Serving
ELASTIC CTR
——百度云分布式训练CTR预估任务和Serving流程一键部署
1. 总体概览
本项目提供了端到端的CTR训练和二次开发的解决方案,主要特点:
- 整体方案在k8s环境一键部署,可快速搭建与验证效果
- 基于Paddle transpiler模式的大规模分布式高速训练
- 训练资源弹性伸缩
- 工业级稀疏参数Serving组件,高并发条件下单位时间吞吐总量是redis的13倍 [注1]
本方案整体流程如下图所示:
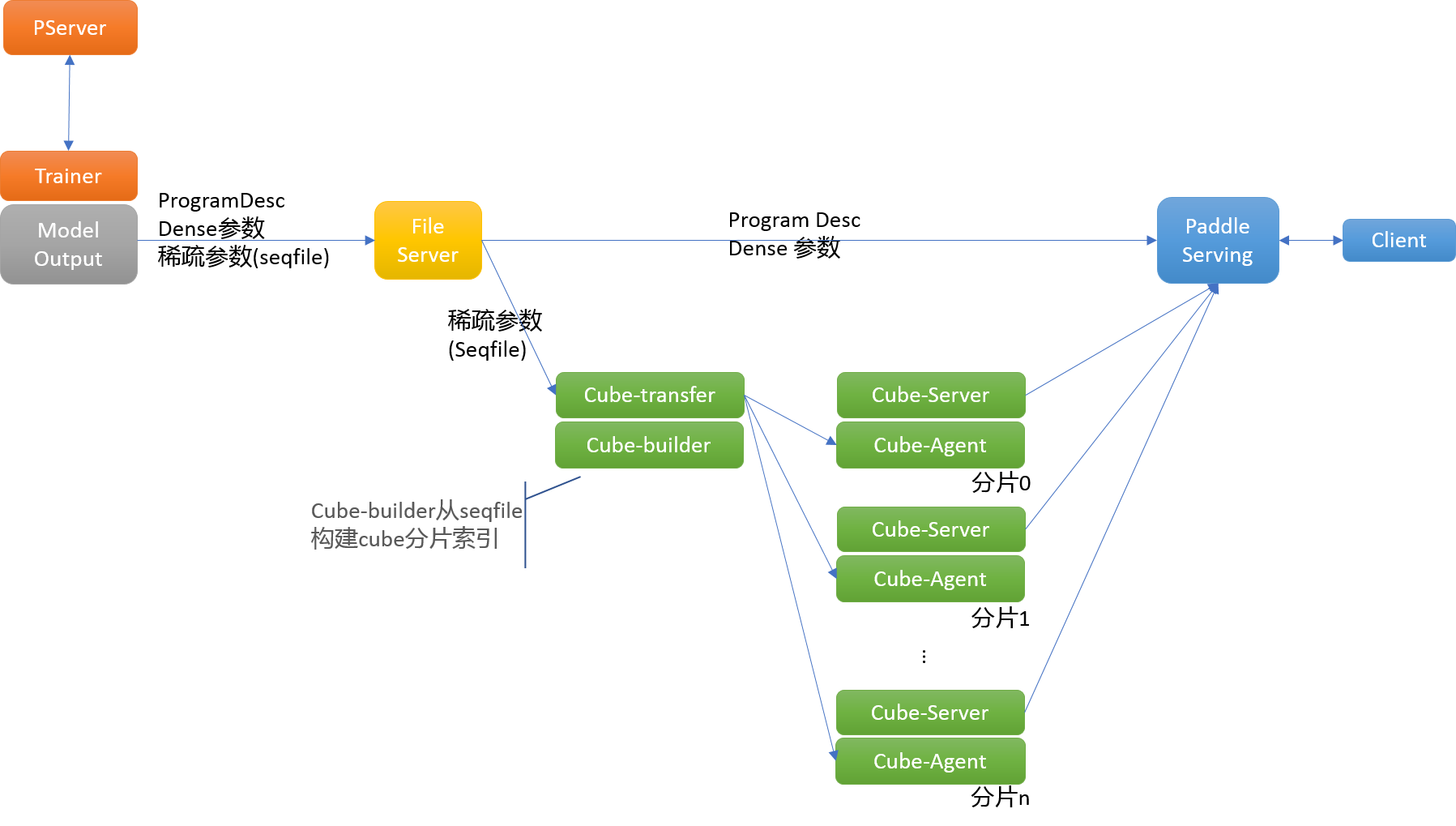
其中:
- trainer/pserver: 训练环节采用PaddlePaddle parameter server模式,对应trainer和pserver角色。分布式训练使用volcano做批量任务管理工具
- file server: 训练产出的模型文件,托管到File Server,供下游模块下载;训练产出的文件包括:ProgramDesc和模型参数,模型参数中最大的embedding由工具转换为seqfile格式,经过一系列流程配送到cube分布式稀疏参数服务,其余模型参数保持不变,配送到Paddle Serving模块
- cube-transfer: 负责监控上游训练作业产出的模型文件(hadoop sequence file)变化,拉取到本地,并调用cube-builder构建cube字典文件;通知cube-agent节点拉取最新的字典文件,并维护各个cube-server上版本一致性
- cube-builder: 负责将训练作业产出的模型文件(hadoop sequence file格式)转换成可以被cube-server加载的字典文件。字典文件具有特定的数据结构,针对尺寸和内存中访问做了高度优化
- Cube-Server: 提供分片kv读写能力的服务节点
- Cube-agent: 与cube-server同机部署,接收cube-transfer下发的字典文件更新命令,拉取数据到本地,通知cube-server进行更新
- Paddle Serving: 加载CTR预估任务模型ProgramDesc和dense参数,提供预测服务
- Client: CTR预估任务的demo客户端
以上组件串联完成从训练到预测部署的所有流程。本文档所提供的一键部署脚本paddle-suite.sh可一键部署上述所有组件。
用户可以参考本部署方案,将基于PaddlePaddle的分布式训练和Serving应用到业务环境,也可以在本方案基础上做功能增强和改进,直接使用。具体的,用户可以:
- 指定数据集的输入和读取方式,来feed不同的数据集和数据集格式;相应的修改Serving代码以适应新模型
- 指定训练的规模,包括参数服务器的数量和训练节点的数量
- 指定Cube参数服务器的分片数量和副本数量
在本文第5节会详细解释以上二次开发的实际操作。
本文主要内容:
第2节 前置需求 指导用户从零开始,在百度云上申请BCE集群,并部署volcano工具。本方案需使用volcano做训练环节批量任务管理工具,目前在百度云上验证通过
第3节 分布式训练+serving方案部署 使用paddle-suite.sh,一键部署分布式训练+serving完整流程;并详细解释脚本每一步的工作和含义
第4节 查看结果 根据各个pod输出,验证一键安装状态
第5节 二次开发 提出本一键部署方案可定制改善的部分,给出具体修改位置等
2. 前置需求
运行本方案前,需要用户已经搭建好k8s集群,并安装好volcano组件。k8s环境部署比较复杂,本文不涉及。百度智能云CCE容器引擎申请后即可使用,仅以百度云上创建k8s为例。
2.1 创建k8s集群
请参考 百度智能云CCE容器引擎帮助文档-创建集群,在百度智能云上建立一个集群,节点配置需要满足如下要求
- CPU核数 > 4
申请容器引擎示例:
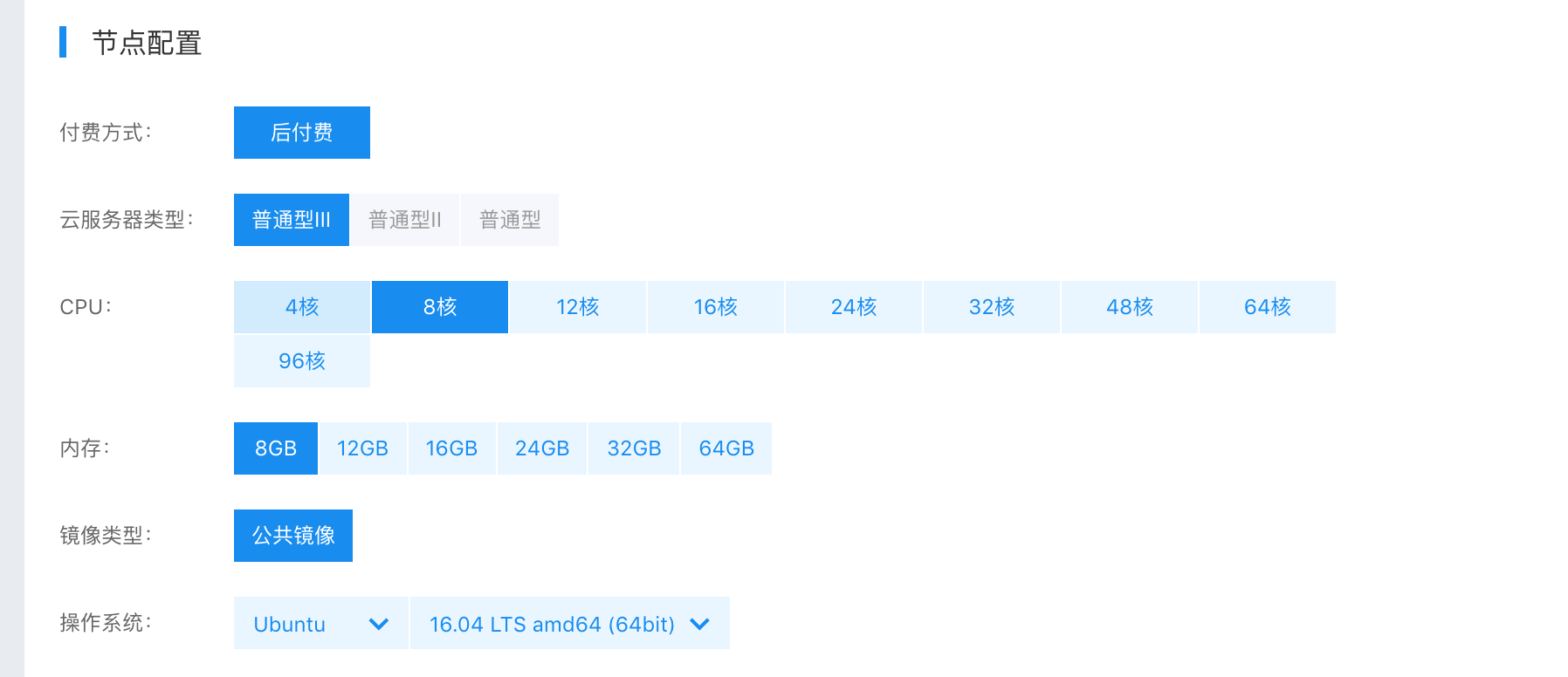
创建完成后,即可参考百度智能云CCE容器引擎帮助文档-查看集群,查看刚刚申请的集群信息。
2.2 如何操作集群
集群的操作可以通过百度云web或者通过kubectl工具进行,推荐用kubectl工具。
对于百度云k8s集群,客户端kubectl需要和百度云上kubernetes版本对应,请参考百度智能云CCE容器引擎帮助文档-kubectl管理配置查看当前所用的kubernetes版本,并参考kubernetes官方文档下载对应版本的kubectrl版本进行安装。
* 注意: 本操作指南给出的操作步骤都是基于linux操作环境的。
-
首先请参考官方安装说明,安装和百度云kubernetes版本对应的的kubectl。
-
配置kubectl,下载集群凭证。在集群界面下载集群配置文件,放在kubectl的默认配置路径(请检查~/.kube目录是否存在,若没有请创建)
$ mv kubectl.conf ~/.kube/config
- 配置完成后,您即可以使用kubectl从本地计算机访问Kubernetes集群
$ kubectl get node
- 关于kubectl的其他信息,可以参考Overview of kubectl。
2.3 设置访问权限
建立分布式任务需要pod间有API互相访问的权限,可以按如下步骤
$ kubectl create rolebinding default-view --clusterrole=view --serviceaccount=default:default --namespace=default
注意: –namespace 指定的default 为创建集群时候的名称
2.4 安装Volcano
我们使用volcano作为训练阶段的批量任务管理工具。关于volcano的详细信息,请参考官方网站的Documentation。
执行以下命令安装volcano到k8s集群:
$ kubectl apply -f https://raw.githubusercontent.com/volcano-sh/volcano/master/installer/volcano-development.yaml
3. 分布式训练+serving方案一键部署
3.1 下载部署方案脚本文件
请将本方案所需所有脚本文件下载到本地
3.2 一键部署
执行以下脚本,一键将所有组件部署到k8s集群。
$ bash paddle-suite.sh
请参考3.3-3.8节验证每一步的安装是否正确,第4节验证训练过程和预测服务结果。
[注意!!!]:以下3.3-3.8节所述内容已经在一键部署脚本中包含,无需手动执行。但为方便理解,将该脚本的每一步执行过程给出说明。
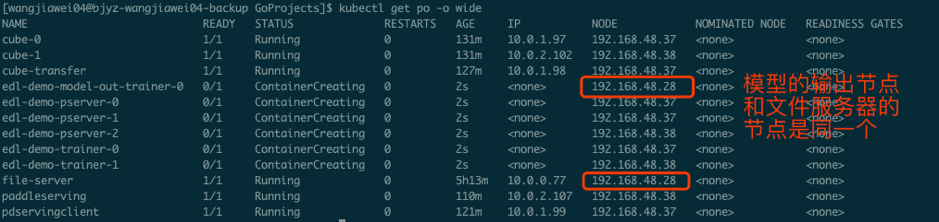
3.3 选择一个node作为输出节点
$ kubectl label nodes $NODE_NAME nodeType=model
这句话的意思是给这个node做一个标记,之后的文件服务和模型产出都被强制分配在这个node上进行,把NAME的一串字符替换 $NODE_NAME即可。
3.4 启动文件服务器
$ kubectl apply -f fileserver.yaml
运行file server的启动脚本kubectl apply -f ftp.yaml,启动文件服务器
验证:通过kubectl get pod命令查看是否file-server这个pod已经running,通过kubectl get service命令查看是否file-server service是否存在:
$ kubectl get pod
$ kubectl get service

3.5 启动Cube稀疏参数服务器
$ kubectl apply -f cube.yaml
验证:通过kubectl get service命令查看是否cube-0和cube-1这2个service存在,则说明cube server/agent启动成功。
$ kubectl get service

注:分片数量可根据稀疏字典大小灵活修改,参考5.3节。
3.6 启动Paddle Serving
$ kubectl apply -f paddleserving.yaml
验证:通过kubectl get pod查看serving pod是否running状态;通过kubectl get service查看paddleserving服务是否存在:
$ kubectl get pod
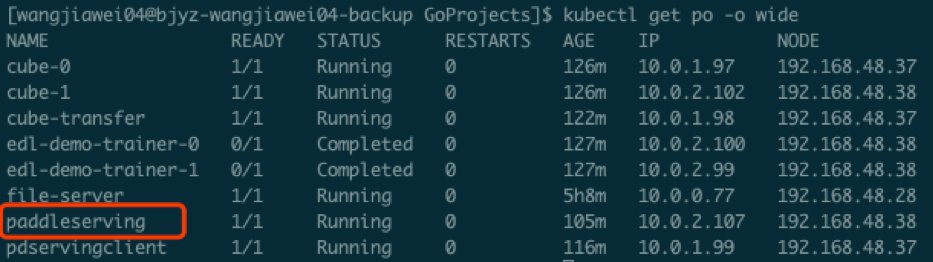
$ kubectl get service

3.7 启动Cube稀疏参数服务器配送工具
$ kubectl apply -f transfer.yaml
验证:通过kubectl get pod查看cube-transfer这个pod是否是running状态
$ kubectl get pod
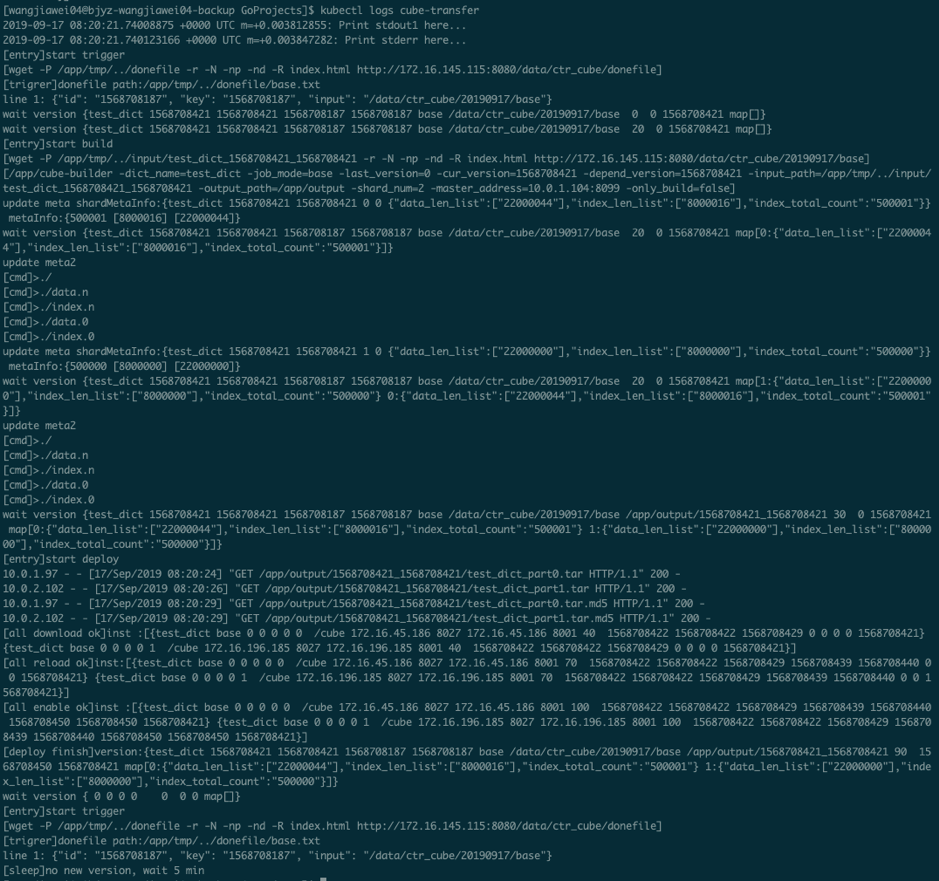
这个cube-transfer配送工具会把训练好的模型从下面要介绍的edl-demo-trainer-0上通过file-server服务拉取到本地,经过cube-builder做格式转换,配送给各个分片cube-server,最终目的是给PaddleServing来进行稀疏参数查询。
在训练任务结束前,cube-transfer会一直等待上游数据产出。直到检测到上游模型文件生成后,开始启动配送。可通过日志观察cube-transfer的工作状态:
$ kubectl logs cube-transfer
如果出现最后wait 5min这样的字样,说明上一轮的模型已经配送成功了,接下来就可以做最后PaddleServing的测试了。
3.8 执行Paddle CTR分布式训练
$ kubectl apply -f ctr.yaml
验证:通过kubectl get pod查看edl-demo-trainer-0/edl-demo-trainer-1, edl-demo-pserver-0/edl-demo-pserver-1/edl-demo-pserver-2, edl-demo-model-out-trainer-0等pod是否是running状态
$ kubectl get pod
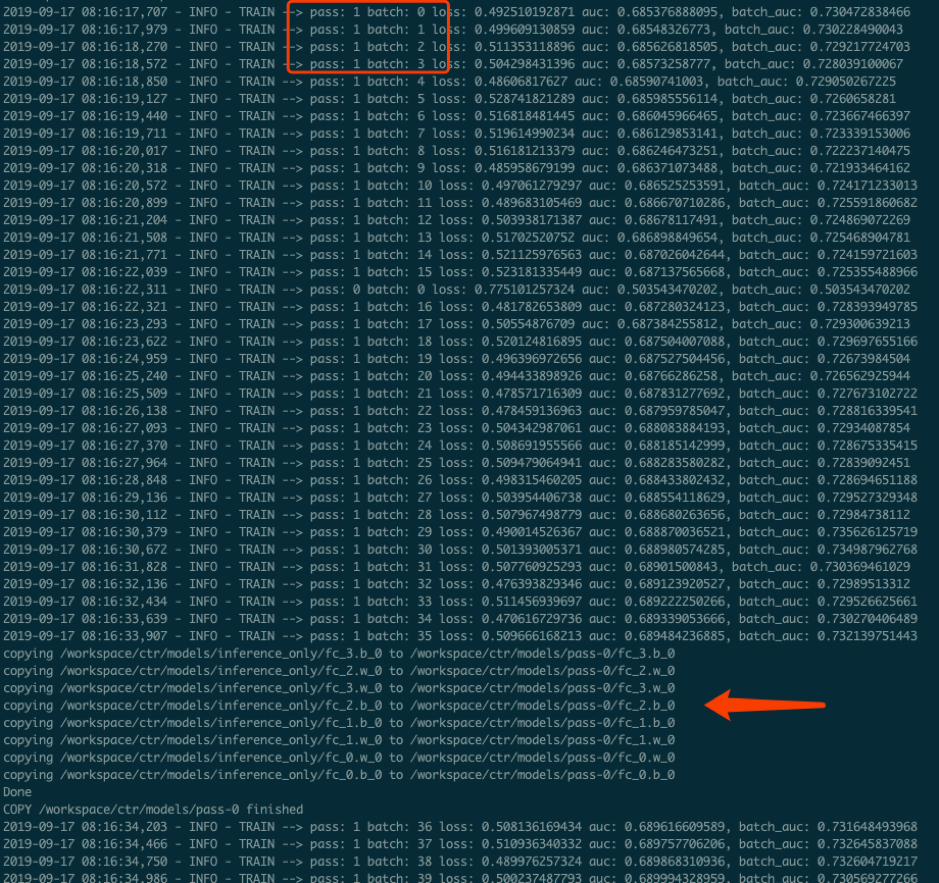
我们可以通过kubectl logs edl-demo-trainer-0来查看训练的进度,如果pass一直为0就继续等待,通常需要大概3-5分钟的之间会完成第一轮pass,这时候就会生成inference_model。
4. 查看结果
4.1 查看训练日志
百度云容器引擎CCE提供了web操作台方便查看pod的运行状态。
本次训练任务将启动3个pserver节点,3个trainer节点。
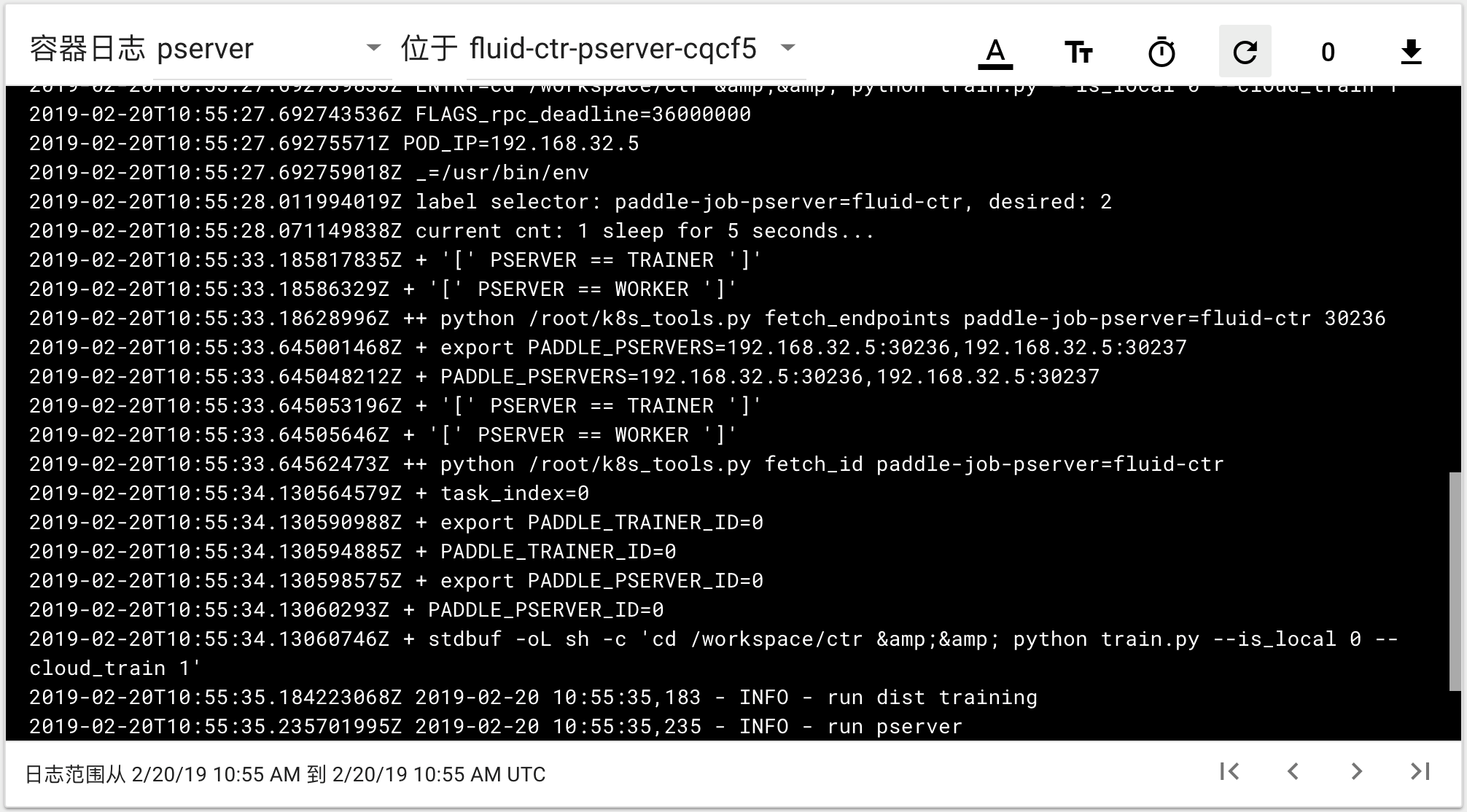
可以通过检查pserver和trainer的log来检查任务运行状态。 Trainer日志示例:
pserver日志示例:
4.2 验证Paddle Serving预测结果
执行
$ kubectl apply -f paddleclient.yaml
用如下命令进入容器内,在/client/ctr_prediction目录下,启动CTR预估任务客户端,并通过日志查看预测结果
# 进入容器
$ kubectl exec -ti pdservingclient /bin/bash
# 此命令在容器内执行
$ bin/ctr_prediction
如果运行正常的话,会在一段时间后退出,紧接着就可以在log/ctr_prediction.INFO的最后几行看到类似于这样的日志
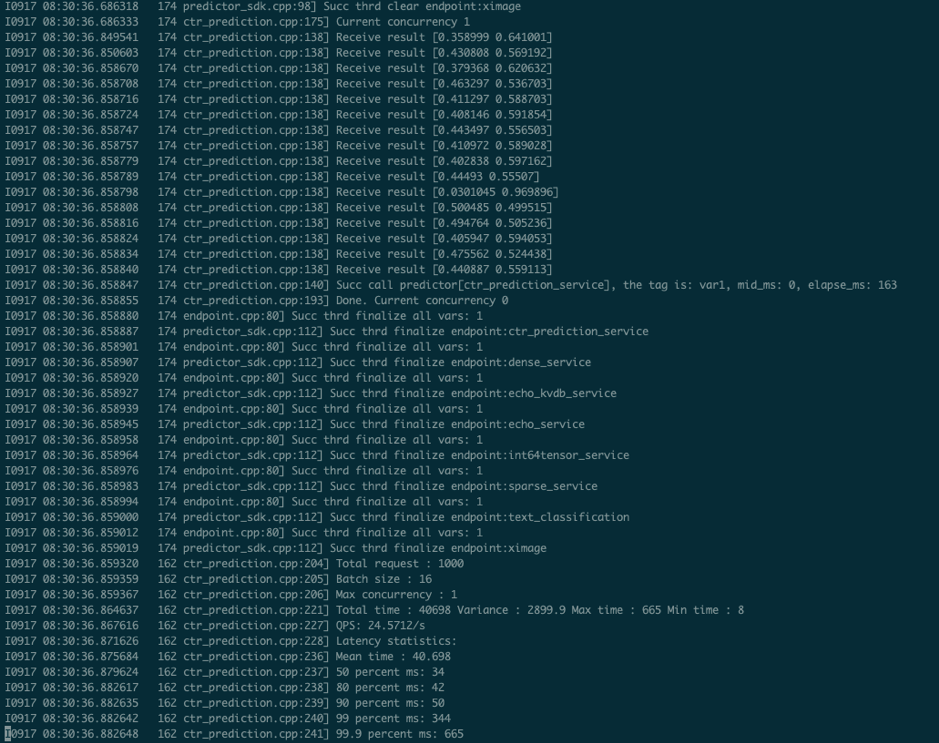
5. 二次开发指南
5.1 指定数据集的输入和读取方式
现有的数据的输入是从edldemo镜像当中的/workspace/ctr/data/download.sh目录进行下载。下载之后会解压在/workspace/ctr/data/raw文件夹当中,包含train.txt和test.txt。所有的数据的每一行通过空格隔开40个属性。
然后在train.py当中给出数据集的读取方式
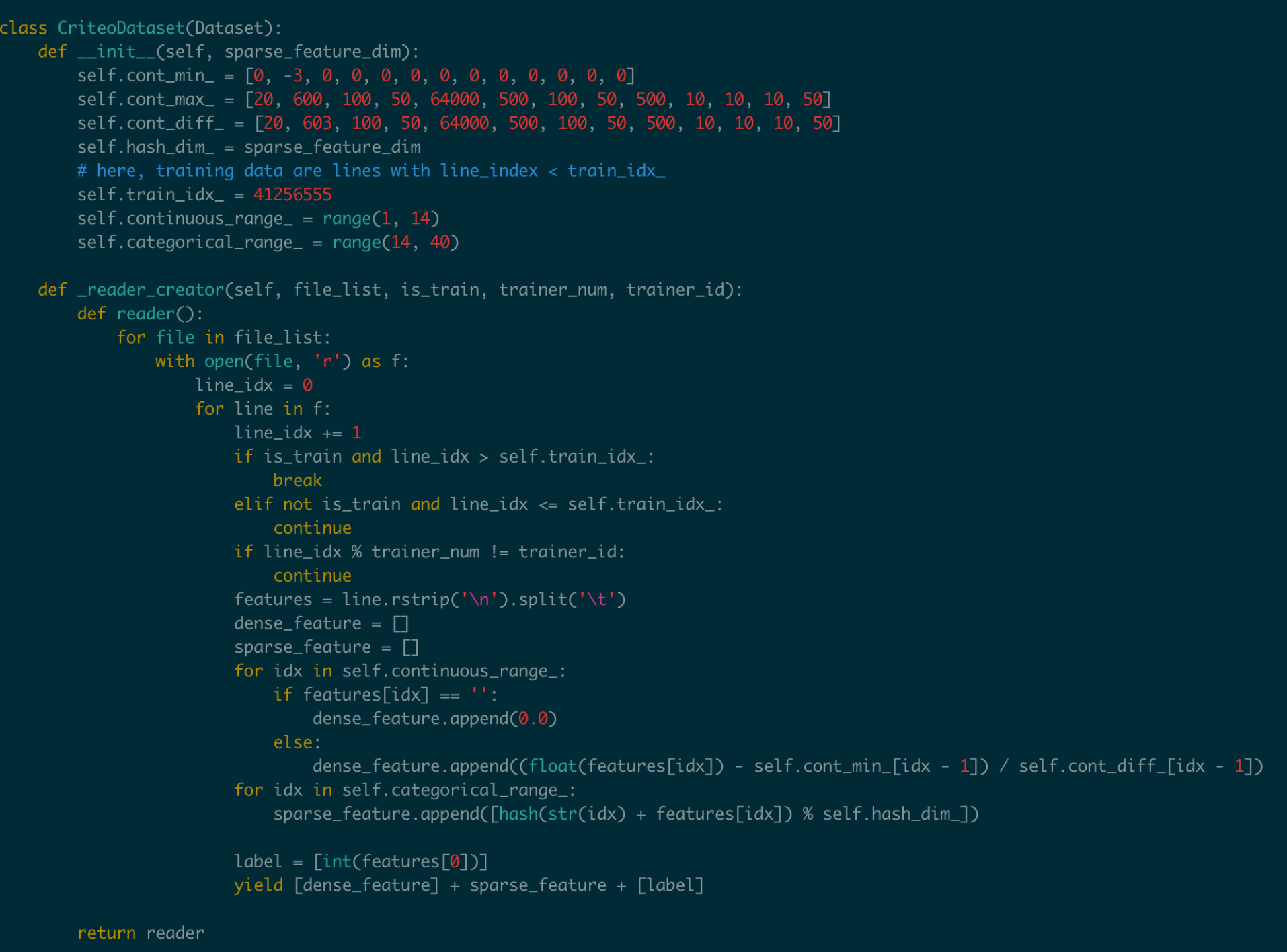
这里面包含了连续数据和离散数据。 连续数据是index [1,14),离散数据是index [14, 40),label是index 0,分别对应最后yield[dense_feature] + sparse_feature +[label]。当离散的数据和连续的数据格式和样例有不同,需要用户在这里进行指定,并且可以在__init__函数当中参考样例的写法对连续数据进行归一化。
对于数据的来源,文章给出的是download.sh从Criteo官方去下载数据集,然后解压后放在raw文件夹。
可以用HDFS/AFS或是其他方式来配送数据集,在启动项中加入相关命令。
在改动之后,记得保存相关的docker镜像并推送到云端
$ docker commit ${DOCKER_CONTAINER_NAME} ${DOCKER_IMAGE_NAME}
$ docker push ${DOCKER_IMAGE_NAME}
也可以在Dockerfile当中进行修改
$ docker build -t ${DOCKER_IMAGE_NAME} .
$ docker push ${DOCKER_IMAGE_NAME}
推荐使用百度云提供的镜像仓库,这里是说明文档推送镜像到镜像仓库
5.2 指定训练规模
在ctr.yaml文件当中,我们会发现这个是在volcano的框架下定义的Job。在Job里面,我们给出了很多Pserver和Trainer的定义,在总体的Job也给出了MinAvailable数量的定义。Pserver和Trainer下面有自己的Replicas,环境变量当中有PSERVER_NUM和TRAINER_MODEL和TRAINER_NUM的数量。通常MinAvailable= PServer Num + Trainer Num,这样我们就可以启动相应的服务。
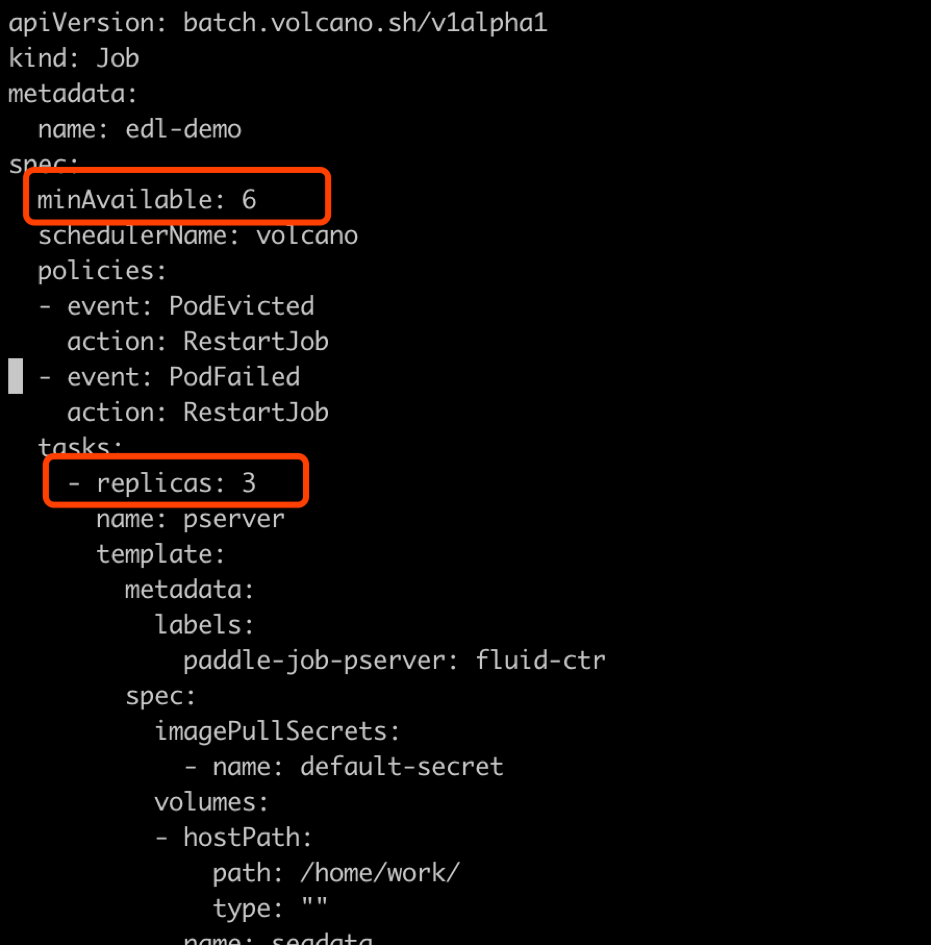
如上图所示,我们需要在min_available处设置合理的数字。例如一个POD占用一个CPU,那么我们就要对集群的总CPU数有一个预估,不要过于接近或事超过集群CPU总和的上限。否则无法满足Volcano的Gang-Schedule机制,就会出现无法分配资源,一直处于Pending的情况。然后第二个红框当中是
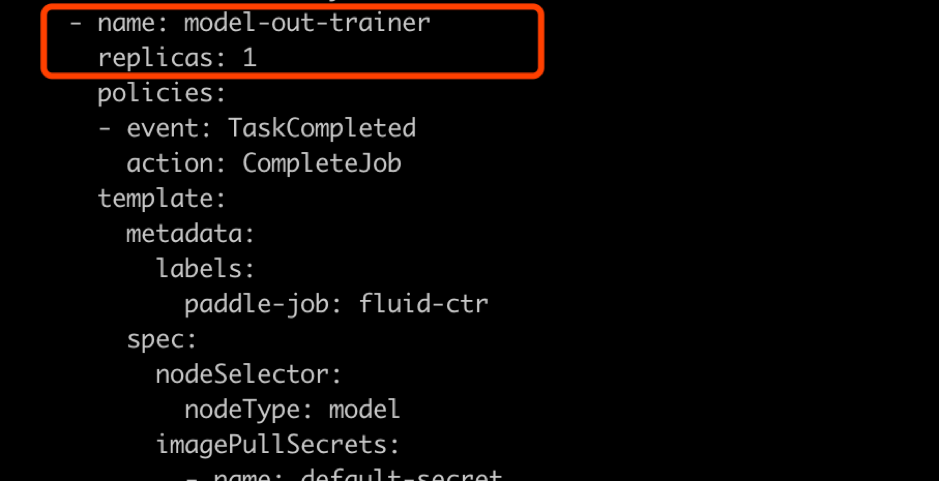
如上图所示,这个部分是用来专门做模型的输出,这里我们不需要做任何的改动,只要保留一个副本就可以。
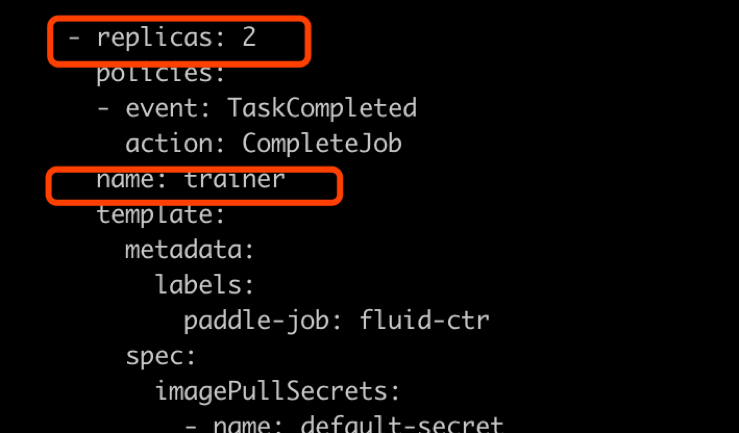
如上图所示
5.3 指定cube参数服务器的分片数量和副本数量
在cube.yaml文件当中,我们可以看到每一个cube的节点的定义,有一个cubeserver pod和cube serverservice。如果我们需要增加cube的副本数和分片数,只需要在yaml文件中复制相关的定义和环境变量即可。
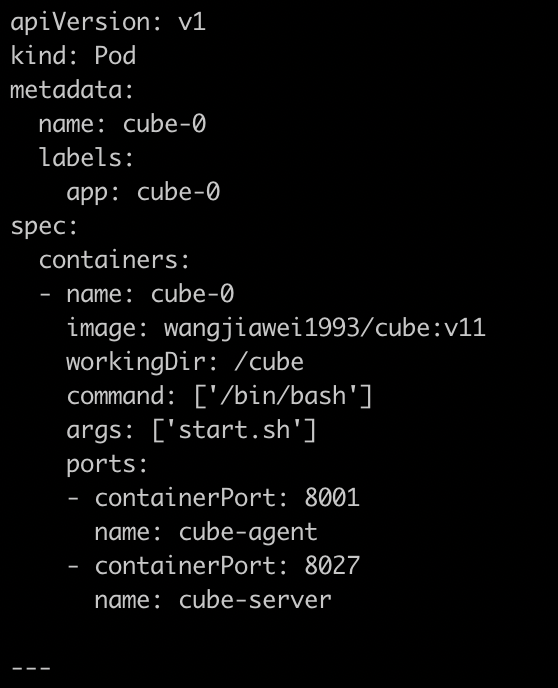
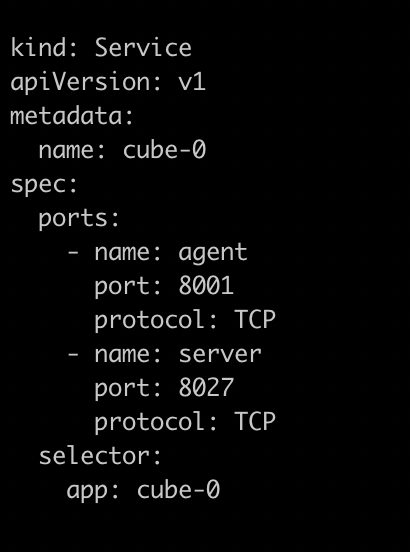
以上两个图片,一个是对cube POD的定义,一个是对cubeSERVICE的定义。如果需要扩展Cube分片数量,可以复制POD和SERVICE的定义,并重命名它们。示例程序给出的是2个分片,复制之后第3个可以命名为cube-2。
5.4 Serving适配新的模型
在本示例中,我们如果按照5.1节的方式,修改了CTR模型训练脚本的feed数据格式,就需要相应修改Serving的代码,以适应新的feed样例字段数量和数据类型。
本部署方案中Paddle Serving的的预测服务和客户端代码分别为:
服务端: https://github.com/PaddlePaddle/Serving/blob/develop/demo-serving/op/ctr_prediction_op.cpp
客户端:https://github.com/PaddlePaddle/Serving/blob/develop/demo-client/src/ctr_prediction.cpp
用户可在此基础上进行修改。
关于Paddle Serving的完整开发模式,可参考Serving从零开始写一个预测服务,以及Paddle Serving的其他文档
注释
注1. Cube和redis性能对比测试环境
Cube和Redis均在百度云环境上部署,测试时只测试单个cube server和redis server节点的性能。
client端和server端分别位于2台独立的云主机,机器间ping延时为0.3ms-0.5ms。
机器配置:Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz 32核
Cube测试环境
测试key 64bit整数,value为10个float (40字节)
首先用本方案一键部署脚本部署完成。
用Paddle Serving的cube客户端SDK,编写测试代码
基本原理,启动k个线程,每个线程访问M次cube server,每次批量获取N个key,总时间加和求平均。
| 并发数 (压测线程数) | batch size | 平均响应时间 (us) | total qps |
|---|---|---|---|
| 1 | 1000 | 1312 | 762 |
| 4 | 1000 | 1496 | 2674 |
| 8 | 1000 | 1585 | 5047 |
| 16 | 1000 | 1866 | 8574 |
| 24 | 1000 | 2236 | 10733 |
| 32 | 1000 | 2602 | 12298 |
Redis测试环境
测试key 1-1000000之间随机整数,value为40字节字符串
server端部署redis-server (latest stable 5.0.6)
client端为基于redisplusplus编写的客户端get_values.cpp
基本原理:启动k个线程,每个线程访问M次redis server,每次用mget批量获取N个key。总时间加和求平均。
调用方法:
$ ./get_values -h 192.168.1.1 -t 3 -r 10000 -b 1000
其中 -h server所在主机名 -t 并发线程数 -r 每线程请求次数 -b 每个mget请求的key个数
| 并发数 (压测线程数) | batch size | 平均响应时间 (us) | total qps |
|---|---|---|---|
| 1 | 1000 | 1643 | 608 |
| 4 | 1000 | 4878 | 819 |
| 8 | 1000 | 9870 | 810 |
| 16 | 1000 | 22177 | 721 |
| 24 | 1000 | 30620 | 783 |
| 32 | 1000 | 37668 | 849 |
RocksDB测试环境
测试key 1-1000000之间随机整数,value为40字节字符串
基本原理:启动k个线程,每个线程访问M次rocksDB,每次用mget批量获取N个key。总时间加和求平均。
| 并发数 (压测线程数) | batch size | 平均响应时间 (us) | total qps |
|---|---|---|---|
| 1 | 1000 | 11345 | 88 |
| 4 | 1000 | 11210 | 357 |
| 8 | 1000 | 11475 | 697 |
| 16 | 1000 | 12822 | 1248 |
| 24 | 1000 | 14220 | 1688 |
| 32 | 1000 | 17256 | 1854 |
测试结论
由于Redis高效的时间驱动模型和全内存操作,在单并发时,redis平均响应时间与cube相差不多% (1643us vs. 1312us)
在扩展性方面,redis受制于单线程模型,随并发数增加,响应时间加倍增加,而总吞吐在1000qps左右即不再上涨;而cube则随着压测并发数增加,总的qps一直上涨,说明cube能够较好处理并发请求,具有良好的扩展能力。
RocksDB在线程数较少的时候,平均响应时间和qps慢于Redis,但是在16以及更多线程的测试当中,RocksDB提供了更快的响应时间和更大的qps。