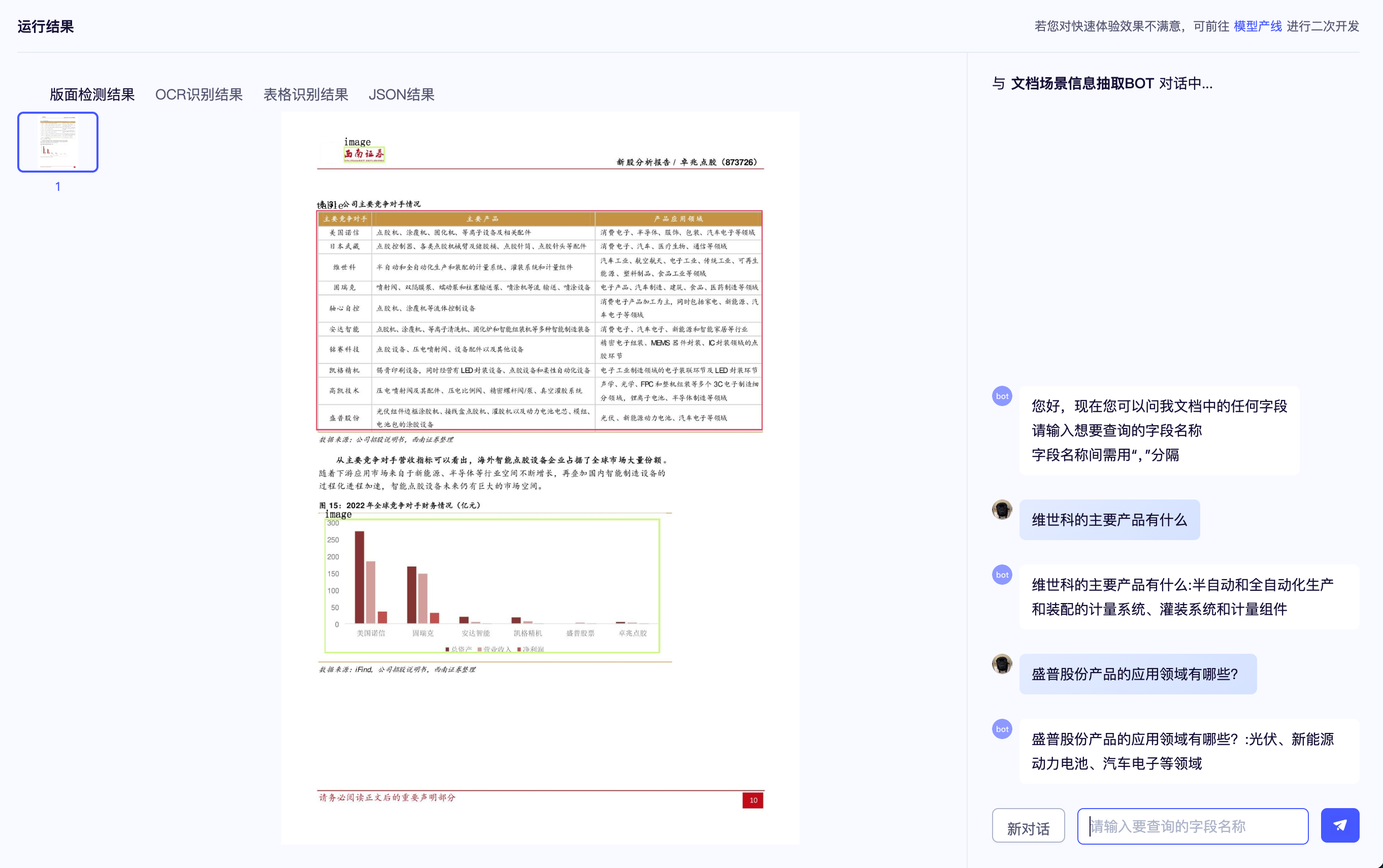
四、使用方法和常见问题¶
- 多模态大模型除了DocBee,是否支持其他多模态模型?
支持,只需在配置文件中进行设置即可。
- 如何降低时延、提升吞吐?
无论使用哪一种服务化部署方案,都可以通过启用高性能推理插件提升模型推理速度,从而降低处理时延。
此外,对于高稳定性服务化部署方案,通过调整服务配置,设置多个实例,也可以充分利用部署机器的资源,有效提升吞吐。
- 如何进一步提升精度?
首先需要检查提取的视觉信息是否正确,如果视觉信息有误,则需要通过可视化视觉预测结果,判断哪个模型效果较差,从而针对性地训练微调较差的模型;如果视觉信息无误,但无法抽取正确信息,则需要根据问答的具体情况调整Prompt。