Combining Differentiable PDE Solvers and Graph Neural Networks for Fluid Flow Prediction¶
# only linux
wget -nc https://paddle-org.bj.bcebos.com/paddlescience/datasets/CFDGCN/data.zip
unzip data.zip
wget -nc https://paddle-org.bj.bcebos.com/paddlescience/datasets/CFDGCN/meshes.tar
tar -xvf meshes.tar
wget -nc https://paddle-org.bj.bcebos.com/paddlescience/datasets/CFDGCN/SU2Bin.tgz
tar -zxvf SU2Bin.tgz
# set BATCH_SIZE = number of cpu cores
export BATCH_SIZE=4
# prediction experiments
mpirun -np $((BATCH_SIZE+1)) python cfdgcn.py \
TRAIN.batch_size=$((BATCH_SIZE)) > /dev/null
# generalization experiments
mpirun -np $((BATCH_SIZE+1)) python cfdgcn.py \
TRAIN.batch_size=$((BATCH_SIZE)) \
TRAIN_DATA_DIR="./data/NACA0012_machsplit_noshock/outputs_train" \
TRAIN_MESH_GRAPH_PATH="./data/NACA0012_machsplit_noshock/mesh_fine. su2" \
EVAL_DATA_DIR="./data/NACA0012_machsplit_noshock/outputs_test" \
EVAL_MESH_GRAPH_PATH="./data/NACA0012_machsplit_noshock/mesh_fine.su2" \
> /dev/null
1. 背景简介¶
近年来,深度学习在计算机视觉和自然语言处理方面的成功应用,促使人们探索人工智能在科学计算领域的应用,尤其是在计算流体力学(CFD)领域的应用。
流体是非常复杂的物理系统,流体的行为由 Navier-Stokes 方程控制。基于网格的有限体积或有限元模拟方法是 CFD 中广泛使用的数值方法。计算流体动力学研究的物理问题往往非常复杂,通常需要大量的计算资源才能求出问题的解,因此需要在求解精度和计算成本之间进行权衡。为了进行数值模拟,计算域通常被网格离散化,由于网格具有良好的几何和物理问题表示能力,同时和图结构相契合,所以这篇文章的作者使用图神经网络,通过训练 CFD 仿真数据,构建了一种数据驱动模型来进行流场预测。
2. 问题定义¶
作者提出了一种基于图神经网络的 CFD 计算模型,称为 CFD-GCN (Computational fluid dynamics - Graph convolution network),该模型是一种混合的图神经网络,它将传统的图卷积网络与粗分辨率的 CFD 模拟器相结合,不仅可以大幅度加速 CFD 预测,还可以很好地泛化到新的场景,与此同时,模型的预测效果远远优于单独的粗分辨率 CFD 的模拟效果。
下图为该方法的网络结构图,网络有两个主要部件:GCN 图神经网络以及 SU2 流体模拟器。网络在两个不同的图上运行,两个图分别是细网格的图和粗网格的图。网络首先在粗网格上运行 CFD 模拟,同时使用 GCN 处理细网格的图。然后,对模拟结果进行上采样,并将结果与 GCN 的中间输出连接起来。最后,模型将额外的 GCN 层应用于这些连接特征,预测所需的输出值。
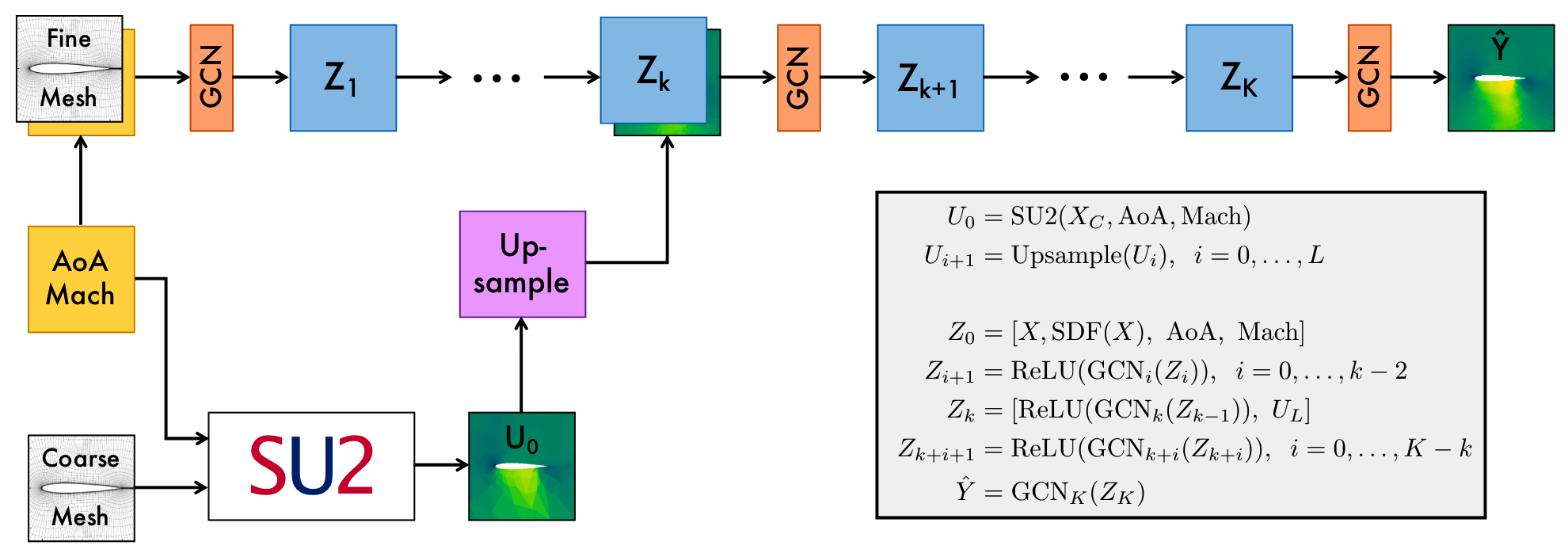
3. 问题求解¶
接下来开始讲解如何将问题一步一步地转化为 PaddleScience 代码,用深度学习的方法求解该问题。 为了快速理解 PaddleScience,接下来仅对模型构建、方程构建、计算域构建等关键步骤进行阐述,而其余细节请参考 API文档。
注意事项
本案例运行前需通过 pip install pgl==2.2.6 mpi4py 命令,安装 Paddle Graph Learning 图学习工具和 Mpi4py MPI python接口库。
由于新版本的 Paddle 依赖的 python 版本较高,pgl 与 mpi4py 的安装可能会出现问题,建议使用AI Studio快速体验,项目中已经配置好运行环境。
3.1 数据集下载¶
该案例使用的机翼数据集 Airfoil来自 de Avila Belbute-Peres 等人,其中翼型数据集采用 NACA0012 翼型,包括 train, test 以及对应的网格数据 mesh_fine;圆柱数据集是原作者利用软件计算的 CFD 算例。
执行以下命令,下载并解压数据集。
wget -nc https://paddle-org.bj.bcebos.com/paddlescience/datasets/CFDGCN/data.zip
unzip data.zip
wget -nc https://paddle-org.bj.bcebos.com/paddlescience/datasets/CFDGCN/meshes.tar
tar -xvf meshes.tar
3.2 SU2 预编译库安装¶
SU2 流体模拟器以预编译库的形式嵌入在网络中,我们需要下载并设置环境变量。
执行以下命令,下载并解压预编译库。
wget -nc -P https://paddle-org.bj.bcebos.com/paddlescience/datasets/CFDGCN/SU2Bin.tgz
tar -zxvf SU2Bin.tgz
预编译库下载完成后,设置 SU2 的环境变量。
export SU2_RUN=/absolute_path/to/SU2Bin/
export SU2_HOME=/absolute_path/to/SU2Bin/
export PATH=$PATH:$SU2_RUN
export PYTHONPATH=$PYTHONPATH:$SU2_RUN
3.3 模型构建¶
在本问题中,我们使用神经网络 CFDGCN 作为模型,其接收图结构数据,输出预测结果。
为了在计算时,准确快速地访问具体变量的值,我们在这里指定网络模型的输入变量名是 ("input", ),输出变量名是 ("pred", ),这些命名与后续代码保持一致。
3.4 约束构建¶
在本案例中,我们使用监督数据集对模型进行训练,因此需要构建监督约束。
在定义约束之前,我们需要指定数据集的路径等相关配置,将这些信息存放到对应的 YAML 文件中,如下所示。
接着定义训练损失函数的计算过程,如下所示。
最后构建监督约束,如下所示。
3.5 超参数设定¶
设置训练轮数等参数,如下所示。
3.6 优化器构建¶
训练过程会调用优化器来更新模型参数,此处选择较为常用的 Adam 优化器,并使用固定的 5e-4 作为学习率。
3.7 评估器构建¶
在训练过程中通常会按一定轮数间隔,用验证集(测试集)评估当前模型的训练情况,因此使用 ppsci.validate.SupervisedValidator 构建评估器,构建过程与 约束构建 类似,只需把数据目录改为测试集的目录,并在配置文件中设置 EVAL.batch_size=1 即可。
评估指标为预测结果和真实结果的 RMSE 值,因此需自定义指标计算函数,如下所示。
评估指标为预测结果和真实结果的 RMSE 值,因此需自定义指标计算函数,如下所示。
3.8 模型训练¶
完成上述设置之后,只需要将上述实例化的对象按顺序传递给 ppsci.solver.Solver,然后启动训练。
3.9 结果可视化¶
训练完毕之后程序会对测试集中的数据进行预测,并以图片的形式对结果进行可视化,如下所示。
4. 完整代码¶
| cfdgcn.py | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 | |
5. 结果展示¶
下方展示了模型对计算域中每个点的压力\(p(x,y)\)、x(水平)方向流速\(u(x,y)\)、y(垂直)方向流速\(v(x,y)\)的预测结果与参考结果。
可以看到模型预测结果与真实结果基本一致,模型泛化效果良好。