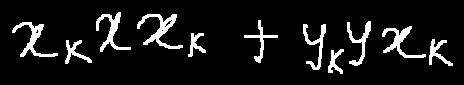手写数学公式识别算法-CAN
1. 算法简介
论文信息:
When Counting Meets HMER: Counting-Aware Network for Handwritten Mathematical Expression Recognition
Bohan Li, Ye Yuan, Dingkang Liang, Xiao Liu, Zhilong Ji, Jinfeng Bai, Wenyu Liu, Xiang Bai
ECCV, 2022
CAN使用CROHME手写公式数据集进行训练,在对应测试集上的精度如下:
2. 环境配置
请先参考《运行环境准备》 配置PaddleOCR运行环境,参考《项目克隆》 克隆项目代码。
3. 模型训练、评估、预测
3.1 模型训练
请参考文本识别训练教程 。PaddleOCR对代码进行了模块化,训练CAN识别模型时需要更换配置文件 为CAN的配置文件 。
启动训练
具体地,在完成数据准备后,便可以启动训练,训练命令如下:
#单卡训练(训练周期长,不建议)
tools/train.py -c configs/rec/rec_d28_can.yml
# 多卡训练,通过--gpus参数指定卡号
-m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/rec/rec_d28_can.yml
注意:
我们提供的数据集,即CROHME数据集
tools/train.py -c configs/rec/rec_d28_can.yml -o Train.dataset.transforms.GrayImageChannelFormat.inverse= False
默认每训练1个epoch(1105次iteration)进行1次评估,若您更改训练的batch_size,或更换数据集,请在训练时作出如下修改
tools/train.py -c configs/rec/rec_d28_can.yml -o Global.eval_batch_step=[ 0 , { length_of_dataset//batch_size}]
3.2 评估
可下载已训练完成的模型文件 ,使用如下命令进行评估:
# 注意将pretrained_model的路径设置为本地路径。若使用自行训练保存的模型,请注意修改路径和文件名为{path/to/weights}/{model_name}。
-m paddle.distributed.launch --gpus '0' tools/eval.py -c configs/rec/rec_d28_can.yml -o Global.pretrained_model= ./rec_d28_can_train/best_accuracy.pdparams
3.3 预测
使用如下命令进行单张图片预测:
# 注意将pretrained_model的路径设置为本地路径。
tools/infer_rec.py -c configs/rec/rec_d28_can.yml -o Architecture.Head.attdecoder.is_train= False Global.infer_img= './doc/datasets/crohme_demo/hme_00.jpg' Global.pretrained_model= ./rec_d28_can_train/best_accuracy.pdparams
# 预测文件夹下所有图像时,可修改infer_img为文件夹,如 Global.infer_img='./doc/datasets/crohme_demo/'。
4. 推理部署
4.1 Python推理
首先将训练得到best模型,转换成inference model。这里以训练完成的模型为例(模型下载地址 ),可以使用如下命令进行转换:
# 注意将pretrained_model的路径设置为本地路径。
tools/export_model.py -c configs/rec/rec_d28_can.yml -o Global.pretrained_model= ./rec_d28_can_train/best_accuracy.pdparams Global.save_inference_dir= ./inference/rec_d28_can/ Architecture.Head.attdecoder.is_train= False
# 目前的静态图模型默认的输出长度最大为36,如果您需要预测更长的序列,请在导出模型时指定其输出序列为合适的值,例如 Architecture.Head.max_text_length=72
注意:
如果您是在自己的数据集上训练的模型,并且调整了字典文件,请注意修改配置文件中的character_dict_path是否是所需要的字典文件。
转换成功后,在目录下有三个文件:
执行如下命令进行模型推理:
tools/infer/predict_rec.py --image_dir= "./doc/datasets/crohme_demo/hme_00.jpg" --rec_algorithm= "CAN" --rec_batch_num= 1 --rec_model_dir= "./inference/rec_d28_can/" --rec_char_dict_path= "./ppocr/utils/dict/latex_symbol_dict.txt"
# 预测文件夹下所有图像时,可修改image_dir为文件夹,如 --image_dir='./doc/datasets/crohme_demo/'。
# 如果您需要在白底黑字的图片上进行预测,请设置 --rec_image_inverse=False
执行命令后,上面图像的预测结果(识别的文本)会打印到屏幕上,示例如下:
of ./doc/imgs_hme/hme_00.jpg:[ 'x _ { k } x x _ { k } + y _ { k } y x _ { k }' , []]
注意 :
需要注意预测图像为黑底白字 ,即手写公式部分为白色,背景为黑色的图片。
在推理时需要设置参数rec_char_dict_path指定字典,如果您修改了字典,请修改该参数为您的字典文件。
如果您修改了预处理方法,需修改tools/infer/predict_rec.py中CAN的预处理为您的预处理方法。
4.2 C++推理部署
由于C++预处理后处理还未支持CAN,所以暂未支持
4.3 Serving服务化部署
暂不支持
4.4 更多推理部署
暂不支持
5. FAQ
CROHME数据集来自于CAN源repo 。
引用
@misc { https://doi.org/10.48550/arxiv.2207.11463 ,
doi = {10.48550/ARXIV.2207.11463} ,
url = {https://arxiv.org/abs/2207.11463} ,
author = {Li, Bohan and Yuan, Ye and Liang, Dingkang and Liu, Xiao and Ji, Zhilong and Bai, Jinfeng and Liu, Wenyu and Bai, Xiang} ,
keywords = {Computer Vision and Pattern Recognition (cs.CV), Artificial Intelligence (cs.AI), FOS: Computer and information sciences, FOS: Computer and information sciences} ,
title = {When Counting Meets HMER: Counting-Aware Network for Handwritten Mathematical Expression Recognition} ,
publisher = {arXiv} ,
year = {2022} ,
copyright = {arXiv.org perpetual, non-exclusive license}
}