PLAS
Introduction
We propose PLAS (Pluggable Lightweight Attention for Sparsity), an improvement over MoBA. Specifically, we adopt an MoE-inspired structure that partitions KV into multiple blocks and introduces a learnable MLP layer to adaptively select important blocks. PLAS can be directly applied during post-training, where only the MLP weights are learnable, and the original model weights remain unchanged.
Compared to NSA/MoBA, our PLAS offers greater scalability and pluggability. It does not require modifying the traditional attention architecture or interfering with model weight training during pre-training or post-training. Only a small amount of training for the MLP layer is needed at the final stage to achieve nearly lossless accuracy. Since NSA/MoBA updates the entire model weights, it inevitably affects performance on short texts—even though it automatically switches to full attention when the input length is shorter than BlockSize × Top-K. In contrast, our PLAS can achieve truly equivalent full attention to the original model in short-text scenarios.
In terms of training efficiency, the training cost is very low because only the MLP weight needs to be updated. For inference performance, when the input length is 128K, Block Size = 128, and Top-K = 55, PLAS achieves a 386% speedup compared to Flash Attention 3.
Method
Training
Following the approaches of NSA and MoBA, we partition the KV into multiple blocks. During both the prefill and decode stages, instead of performing attention computation over all KV, we dynamically select the top-K blocks with the highest attention scores for each query token, thereby enabling efficient sparse attention computation.
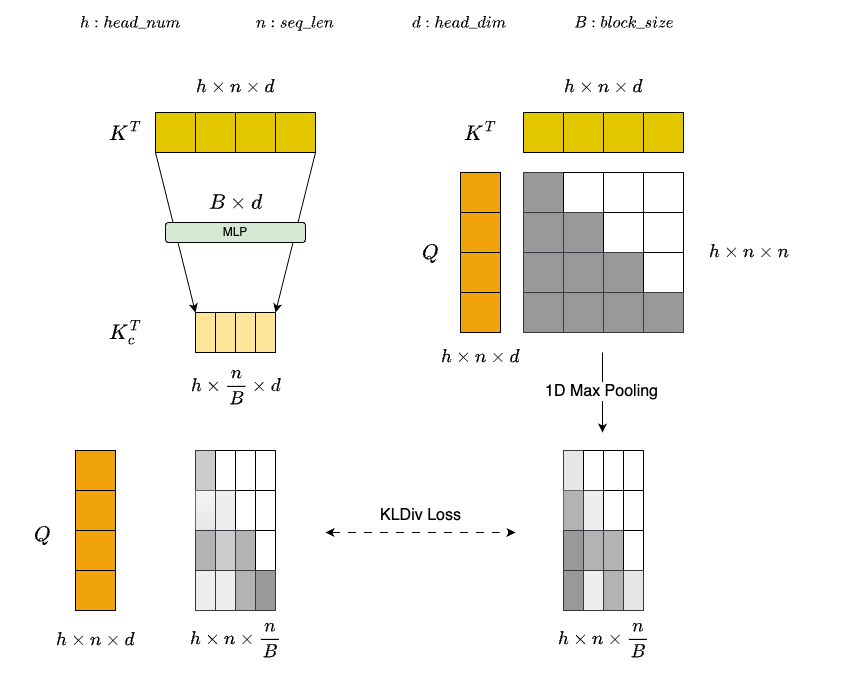
- Attention Gate Module: As illustrated in the figure above, to estimate the importance of each block with low computational overhead, we design a lightweight attention gate module. This module first compresses each K block via a MLP layer to generate a representative low-dimensional representation: $K_c^T=W_{kp}K^T$, where $W_{kp}$ denotes the MLP layer weights. Compared to directly applying mean pooling, the learnable MLP can more effectively capture semantic relationships and importance distributions among different tokens, thereby providing a refined representation of each block. After obtaining the compressed representation $K_c$, the importance of each query token with respect to each block is estimated via: $Softmax(Q\cdot K_c^T)$. To enhance the discriminative ability of the MLP layer, we use the full attention result after 1D max pooling $1DMaxPooling(Softmax(Q \cdot K^T))$ as the ground truth. By minimizing the distribution divergence between the two, the MLP layer is guided to learn feature representations that better align with the true attention distribution.
- Training Data: Benefiting from the efficiency of both the model architecture and the training paradigm, our approach achieves near-lossless precision with only 1B tokens used for training. The training data is sourced from an internally constructed mixed corpus containing both long and short texts, thereby enhancing the module’s adaptability to varying sequence lengths.
- Other: We observe that the final decode layer has a significant impact on the overall model accuracy. Therefore, during training, we exclude this layer from sparse attention computation and revert to full attention for this layer during inference.
Inference
During sparse attention computation, each query token may dynamically select different KV blocks, leading to highly irregular memory access patterns in HBM. It is feasible to simply process each query token separately, but it will lead to excessively fine-grained computing, which cannot make full use of the tensor core, thus significantly reducing the GPU computing efficiency.
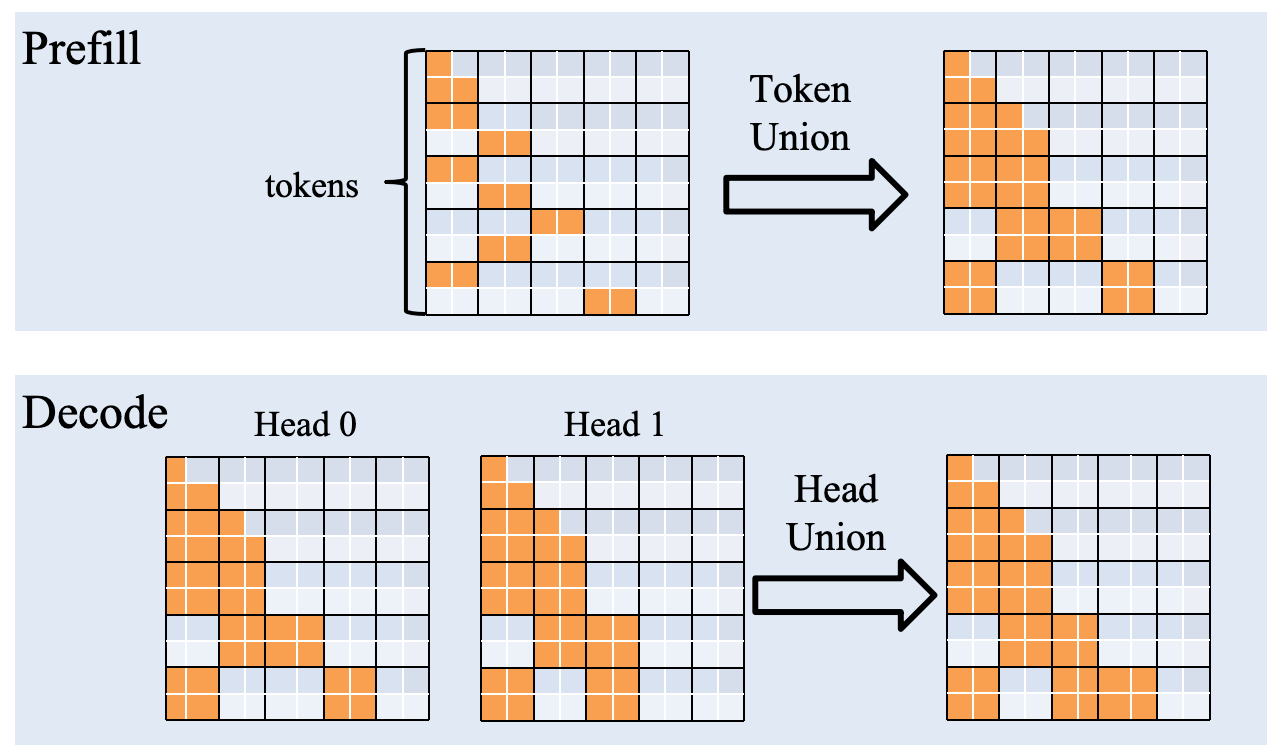
To optimize performance in both the prefill and decode stages, we design a special joint strategy to adapt to their respective characteristics:
- Prefill Token Union: We observe that adjacent query tokens tend to select similar key blocks. Leveraging this locality, we take the union of the key blocks selected by consecutive 128 query tokens and jointly compute sparse attention for these tokens.
- Decode Head Union: Given the widespread adoption of GQA in modern models, we find that different heads within the same group often select overlapping key blocks. Thus, we combine the key blocks selected by all query heads within a group into a unified set and jointly calculate sparse attention. This way also reduces memory access overhead and further improves decoding efficiency.
- Top-K Selection: Conventional top-k algorithms based on sorting or direct calls to the cub library introduce significant runtime overhead. To mitigate this, we implemented an approximate top-k selection algorithm using binary search, which significantly reduces latency while maintaining accuracy, ultimately achieving significantly improved performance.
Evaluation
Experiments
We evaluated the precision of full attention and sparse attention on LongBenchV2 and Ruler (with context lengths of 32K, 64K, and 128K).
| Model | Precision | |||||||
| FullAttention | SparseAttention | |||||||
| LongBenchV2 | Ruler | LongBenchV2 | Ruler | |||||
| 32K | 64K | 128K | 32K | 64K | 128K | |||
| ERNIE-4.5-21B-A3B | 31.48 | 76.74 | 56.40 | 25.48 | 31.45 | 75.93 | 55.38 | 25.05 |
| ERNIE-4.5-300B-A47B | 41.02 | 94.70 | 83.56 | 58.18 | 41.05 | 94.50 | 82.32 | 57.85 |
Performance
We selected a subset (longbook_sum_eng) from InfiniteBench as the performance evaluation dataset. For inputs exceeding 128K in length, we truncate the sequence by keeping the first 64K and the last 64K tokens.
| QPS | Decode Speed (token/s) | Time to First token(s) | Time per Output Token(ms) | End-to-End Latency(s) | Mean Input Length |
Mean Output Length | ||
| ERNIE-4.5-21B-A3B | FullAttention | 0.101 | 13.32 | 8.082 | 87.05 | 61.400 | 113182.32 | 627.76 |
| SparseAttention | 0.150(+48%) | 18.12(+36%) | 5.466(-48%) | 66.35(-31%) | 42.157(-46%) | 113182.32 | 590.23 | |
| ERNIE-4.5-300B-A47B | FullAttention | 0.066 | 5.07 | 13.812 | 206.70 | 164.704 | 113182.32 | 725.97 |
| SparseAttention | 0.081(+23%) | 6.75(+33%) | 10.584(-30%) | 154.84(-34%) | 132.745(-24%) | 113182.32 | 748.25 |
Usage
export FD_ATTENTION_BACKEND="PLAS_ATTN"
python -m fastdeploy.entrypoints.openai.api_server
--model baidu/ERNIE-4.5-300B-A47B-Paddle \
--port 8188 \
--tensor-parallel-size 4 \
--quantization wint4 \
--enable-chunked-prefill \
--max-num-batched-tokens 8192 \
--max-model-len 131072 \
--max-num-seqs 32 \
--plas-attention-config '{"plas_encoder_top_k_left": 50, "plas_encoder_top_k_right": 60, "plas_decoder_top_k_left": 100, "plas_decoder_top_k_right": 120}'
Note: If sparse attention is enabled, the system will automatically load the MLP weights from plas_attention_mlp_weight.safetensors in the weight directory. If the MLP weight file is not found, mean pooling will be applied to the key representations.
Parameter Description:
- Setting
FD_ATTENTION_BACKEND="PLAS_ATTN"enables PLAS sparse attention. plas_encoder_top_k_left=50, plas_encoder_top_k_right=60indicates that the range of top-k is between 50 and 60 when the encoder is sparse.plas_decoder_top_k_left=100, plas_decoder_top_k_right=120indicates that the range of top-k is between 100 and 120 when the decoder is sparse.